我有以下 Pyspark 資料框:
df = spark.sql("select unhex('0A54C9E024AA62F9EF8BE39231782F9240B51CFB82D1CF7586F734EE07B51086') as db_key")
如您所見,它只有一列“db_key”,只有一個值:unhex對這個 token執行操作的結果0A54C9E024AA62F9EF8BE39231782F9240B51CFB82D1CF7586F734EE07B51086。如果我display在前一個資料幀上執行,我會得到以下結果:
display(df)
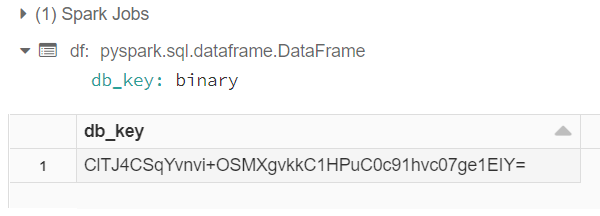
但是如果我執行show()我得到這個結果:
df.show()

我想獲得與我獲得的相同的字串,display但使用show(). 我試過這樣鑄造,但結果不是我想要的:
df = spark.sql("select cast(unhex('0A54C9E024AA62F9EF8BE39231782F9240B51CFB82D1CF7586F734EE07B51086') AS STRING) as db_key")
df.show()

我能做什么?
uj5u.com熱心網友回復:
當您看到=末尾的(等號)符號時,它可能與 base64 相關。幸運的是,base64Spark 中有一個內置函式:
from pyspark.sql import functions as F
df.withColumn("db_key_str", F.base64(F.col("db_key"))).show()
-------------------- --------------------
| db_key| db_key_str|
-------------------- --------------------
|[0A 54 C9 E0 24 A...|ClTJ4CSqYvnvi OSM...|
-------------------- --------------------
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/353013.html