我有一個 .csv 檔案,其中顯示了 100 行資料
“吉姆 1234”
“山姆 1235”
《瑪麗 1236》
“約翰 1237”
我想要實作的是將名稱中的數字拆分為 python 中的 2 列
編輯*
使用,
import pandas as pd
df = pd.read_csv('test.csv', sep='\s ')
df.to_csv('result.csv', index=False)
我設法讓它在excel中像這樣顯示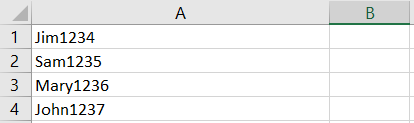
但是,這些數字仍然沒有像我預期的那樣出現在 B 列中。
uj5u.com熱心網友回復:
您的資料只有一列和一個制表符分隔符:
pd.read_csv('test.csv', quoting=1, header=None, squeeze=True) \
.str.split('\t', expand=True) \
.to_csv('result.csv', index=False, header=False)
uj5u.com熱心網友回復:
Pandas 非常易于使用:
import pandas as pd
df = pd.read_csv('test.csv', sep='\s ')
df.to_csv('result.csv', index=False)
如果您的資料包含",則以下代碼應該有效:
import pandas as pd
df = pd.read_csv('test.csv', names=['c1'])
df[['name', 'number']] = df['c1'].str.extract(pat = '"(.*) (.*)"')
df.to_csv('result.csv', columns= ['name', 'number'], index=False)
uj5u.com熱心網友回復:
很簡單的方法,
data=pd.DataFrame(['Jim1234','Sam4546'])
data[0].str.split('(\d )', expand=True)
uj5u.com熱心網友回復:
如果您的檔案類似于下圖,那么下一個代碼將適用于csv 檔案內容
import pandas as pd
df = pd.read_csv('a.csv', header=None, delimiter='\s')
df
代碼執行
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/349621.html