我有一個具有多個屬性的資料框,有些是重復的。我想根據一列中的最大值選擇行 - 但回傳具有該值的行(不是每列的最大值)。如何??
這是一個示例:
df = pd.DataFrame({'Owner': ['Bob', 'Jane', 'Amy',
'Steve','Kelly'],
'Make': ['Ford', 'Ford', 'Jeep',
'Ford','Jeep'],
'Model': ['Bronco', 'Bronco', 'Wrangler',
'Model T','Wrangler'],
'Max Speed': [80, 150, 69, 45, 72],
'Customer Rating': [90, 50, 91, 75, 99]})
這給了我們:
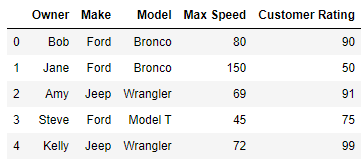
我希望每個品牌/型號都有最大(客戶評級)的行。像這樣:
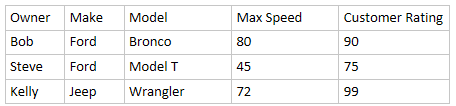
請注意,這與 df.groupby(['Make','Model']).max() 不同
--> 我該怎么做?
uj5u.com熱心網友回復:
您的答案的變體idxmax:
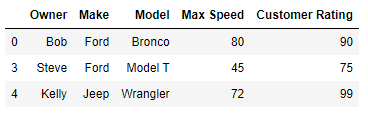
>>> df.loc[df.groupby(['Make', 'Model'])['Customer Rating'].idxmax()]
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99
沒有的 另一種解決方案groupby:
>>> df.sort_values('Customer Rating') \
.drop_duplicates(['Make', 'Model'], keep='last') \
.sort_index()
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99
uj5u.com熱心網友回復:
我找到了答案!如果其他人也沒有認出它,我會留下這個問題。
查看這篇文章:
這也很好用:
def using_sort(df):
df = df.sort_values(by=['Customer Rating'], ascending=False, kind='mergesort')
return df.groupby(['Make', 'Model'], as_index=False).first()
uj5u.com熱心網友回復:
在每個所需組中傳播最大值并過濾掉那些等于客戶評級的
df[df['Customer Rating']==df.groupby(['Make','Model'])['Customer Rating'].transform('max')]
Owner Make Model Max Speed Customer Rating
0 Bob Ford Bronco 80 90
3 Steve Ford Model T 45 75
4 Kelly Jeep Wrangler 72 99
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/362529.html
上一篇:如何條形圖繪制資料框的每一行