在 TFX 管道中,我們如何利用BulkInferrer?
將BulkInferrer與受過訓練的model或pushed_model. 但是,如果我不想再次訓練模型,而是希望使用以前訓練過的model或pushed_model使用BulkInferrerfor 批量推理(有點像與 一起使用BulkInferrer),該怎么辦。有可能這樣做嗎?
如果不是,BulkInferrer組件的目的是什么,只是在整個訓練后做一次預測或驗證?
任何建議或意見將不勝感激,謝謝。
uj5u.com熱心網友回復:
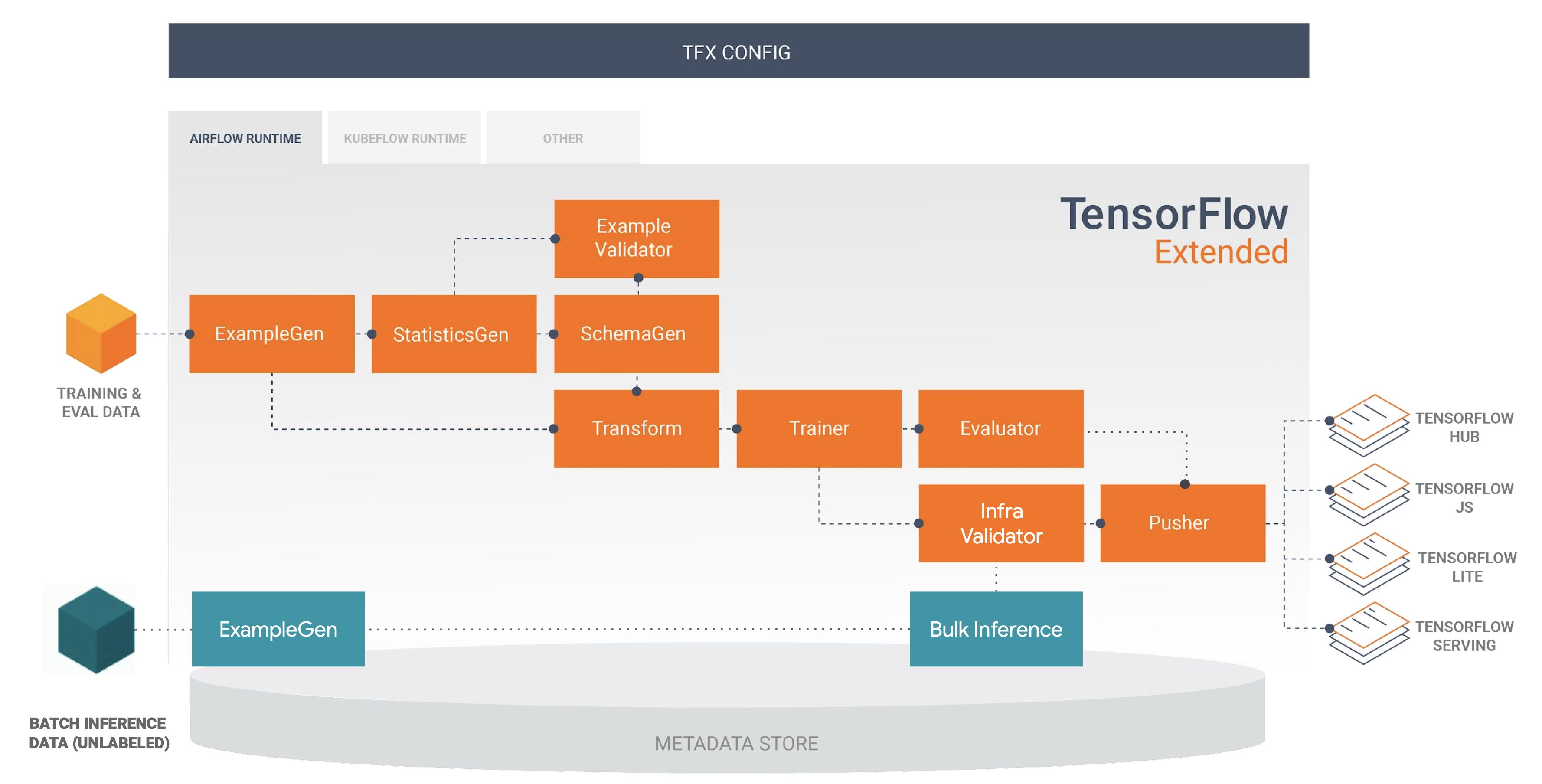 在最近的BEAM 峰會期間,Robert Crowe在推理管道中很好地定位了 BulkInferrer
在最近的BEAM 峰會期間,Robert Crowe在推理管道中很好地定位了 BulkInferrer
以下是為什么有人會使用 BulkInferrer 的用例串列,試圖在 ml-pipelines 而不是 data-pipelines 的情況下接近它:
- 在批處理作業中定期運行,例如每晚運行以推斷前一天收到的資料的分數。例如,當推理延遲很高并且需要離線運行以使用分數填充快取時,或者需要推理大量實體時。
- 當推斷結果不期望直接回傳到推斷請求(即實時)但可以異步執行時。例如,在新模型發布之前對其進行影子測驗。
- 以事件驅動的方式。例如,在推斷批量資料并檢測到模型漂移時觸發模型重新訓練。
- 用于成本優化。例如,在低吞吐量模型/服務上,cpu/gpu 實體的空閑時間可能很長。
要在您的 ML 管道中執行此操作而不重新訓練您的模型,您可以在管道的末尾確實包含 BulkInferrer,并在輸入和配置未更改的情況下重用之前運行的結果。這是由 Kubeflow 管道上的 Argo 和 Tekton 作業流管理器實作的,因為他們實作了 TFX,請參閱步驟快取。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/346302.html