我正在學習神經網路,并嘗試使用 GPU。我正在使用:
- 蟒蛇 3.8
- 張量流-GPU 2.6.0
- PyCharm
- PyCharm 的 Jupiter 插件
- 顯卡 NVIDIA 3080 TI - 12 Gb
我已經安裝了 CUDA 11.4(和其他幾個)和 CudNN-v8.2.4.15
我的起始代碼很平常:
import os
os.environ['TF_FORCE_GPU_ALLOW_GROWTH'] = 'true'
import pandas as pd
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten, Conv1D
from tensorflow.keras.preprocessing.sequence import TimeseriesGenerator
from sklearn.preprocessing import MinMaxScaler, OneHotEncoder
問題是,當我開始學習 NN 時,我在任務管理器中檢查資源,它看起來很奇怪,就像它使用的是 CPU 而不是 GPU。有截圖(對不起俄語):
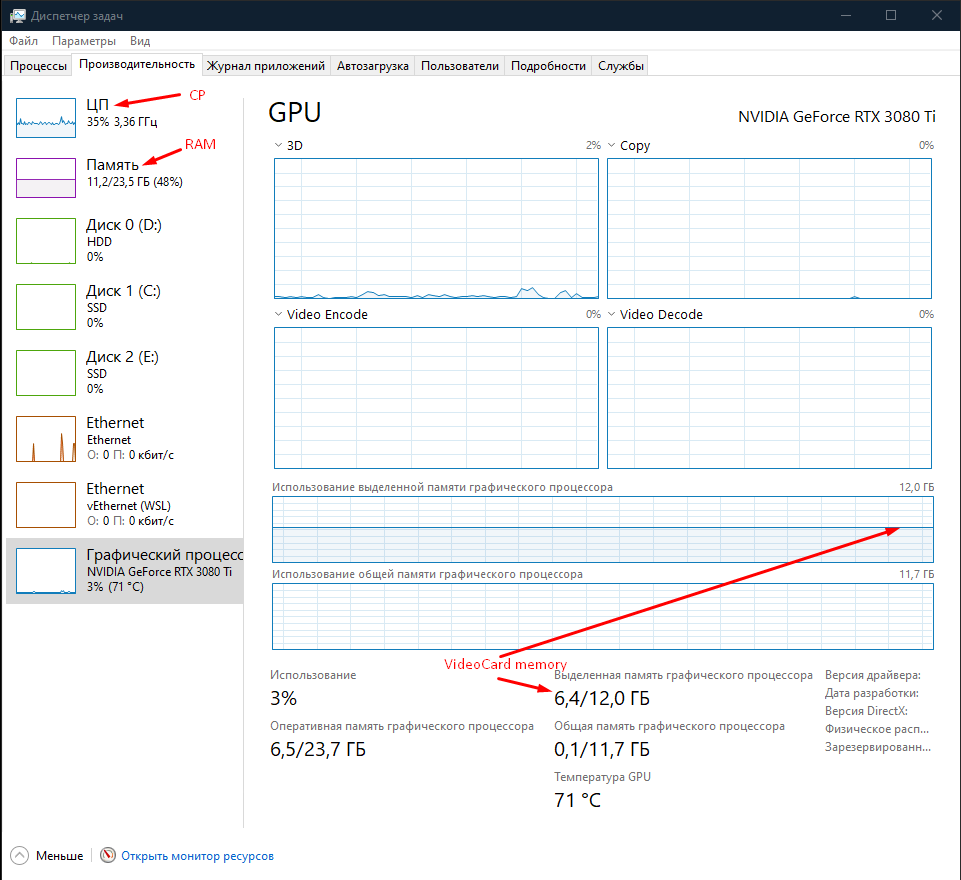
所以當我啟動這個程序時,CP 使用率從 5% 增長到 40%,顯卡記憶體從 2GB 增長到 6GB。
感覺就像是在使用顯卡記憶體,但使用 CPU 進行計算。是否可以?
UPD:木星日志:
"E:\Program Files\JetBrains\PyCharm 2020.3\bin\runnerw.exe" C:\Users\levsh\AppData\Local\Programs\Python\Python38\python.exe -m jupyter notebook --no-browser --notebook-dir=C:/Users/levsh/PycharmProjects/ipynb
[W 2021-11-01 02:53:42.606 LabApp] 'notebook_dir' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2021-11-01 02:53:42.607 LabApp] 'notebook_dir' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[W 2021-11-01 02:53:42.607 LabApp] 'notebook_dir' has moved from NotebookApp to ServerApp. This config will be passed to ServerApp. Be sure to update your config before our next release.
[I 2021-11-01 02:53:42.614 LabApp] JupyterLab extension loaded from c:\users\levsh\appdata\local\programs\python\python38\lib\site-packages\jupyterlab
[I 2021-11-01 02:53:42.614 LabApp] JupyterLab application directory is C:\Users\levsh\AppData\Local\Programs\Python\Python38\share\jupyter\lab
[I 02:53:42.620 NotebookApp] Serving notebooks from local directory: C:/Users/levsh/PycharmProjects/ipynb
[I 02:53:42.620 NotebookApp] Jupyter Notebook 6.4.3 is running at:
[I 02:53:42.620 NotebookApp] http://localhost:8888/?token=a34f13cb67f5cf89bff0a8b8242b69a8727197a98ddb298f
[I 02:53:42.620 NotebookApp] or http://127.0.0.1:8888/?token=a34f13cb67f5cf89bff0a8b8242b69a8727197a98ddb298f
[I 02:53:42.620 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 02:53:42.625 NotebookApp]
To access the notebook, open this file in a browser:
file:///C:/Users/levsh/AppData/Roaming/jupyter/runtime/nbserver-9860-open.html
Or copy and paste one of these URLs:
http://localhost:8888/?token=a34f13cb67f5cf89bff0a8b8242b69a8727197a98ddb298f
or http://127.0.0.1:8888/?token=a34f13cb67f5cf89bff0a8b8242b69a8727197a98ddb298f
[I 02:53:42.626 NotebookApp] 302 GET /api/kernelspecs/ (127.0.0.1) 0.000000ms
[I 02:53:42.694 NotebookApp] Kernel started: 036ed1a8-7e7e-49bb-8c86-3efcfb4b993c, name: python3
[W 02:53:42.703 NotebookApp] No session ID specified
2021-11-01 02:53:49.739123: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX AVX2
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-11-01 02:53:50.367361: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.
2021-11-01 02:53:50.367428: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9440 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3080 Ti, pci bus id: 0000:1f:00.0, compute capability: 8.6
2021-11-01 02:53:50.526516: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:185] None of the MLIR Optimization Passes are enabled (registered 2)
2021-11-01 02:53:52.226233: I tensorflow/stream_executor/cuda/cuda_dnn.cc:369] Loaded cuDNN version 8204
2021-11-01 02:53:55.133752: I tensorflow/stream_executor/cuda/cuda_blas.cc:1760] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
UPD2:更新 TYZ 評論 - 不,不是。
tf.debugging.set_log_device_placement(True)
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
# Num GPUs Available: 1
tf.config.list_physical_devices('GPU')
# [PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
sess = tf.compat.v1.Session(config=tf.compat.v1.ConfigProto(log_device_placement=True))
# Device mapping:
# /job:localhost/replica:0/task:0/device:GPU:0 -> device: 0, name: NVIDIA GeForce RTX 3080 Ti, pci bus id: 0000:1f:00.0, compute capability: 8.6
在日志中它看起來也不錯:
2021-11-01 04:34:49.606386: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /device:GPU:0 with 9440 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3080 Ti, pci bus id: 0000:1f:00.0, compute capability: 8.6
2021-11-01 04:36:58.513741: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1510] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9440 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3080 Ti, pci bus id: 0000:1f:00.0, compute capability: 8.6
uj5u.com熱心網友回復:
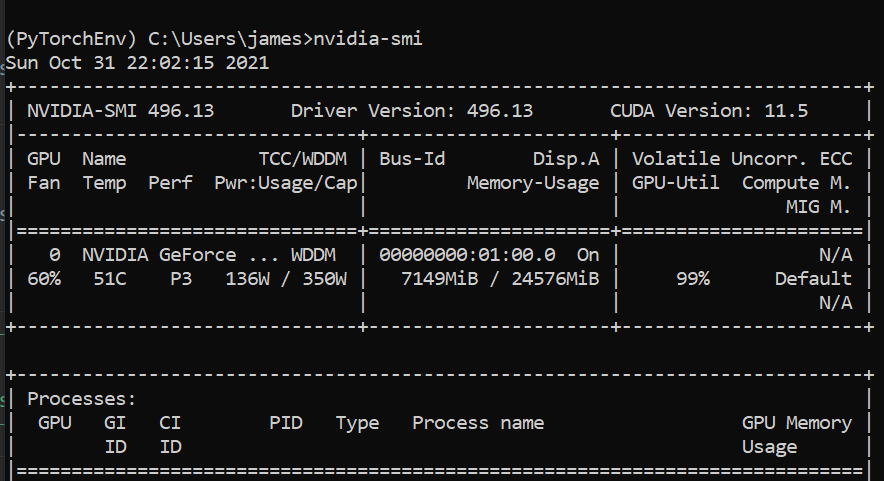
在程式運行時檢查您的 nvidia-smi(nvidia 系統管理界面),尋找 Volatile GPU-util。 任務管理器不能很好地指示 GPU 使用情況(也不是非常準確地使用其他資源,如 RAM 和臨時檔案 imo...)。3080 Ti 的 GPU 溫度為 71 度這一事實表明肯定使用了 GPU(除非其他行程正在使用它)
例如,我現在正在使用 RTX 3090 進行訓練,我的命令列 smi 輸出如下所示(截斷螢屏截圖中的行程):
但是我的任務管理器看起來像(注意 gpu 使用情況):
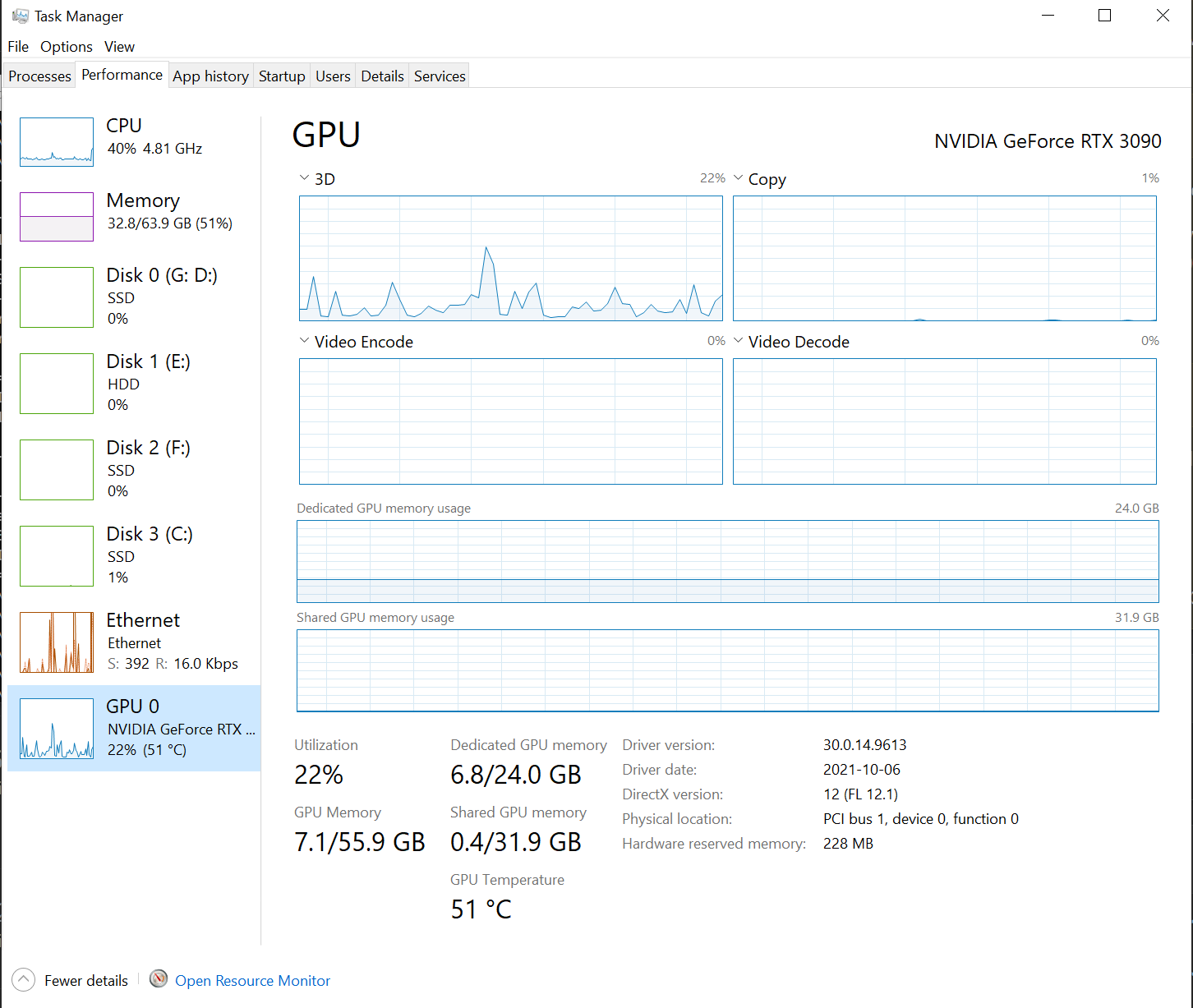
現在,如果您有某種 I/O 瓶頸,即從 CPU 加載張量花費的時間太長,因此 GPU 處于空閑狀態,這是一個不同的問題,可以通過分析和其他工具來解決,以確保加載工藝得到優化。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/346304.html