我有一個如下所示的 DataFrame:
df = Pd.DataFrame({'Correct Prediction (Insert None if none of the predictions are correct)':[1,0,1,4,'NONE',1,0,3,2,'NONE'],
'Subject':['Physics','Maths','Chemistry','Biology','Physics','Physics','Maths','Biology','Chemistry','Maths']})
所以我想獲取所有條目以查看每個主題的 0,1,2,3,4 和 NONE 的百分比。讓我們假設有多少物理是NONE這樣我就可以得到總的問題,這是在NONE和屬于物理,然后通過物理問題的總數劃分。我可以使用下面的代碼很難做到這一點:
df['Subject'].value_counts()
df[(df['Subject'] == 'Physics') & (df['Correct Prediction (Insert None if none of the predictions are correct)'] == position)].shape[0]
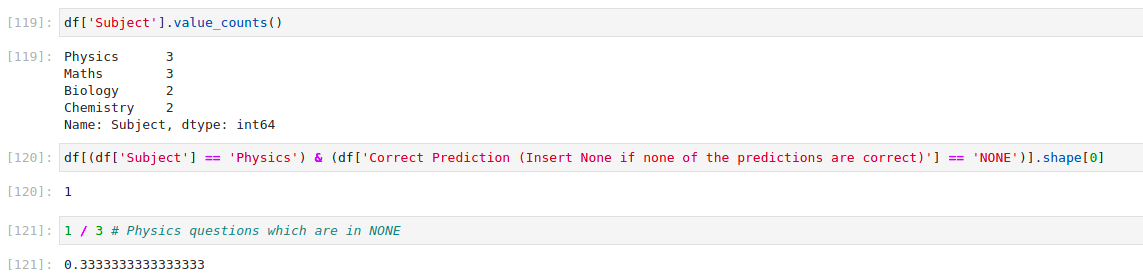
但是,這樣做的簡單和更好的方法是什么?
我試過
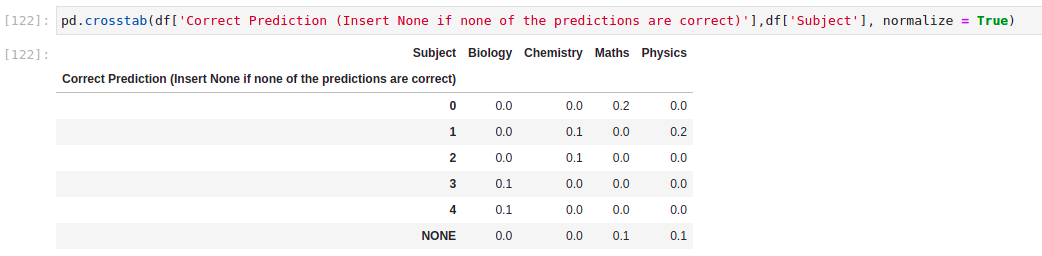
pd.crosstab(df['Correct Prediction (Insert None if none of the predictions are correct)'],df['Subject'], normalize = True)
但它給了我奇怪的值,例如 0.1 而不是 0.333
我可以在回圈中執行此操作:
counts = df['Subject'].value_counts()
for index in counts.index:
print(f"Results for: {index}\n")
total_count = counts[index]
for position in [0,1,2,3,4,'NONE']:
i = df[(df['Subject'] == index) & (df['Correct Prediction (Insert None if none of the predictions are correct)'] == position)].shape[0]
print(f"Position {position} : {round((i / total_count)*100, 2)}%")
print("-"*50,'\n')
uj5u.com熱心網友回復:
請嘗試以下操作:
correct_prediction = pd.Categorical([df['Correct Prediction (Insert None if none of the predictions are correct)'].tolist(), categories=[0,1,2, 3, 'NONE'])
subject = pd.Categorical(df['Subject'].tolist(), categories=['Physics', 'Maths', 'Chemistry', 'Biology'])
pd.crosstab(correct_prediction, subject, normalize='columns')
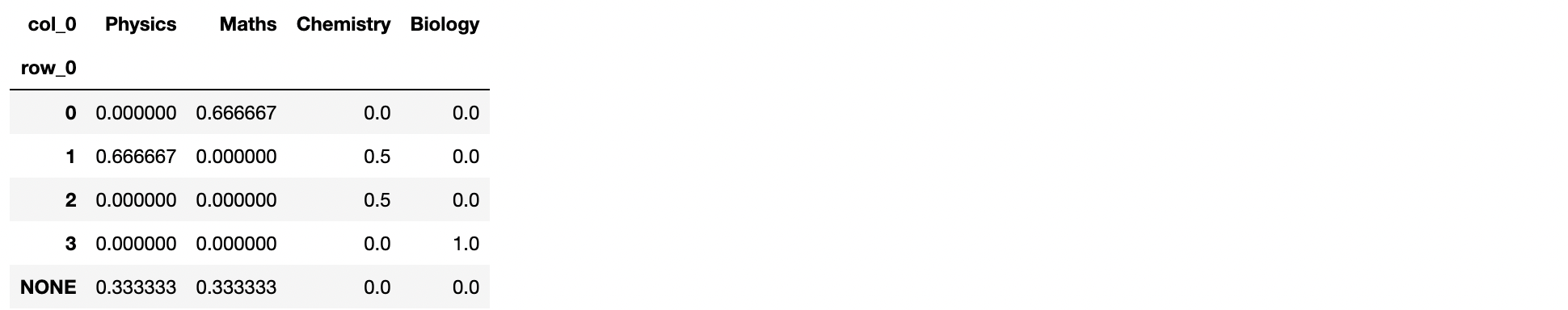
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/362552.html
標籤:Python 熊猫 数据框 麻木的 pandas-groupby
上一篇:python如何使用串列呼叫類