我有“日期”、“小時”、“天”、“作業日”、“值”的時間序列資料。我想以一種方式對資料進行分組,它為我提供每個作業日(星期一、星期二等)的均值圖,但以某種方式計算某一天的均值。例如,在星期一的情節中,平均值應該是資料測驗中所有星期一的平均值。
資料:
structure(list(Date = structure(c(1482087600, 1482084000, 1482080400,
1482076800, 1482073200, 1482069600, 1482066000, 1482062400, 1482058800,
1482055200, 1482051600, 1482048000, 1482044400, 1482040800, 1482037200,
1482033600, 1482030000, 1482026400, 1482022800, 1482019200, 1482015600,
1482012000, 1482008400, 1482004800, 1482001200, 1481997600, 1481994000,
1481990400, 1481986800, 1481983200, 1481979600, 1481976000, 1481972400,
1481968800, 1481965200, 1481961600, 1481958000, 1481954400, 1481950800,
1481947200, 1481943600, 1481940000, 1481936400, 1481932800, 1481929200,
1481925600, 1481922000, 1481918400), class = c("POSIXct", "POSIXt"
), tzone = ""), hour = c(23L, 22L, 21L, 20L, 19L, 18L, 17L, 16L,
15L, 14L, 13L, 12L, 11L, 10L, 9L, 8L, 7L, 6L, 5L, 4L, 3L, 2L,
1L, 0L, 23L, 22L, 21L, 20L, 19L, 18L, 17L, 16L, 15L, 14L, 13L,
12L, 11L, 10L, 9L, 8L, 7L, 6L, 5L, 4L, 3L, 2L, 1L, 0L), day = c(18L,
18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L,
18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 18L, 17L, 17L, 17L,
17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L,
17L, 17L, 17L, 17L, 17L, 17L, 17L, 17L), week = c(51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51,
51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51, 51), weekdays = c("Sunday",
"Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday",
"Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday",
"Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday", "Sunday",
"Sunday", "Sunday", "Saturday", "Saturday", "Saturday", "Saturday",
"Saturday", "Saturday", "Saturday", "Saturday", "Saturday", "Saturday",
"Saturday", "Saturday", "Saturday", "Saturday", "Saturday", "Saturday",
"Saturday", "Saturday", "Saturday", "Saturday", "Saturday", "Saturday",
"Saturday", "Saturday"), Online_h = c(18L, 20L, 25L, 29L, 31L,
32L, 30L, 23L, 24L, 17L, 15L, 15L, 10L, 9L, 7L, 7L, 9L, 12L,
16L, 16L, 23L, 25L, 25L, 35L, 38L, 44L, 39L, 32L, 28L, 30L, 23L,
22L, 21L, 14L, 13L, 15L, 12L, 6L, 7L, 6L, 7L, 7L, 11L, 14L, 21L,
27L, 29L, 34L)), row.names = c(NA, 48L), class = "data.frame")
我當前的代碼如下所示:
df%>%
group_by(day) %>%
group_by(hour) %>%
mutate(avg_hour = mean(Value)) %>%
ggplot(aes(x=hour, y=avg_hour))
geom_line()
ylab("Available drivers")
xlab("Hours")
facet_wrap(vars(weekdays))
這導致了這個圖表。
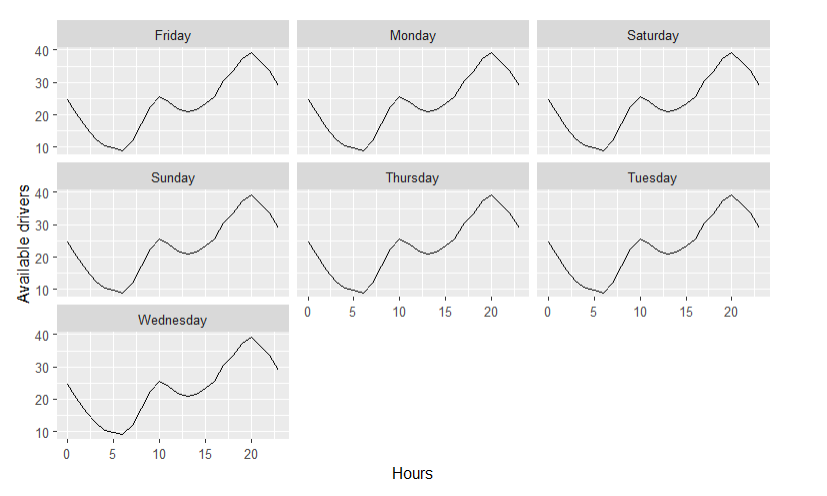
但是,平均線似乎所有天都相同,而如果按每組天計算,則應該有所不同。誰能幫我正確找到每個組的方法并將其顯示在圖上?先感謝您。
uj5u.com熱心網友回復:
你的group_by電話不應該這樣分開。
編輯:我注意到你在資料集中每小時只有一小時,所以不清楚你想找到......的平均值。
library(tidyverse)
df %>%
group_by(weekdays, hour) %>%
mutate(avg_drivers_online_per_hour = mean(Online_h)) %>%
group_by(weekdays) %>%
mutate(avg_drivers_online_per_weekday = mean(Online_h)) %>%
ggplot()
geom_line(aes(x=hour, y=avg_drivers_online_per_hour))
geom_segment(aes(x = 0, xend = 24, y = avg_drivers_online_per_weekday, yend = avg_drivers_online_per_weekday), color = "dodgerblue2")
ylab("Available drivers")
xlab("Hours")
facet_wrap(vars(weekdays))
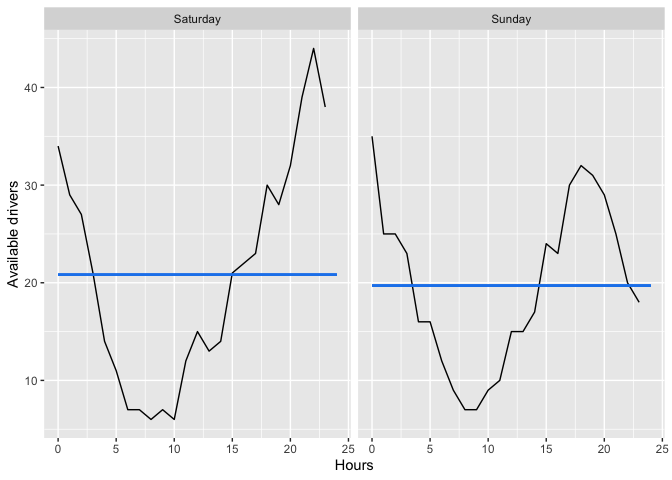
由reprex 包(v2.0.1)于 2021 年 11 月 8 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/354434.html