這是我的原始資料框的一部分,它是調查資料。
structure(list(Ages = c(30L, 30L, 30L, 30L, 30L, 33L, 33L, 27L,
27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 28L, 28L, 25L, 25L, 25L, 25L, 25L, 25L, 25L,
25L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L,
29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 38L,
38L, 38L, NA, NA, NA, NA, 31L, 31L, 31L, 31L, 31L, 31L, 33L,
33L, 33L, 33L, 33L, 33L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L,
29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L,
29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L, 29L,
29L, 29L, 34L, 34L, 34L, 34L, 34L, 34L, 34L, 34L, 34L, 34L, 34L,
34L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L, 36L, 36L,
36L, 36L, 28L, 28L, 28L, 28L, 28L, 28L, 28L, 28L, 28L, 28L, 32L,
32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L,
32L, 32L, 32L, 32L, 32L, 32L, 28L, 28L, 28L, 28L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 27L, 32L, 32L, 32L, 32L, 32L, 32L, 32L, 32L,
32L, 30L, 30L, 30L, 30L, 26L, 27L, 27L, 27L, 27L, 27L, 27L, 27L,
27L, 27L, 27L, 27L, 27L, 27L, 27L, 27L), value = c("Response Eight",
"Response Twelve", "Response Eleven", "Response Three", "Response Two",
"Response Seven", "Response Seven", "Response Eight", "Response Nine",
"Response Twelve", "Response Eleven", "Response Three", "Response Ten",
"Response Two", "Response One", "Response Four", "Response Five",
"Response Six", "Response Eight", "Response Nine", "Response Twelve",
"Response Eleven", "Response Three", "Response Ten", "Response Two",
"Response One", "Response Four", "Response Five", "Response Six",
"Response Eight", "Response Nine", "Response Twelve", "Response Eleven",
"Response Three", "Response Ten", "Response Two", "Response One",
"Response Four", "Response Five", "Response Six", "Response Eight",
"Response Nine", "Response Twelve", "Response Eleven", "Response Three",
"Response Ten", "Response Two", "Response One", "Response Four",
"Response Five", "Response Six", "Response Seven", "Response Seven",
"Response Three", "Response One", "Response Three", "Response One",
"Response Three", "Response One", "Response Three", "Response One",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Twelve", "Response Three", "Response Twelve", "Response Three",
"Response Seven", "Response Seven", "Response Seven", "Response Eight",
"Response Three", "Response Two", "Response One", "Response Ten",
"Response Two", "Response Ten", "Response Two", "Response Ten",
"Response Two", "Response Three", "Response One", "Response Three",
"Response One", "Response Three", "Response One", "Response Eight",
"Response Nine", "Response Three", "Response Ten", "Response Two",
"Response One", "Response Eight", "Response Nine", "Response Three",
"Response Ten", "Response Two", "Response One", "Response Eight",
"Response Nine", "Response Three", "Response Ten", "Response Two",
"Response One", "Response Eight", "Response Nine", "Response Three",
"Response Ten", "Response Two", "Response One", "Response Eight",
"Response Nine", "Response Three", "Response Ten", "Response Two",
"Response One", "Response Eight", "Response Nine", "Response Three",
"Response Ten", "Response Two", "Response One", "Response Eight",
"Response Three", "Response Ten", "Response Eight", "Response Three",
"Response Ten", "Response Eight", "Response Three", "Response Ten",
"Response Eight", "Response Three", "Response Ten", "Response Eight",
"Response Nine", "Response Three", "Response Two", "Response Six",
"Response Eight", "Response Nine", "Response Three", "Response Two",
"Response Six", "Response Eight", "Response Nine", "Response Three",
"Response Two", "Response Six", "Response Twelve", "Response One",
"Response Twelve", "Response One", "Response Twelve", "Response One",
"Response Twelve", "Response One", "Response Seven", "Response Seven",
"Response Seven", "Response Seven", "Response Eight", "Response Nine",
"Response Twelve", "Response Eleven", "Response Ten", "Response Two",
"Response One", "Response Four", "Response Five", "Response Six",
"Response Eight", "Response Nine", "Response Ten", "Response One",
"Response Eight", "Response Nine", "Response Ten", "Response One",
"Response Eight", "Response Nine", "Response Ten", "Response One",
"Response Eight", "Response Nine", "Response Ten", "Response One",
"Response Eight", "Response Nine", "Response Ten", "Response One",
"Response Seven", "Response Seven", "Response Seven", "Response Seven",
"Response Eight", "Response Nine", "Response Twelve", "Response Ten",
"Response Eight", "Response Nine", "Response Twelve", "Response Ten",
"Response Eight", "Response Three", "Response Ten", "Response Eight",
"Response Three", "Response Ten", "Response Eight", "Response Three",
"Response Ten", "Response One", "Response One", "Response One",
"Response One", "Response Seven", "Response Eight", "Response Twelve",
"Response Ten", "Response Eight", "Response Twelve", "Response Ten",
"Response Eight", "Response Twelve", "Response Ten", "Response Eight",
"Response Twelve", "Response Ten", "Response Eight", "Response Twelve",
"Response Ten"), n = c(3210L, 4658L, 1271L, 4453L, 2834L, 2526L,
2526L, 3210L, 4098L, 4658L, 1271L, 4453L, 2975L, 2834L, 3833L,
916L, 1221L, 1208L, 3210L, 4098L, 4658L, 1271L, 4453L, 2975L,
2834L, 3833L, 916L, 1221L, 1208L, 3210L, 4098L, 4658L, 1271L,
4453L, 2975L, 2834L, 3833L, 916L, 1221L, 1208L, 3210L, 4098L,
4658L, 1271L, 4453L, 2975L, 2834L, 3833L, 916L, 1221L, 1208L,
2526L, 2526L, 4453L, 3833L, 4453L, 3833L, 4453L, 3833L, 4453L,
3833L, 4658L, 4453L, 4658L, 4453L, 4658L, 4453L, 4658L, 4453L,
4658L, 4453L, 4658L, 4453L, 4658L, 4453L, 4658L, 4453L, 4658L,
4453L, 4658L, 4453L, 4658L, 4453L, 4658L, 4453L, 2526L, 2526L,
2526L, 3210L, 4453L, 2834L, 3833L, 2975L, 2834L, 2975L, 2834L,
2975L, 2834L, 4453L, 3833L, 4453L, 3833L, 4453L, 3833L, 3210L,
4098L, 4453L, 2975L, 2834L, 3833L, 3210L, 4098L, 4453L, 2975L,
2834L, 3833L, 3210L, 4098L, 4453L, 2975L, 2834L, 3833L, 3210L,
4098L, 4453L, 2975L, 2834L, 3833L, 3210L, 4098L, 4453L, 2975L,
2834L, 3833L, 3210L, 4098L, 4453L, 2975L, 2834L, 3833L, 3210L,
4453L, 2975L, 3210L, 4453L, 2975L, 3210L, 4453L, 2975L, 3210L,
4453L, 2975L, 3210L, 4098L, 4453L, 2834L, 1208L, 3210L, 4098L,
4453L, 2834L, 1208L, 3210L, 4098L, 4453L, 2834L, 1208L, 4658L,
3833L, 4658L, 3833L, 4658L, 3833L, 4658L, 3833L, 2526L, 2526L,
2526L, 2526L, 3210L, 4098L, 4658L, 1271L, 2975L, 2834L, 3833L,
916L, 1221L, 1208L, 3210L, 4098L, 2975L, 3833L, 3210L, 4098L,
2975L, 3833L, 3210L, 4098L, 2975L, 3833L, 3210L, 4098L, 2975L,
3833L, 3210L, 4098L, 2975L, 3833L, 2526L, 2526L, 2526L, 2526L,
3210L, 4098L, 4658L, 2975L, 3210L, 4098L, 4658L, 2975L, 3210L,
4453L, 2975L, 3210L, 4453L, 2975L, 3210L, 4453L, 2975L, 3833L,
3833L, 3833L, 3833L, 2526L, 3210L, 4658L, 2975L, 3210L, 4658L,
2975L, 3210L, 4658L, 2975L, 3210L, 4658L, 2975L, 3210L, 4658L,
2975L)), row.names = c(NA, -250L), class = c("tbl_df", "tbl",
"data.frame"))
然后我創建一個新的資料框,它是原始資料框中每個值/回應的中位年齡的自舉置信區間。我使用 infer 包來創建 ci。這是資料框的代碼和 dput。
bootstrapped_ci_df <- data_frame_responses %>%
split(.$value) %>%
map_df(~.x %>%
specify(response = Ages) %>%
generate(reps = 1000, type = 'bootstrap') %>%
calculate(stat = 'median') %>%
get_ci(level = 0.99999), .id = 'value')
structure(list(value = c("Response One", "Response Two", "Response Three",
"Response Four", "Response Five", "Response Six", "Response Seven",
"Response Eight", "Response Nine", "Response Ten", "Response Eleven",
"Response Twelve"), lower_ci = c(28.5, 28, 29, 28, 30, 29, 31,
29, 28, 29, 28, 28), upper_ci = c(29, 29, 30, 29, 30.995005,
30, 31.5, 30, 29, 30, 29, 29)), row.names = c(NA, -12L), class = c("tbl_df",
"tbl", "data.frame"))
問題是當我用 ggplot2 繪制這個圖時。
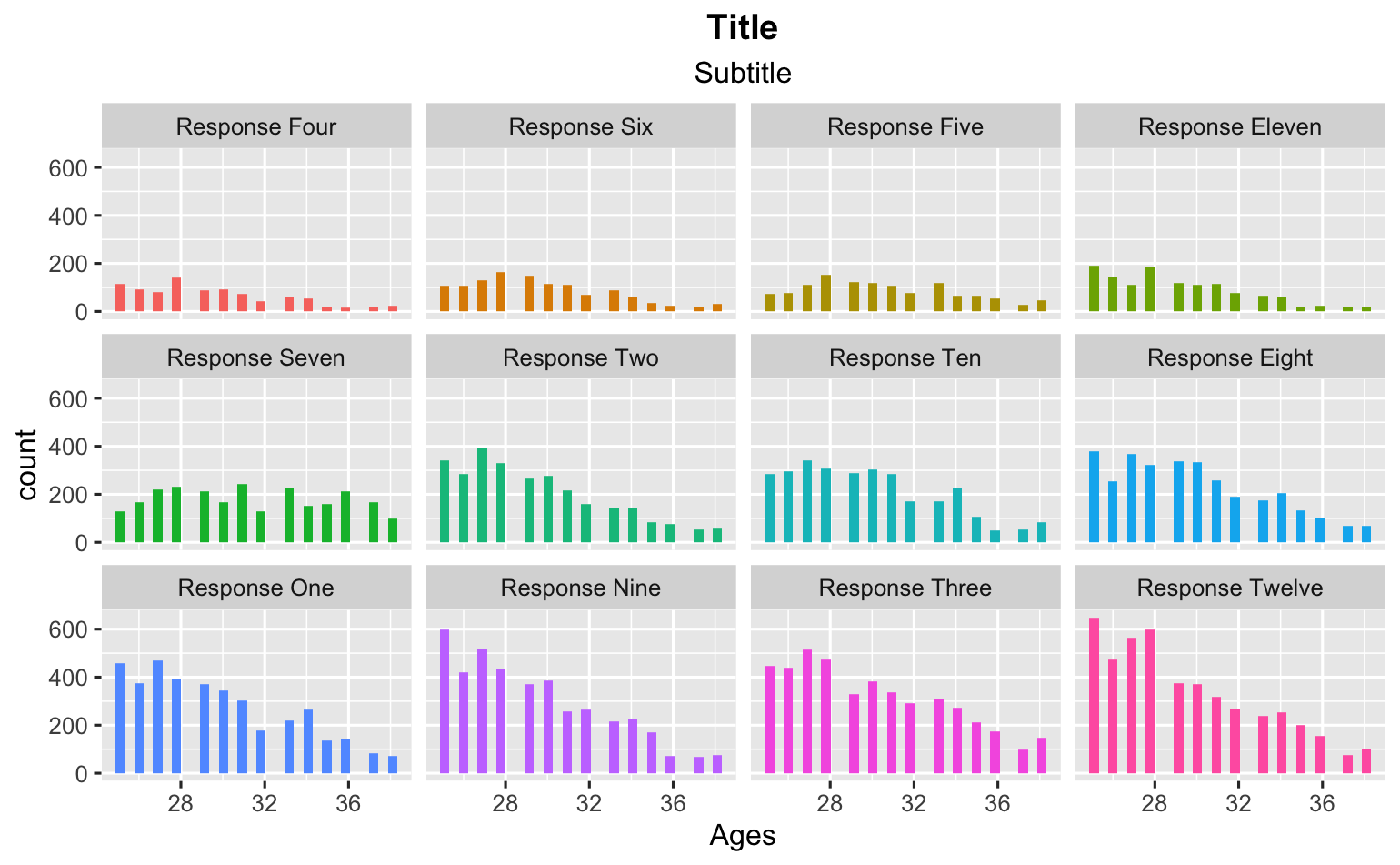
在第一種情況下,我可以創建一個看起來不錯的圖表。我將回應最多的值放在底部。
ggplot(data_frame_responses, aes(x = Ages, fill = fct_reorder(value, n)))
geom_histogram()
facet_wrap(~ fct_reorder(value, n))
theme(legend.position="none")
labs(title = "Title")
labs(subtitle = "Subtitle")
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
theme(plot.subtitle = element_text(hjust = 0.5))
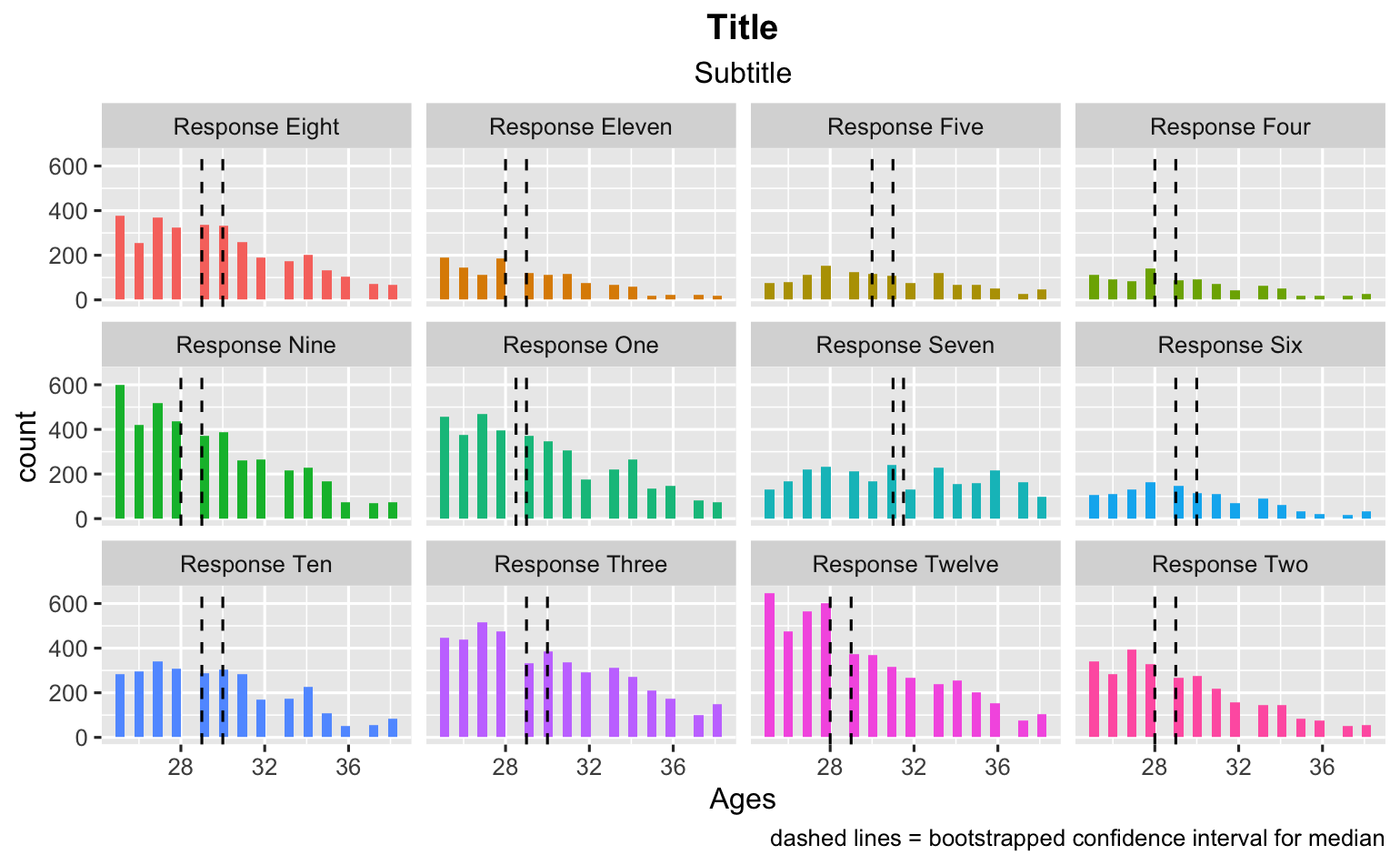
我還可以在資料框上映射置信區間,這看起來也不錯。
ggplot(data_frame_responses, aes(x = Ages, fill = value))
geom_histogram()
facet_wrap(~value)
theme(legend.position="none")
labs(title = "Title")
labs(subtitle = "Subtitle")
geom_vline(mapping = aes(xintercept = lower_ci), bootstrapped_ci_df, linetype = 'dashed')
geom_vline(mapping = aes(xintercept = upper_ci), bootstrapped_ci_df, linetype = 'dashed')
labs(caption = "dashed lines = bootstrapped confidence interval for median")
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
theme(plot.subtitle = element_text(hjust = 0.5))
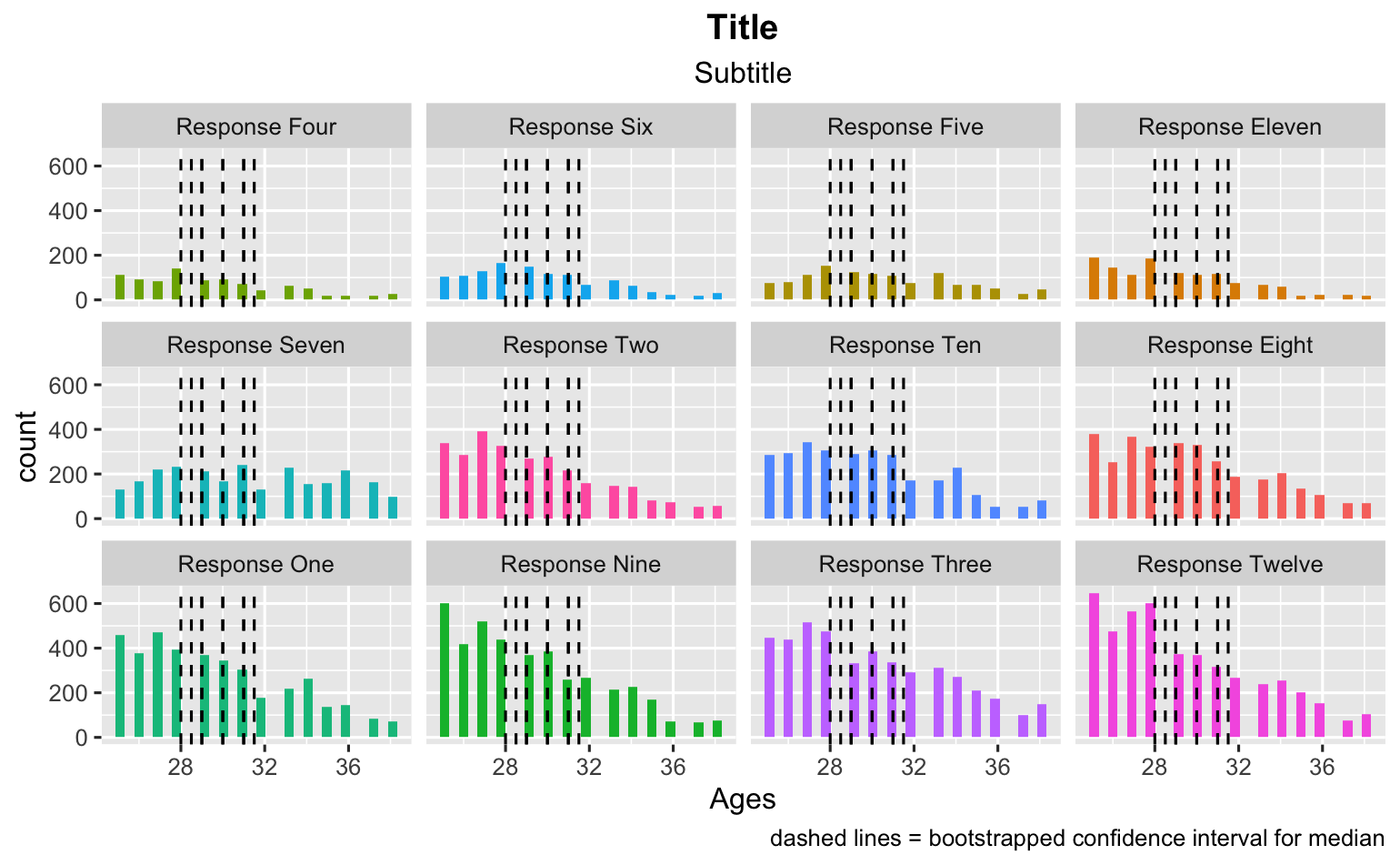
問題是,我不知道如何做到這兩點。我怎樣才能重新排序資料框的方面并保持映射完整?這是我的嘗試,您可以看到它是如何出錯的。
ggplot(data_frame_responses, aes(x = Ages, fill = value))
geom_histogram()
facet_wrap(~ fct_reorder(value, n))
theme(legend.position="none")
labs(title = "Title")
labs(subtitle = "Subtitle")
geom_vline(mapping = aes(xintercept = lower_ci), bootstrapped_ci_df, linetype = 'dashed')
geom_vline(mapping = aes(xintercept = upper_ci), bootstrapped_ci_df, linetype = 'dashed')
labs(caption = "dashed lines = bootstrapped confidence interval for median")
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
theme(plot.subtitle = element_text(hjust = 0.5))
uj5u.com熱心網友回復:
兩個資料框中的值變數需要一致。在您的代碼中,您更改了一個data_frame_responsesfor geom_histogram,但沒有更改forgeom_vline
更容易更改兩個 data.frames 之前的資料型別ggplot。請注意:我使用不同的資料只是為了回答您的問題。
data_frame_responses <-data_frame_responses %>% mutate(
value = fct_reorder(value, n)
)
bootstrapped_ci_df <-bootstrapped_ci_df %>%
mutate(value = factor(value, levels(data_frame_responses$value)))
ggplot(data_frame_responses, aes(x = Ages, fill = value))
geom_histogram()
facet_wrap(~value)
theme(legend.position="none")
labs(title = "Title")
labs(subtitle = "Subtitle")
geom_vline(mapping = aes(xintercept = lower_ci), bootstrapped_ci_df, linetype = 'dashed')
geom_vline(mapping = aes(xintercept = upper_ci), bootstrapped_ci_df, linetype = 'dashed')
labs(caption = "dashed lines = bootstrapped confidence interval for median")
theme(plot.title = element_text(hjust = 0.5, face = "bold"))
theme(plot.subtitle = element_text(hjust = 0.5))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/354456.html
下一篇:Python-改進正則運算式