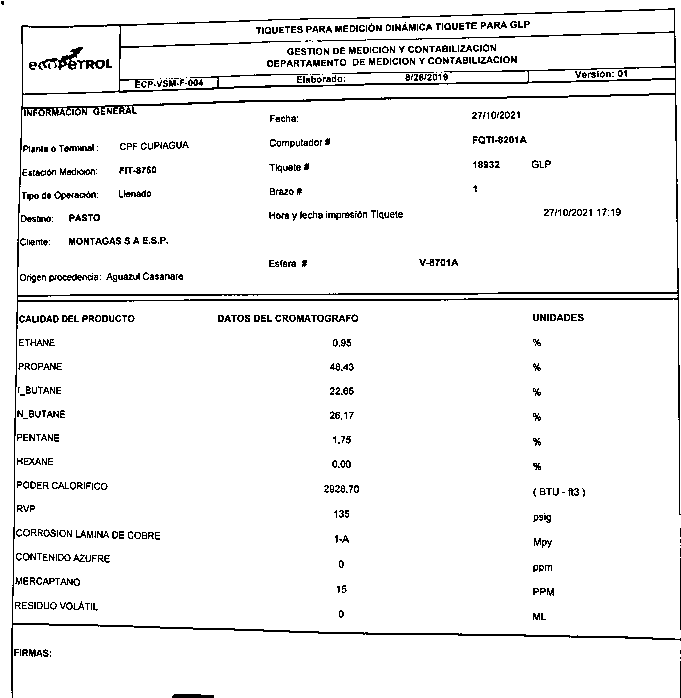
我正在做一個檔案閱讀器,將其中的所有文本決議為谷歌電子表格,這個腳本應該可以節省我的作業時間,問題是二進制影像有很多噪音(文本周圍非常小的點)混淆了pytesseract . 我怎樣才能消除這種噪音?我用來二值化影像的代碼是:
import pytesseract
import cv2
import numpy as np
import os
import re
import argparse
#binarization of images
def binarize(img):
#convert image to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#apply adaptive thresholding
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 11, 2)
#return thresholded image
return thresh
#construct argument parser
parser = argparse.ArgumentParser(description='Binarize image and parse text in image to string')
parser.add_argument('-i', '--image', help='path to image', required=True)
parser.add_argument('-o', '--output', help='path to output file', required=True)
args = parser.parse_args()
# load image
img = cv2.imread(args.image)
#binarization of image
thresh = binarize(img)
#show image
cv2.imshow('image', thresh)
cv2.waitKey(0)
cv2.destroyAllWindows()
#save image
cv2.imwrite(args.output '/imagen3.jpg', thresh)
我想要清理的結果影像是:

如果我應用侵蝕,結果是:

哪個比另一個更糟糕
編輯:原始影像是:
uj5u.com熱心網友回復:
您只需要在 Python/OpenCV 中增加自適應閾值引數。
輸入:

import cv2
# read image
img = cv2.imread("petrol.png")
# convert img to grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# do adaptive threshold on gray image
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 21, 25)
# write results to disk
cv2.imwrite("petrol_threshold.png", thresh)
# display it
cv2.imshow("THRESHOLD", thresh)
cv2.waitKey(0)
結果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/361548.html
標籤:Python opencv 图像处理 超立方体 python-tesseract
下一篇:在OpenCV中移動影像