我成功地在我的機器上安裝了 Spark 和 Pyspark,添加了路徑變數等,但一直面臨匯入問題。
這是代碼:
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.config("spark.hadoop.hive.exec.dynamic.partition", "true") \
.config("spark.hadoop.hive.exec.dynamic.partition.mode", "nonstrict") \
.enableHiveSupport() \
.getOrCreate()
這是錯誤訊息:
"C:\...\Desktop\Clube\venv\Scripts\python.exe" "C:.../Desktop/Clube/services/ce_modelo_analise.py"
Traceback (most recent call last):
File "C:\...\Desktop\Clube\services\ce_modelo_analise.py", line 1, in <module>
from pyspark.sql import SparkSession
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\__init__.py", line 51, in <module>
from pyspark.context import SparkContext
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\context.py", line 31, in <module>
from pyspark import accumulators
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\accumulators.py", line 97, in <module>
from pyspark.serializers import read_int, PickleSerializer
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\serializers.py", line 71, in <module>
from pyspark import cloudpickle
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 145, in <module>
_cell_set_template_code = _make_cell_set_template_code()
File "C:\Spark\spark-2.4.0-bin-hadoop2.7\python\pyspark\cloudpickle.py", line 126, in _make_cell_set_template_code
return types.CodeType(
TypeError: 'bytes' object cannot be interpreted as an integer
如果我洗掉匯入行,這些問題就會消失。正如我之前所說,我的路徑變數已設定:
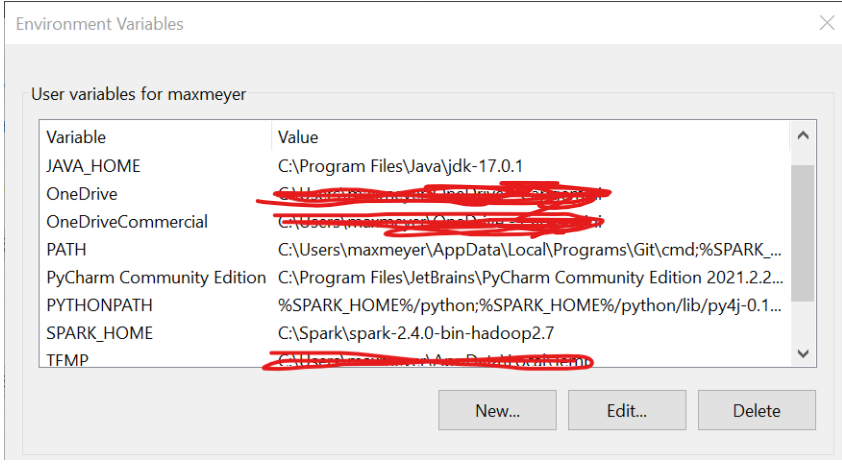
和
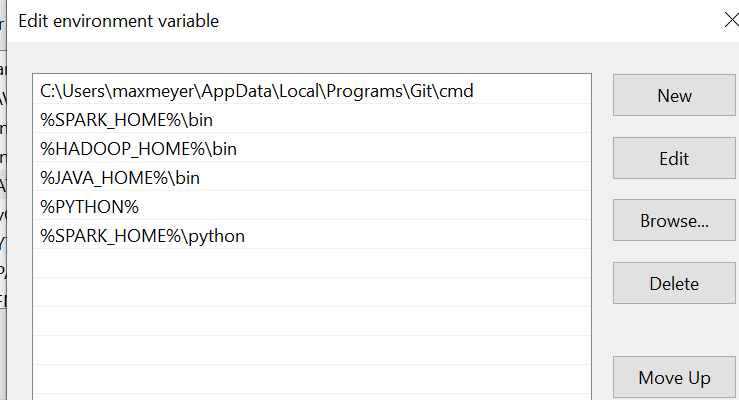
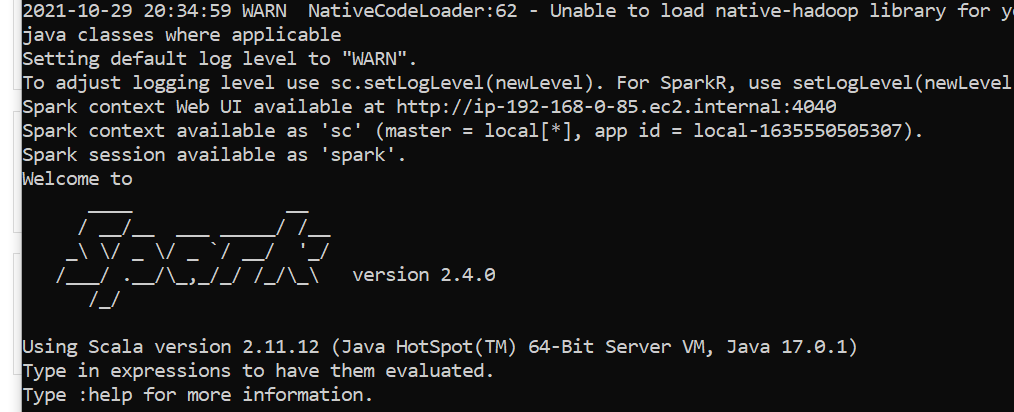
此外,Spark 在 cmd 中運行正常:
uj5u.com熱心網友回復:
更深入我發現了問題:我在 2.4 版中使用 Spark,它適用于 Python 3.7 tops。
當我使用 Python 3.10 時,問題發生了。
因此,如果您遇到同樣的問題,請嘗試更改您的版本。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/347531.html
下一篇:我想回圈顯示串列項的索引