我正在使用這個資料集: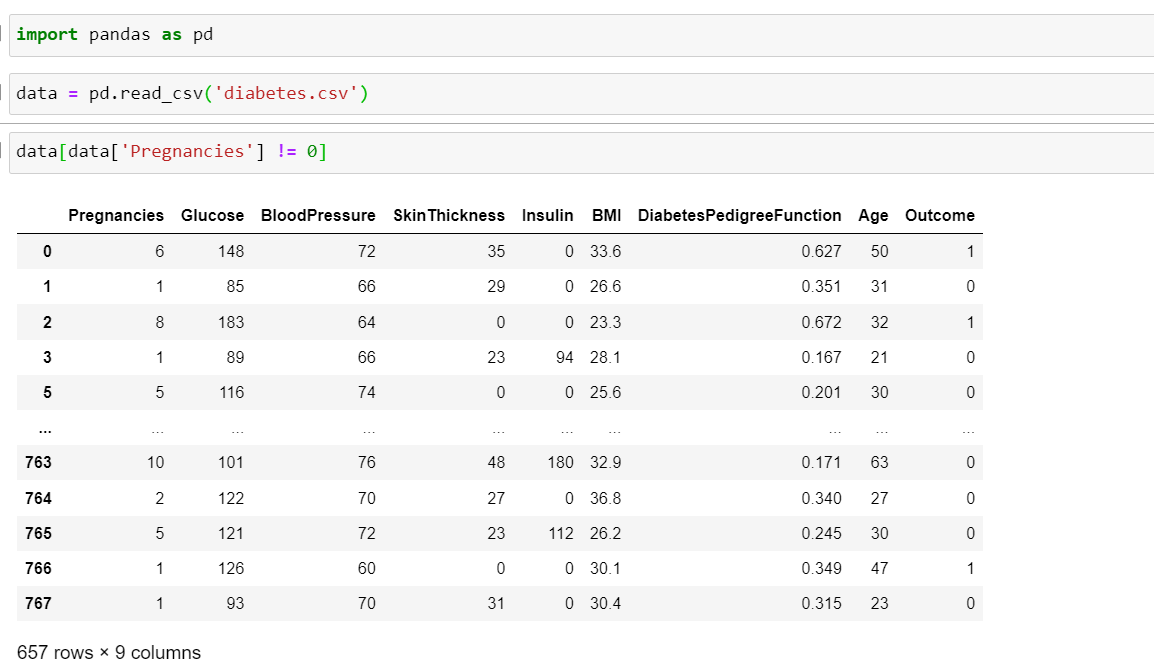
但是,當我嘗試過濾兩列或更多列時,我會得到不同數量的行,具體取決于我是否喜歡這樣:
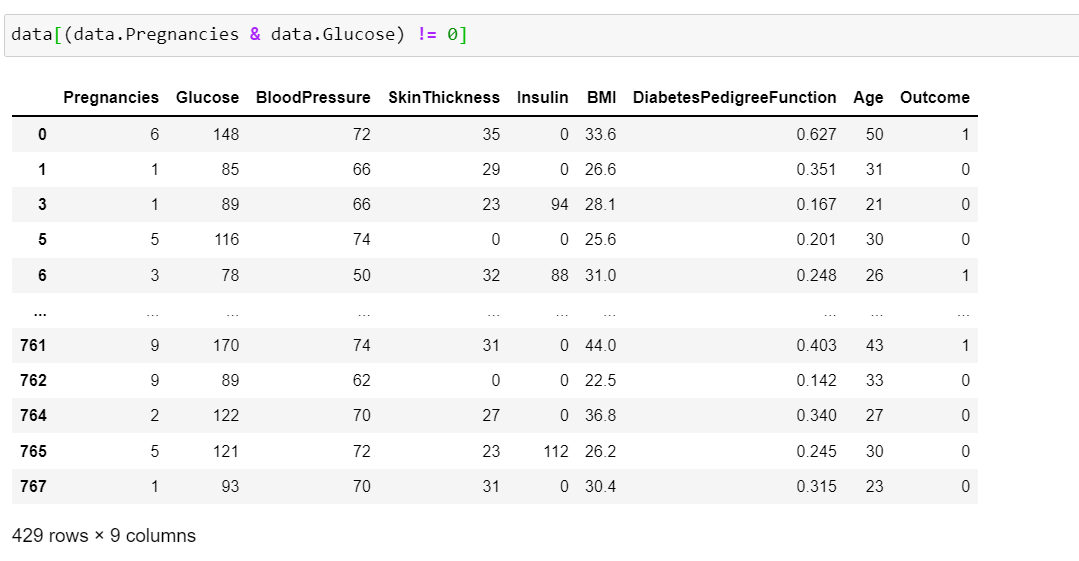
或這個:
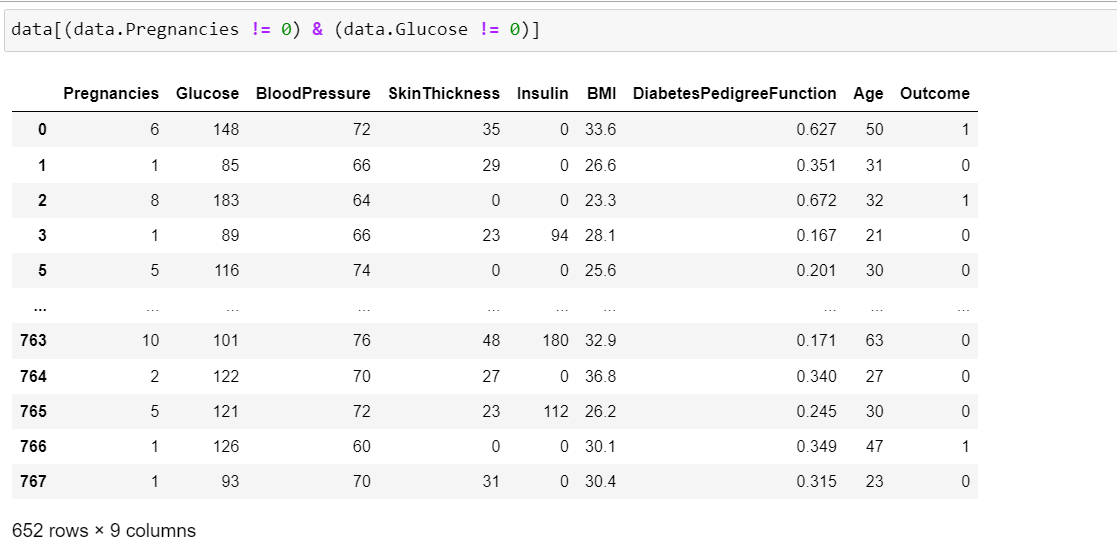
我分別得到 429 行和 652 行。
所以我嘗試過濾iloc:
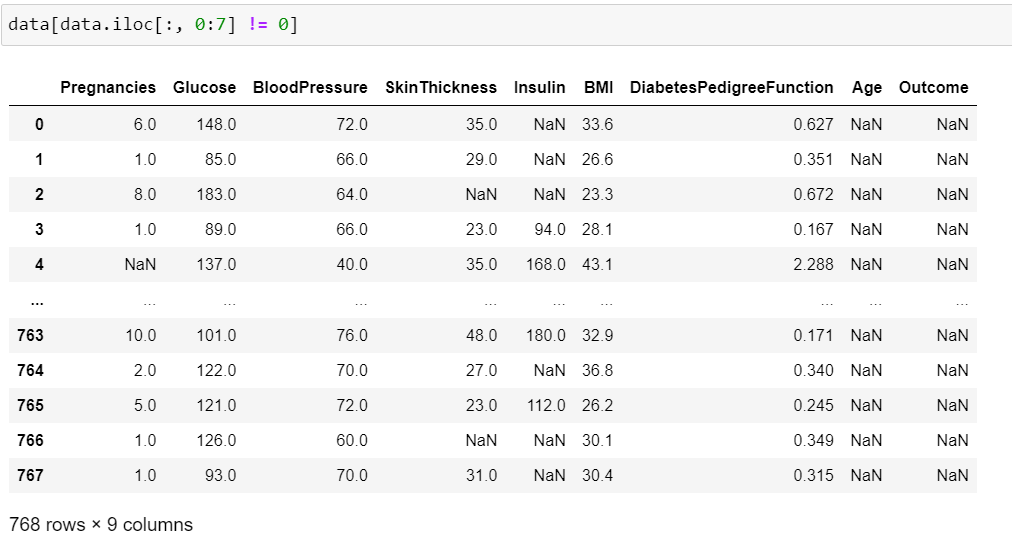
但這只是用 NaN 填充列,但不會洗掉行。它也改變了Outcome我想保持完整的列。似乎這種iloc方法只在一次過濾一列時有效。
有什么方法可以一次過濾 8 列而不是一次過濾一列?
uj5u.com熱心網友回復:
您可以使用apply一次過濾所有列,如果有值則檢查每個列,如果有則0回傳 true。
result = df.drop(["Outcome"], axis=1).apply(lambda x: x == 0 , axis=0).any(1)
df[result]
uj5u.com熱心網友回復:
你可以這樣做:
df[df.loc[:, 0:5] < 10].dropna(how='all', axis=1).dropna()
它的作用是首先創建一個掩碼,選擇前 5 列小于 10 的所有值。然后,它從該掩碼選擇的資料框中選擇所有值。
由于掩碼不會選擇所有列,因此使用該掩碼對資料框進行索引將回傳該掩碼未考慮的列(第 6 列以后)作為純 NaN 值。 .dropna(how='all', axis=1)將洗掉所有為 NaN 的列。
最后,.dropna()將洗掉包含任何 NaN 的所有行,留下所有值與條件匹配(小于 10)的所有行。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/362537.html
上一篇:切片多索引