我有一個如下所示的檔案,但是您應該注意,實際上該檔案包含超過 100.000 條記錄。
blue black red 250
red black blue 140
black yellow purple 100
orange blue blue 140
blue black red 250
red black blue 140
black yellow purple 700
orange blue blue 200
我還有一個包含以下值的串列 my_list = ['140', '700', '800']
現在我想要以下內容:
- 如果
my_list檔案中出現的值之一,row[3]我想將整個記錄附加到新串列中。 - 如果我的串列中的一個值沒有出現在檔案行 [3] 中,我想附加值本身,其余的值應該是
'unknown'.
這是我的代碼:
new_list = []
with open(my_file, 'r') as input:
reader = csv.reader(input, delimiter = '\t')
row3_list = []
for row in reader:
row3_list.append(row[3])
for my_number in my_list :
if my_number in row3_list :
new_list.append(row)
elif my_number not in row3_list :
new_list.append(['Unknown', 'Unkown', 'Unkown', row[3]])
這是我想要的輸出:
red black blue 140
orange blue blue 140
red black blue 140
black yellow purple 700
unknown unkown unkown 800
我的問題: 就像我提到的,我的檔案包含大量記錄,可能超過 100.000 。所以上面的方式需要很長時間。我一直在等待輸出大約 15 分鐘,但仍然沒有。
uj5u.com熱心網友回復:
您可以使用 numpy 和 pandas 來提高效率:
import pandas as pd
import numpy as np
# read file to dataframe
df = pd.read_csv('file.txt', delim_whitespace=True, header=None)
# give names to columns for simplicity
df.columns = ['a','b', 'c', 'd']
# our values
my_list = ['140', '700', '800']
my_second_list = ['orange', 'red']
# filter rows that not in my_list
new_df = df[df['d'].isin(my_list) & df['a'].isin(my_second_list)]
# find values in my_list that are not in file
missing = np.setdiff1d(np.asarray(my_list), new_df['d'].unique().astype(str))
# add there rows with unknown
for i in missing:
d = {'a': ['unknown'], 'b': ['unknown'], 'c': ['unknown'], 'd': i}
temp = pd.DataFrame(data=d)
new_df = new_df.append(temp, ignore_index=True)
result = new_df.values.tolist()
給定資料樣本的輸出:
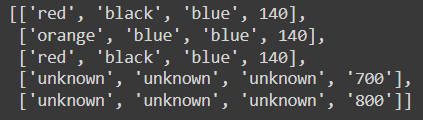
uj5u.com熱心網友回復:
試試這個(你需要安裝熊貓pip install pandas):
import pandas as pd
df = pd.read_csv('myfile.txt', sep='\t', header=None, dtype=str,
names=('0', '1', '2', '3'))
result = df[df['3'].isin(my_list)]
vals = df[~df.index.isin(result.index)]['3']
if len(vals) > 0:
tot = vals.map(int).sum()
result = result.append(
{'0': 'unknown', '1': 'unknown', '2': 'unknown',
'3': vals.map(int).sum()},
ignore_index=True,
)
result = result.values.tolist()
如果你不想使用熊貓,那么我會做這樣的事情:
import bisect
import csv
def elem_in_list(lst, x):
i = bisect.bisect_left(lst, x)
if i != len(lst) and lst[i] == x:
return True
return False
my_list = ['140', '700', '800']
result = []
tot = 0
is_tot_used = False
lst = sorted(list(map(int, my_list)))
with open('myfile.txt') as input:
reader = csv.reader(input, delimiter='\t')
for row in reader:
if elem_in_list(lst, int(row[3])):
result.append(row)
else:
is_tot_used = True
tot = int(row[3])
if is_tot_used:
result.append(['unknown'] * 3 [tot])
如果my_list很大,那么此代碼將比您的代碼快得多。為什么?因為搜索排序串列可以在 O(log(n)) 中完成,而搜索未排序串列可以在 O(n) 中完成。
uj5u.com熱心網友回復:
將您的 csv 檔案作為 Pandas 資料框匯入
import pandas as pd
A = [['blue', 'black', 'red', 250],
['red', 'black', 'blue', 140],
['black', 'yellow', 'purple', 100],
['orange', 'blue' , 'blue', 140],
['blue', 'black', 'red', 250],
['red', 'black' , 'blue' , 140],
['black', 'yellow', 'purple', 700],
['orange', 'blue' , 'blue' , 200]]
df = pd.DataFrame(A,columns=['A','B','C','D'])
df_ = pd.DataFrame(columns=['A','B','C','D'])
my_list = ['140', '700', '800']
for ii in my_list:
temp = df.loc[df['D'].isin([int(ii)])]
if len(temp.index):
df_ = df_.append(temp)
else:
to_append = ['unknown', 'unknown', 'unknown', int(ii)]
df_.loc[len(df_)] = to_append
print(df_)
uj5u.com熱心網友回復:
我認為可以簡化您必須避免第二個 for 回圈的代碼。如果你嘗試這樣的事情,它應該在更合理的時間內完成:
new_list = []
my_file = "some_file.txt"
my_list = ['140', '700', '800']
with open(my_file, 'r') as input:
reader = csv.reader(input, delimiter = '\t')
for row in reader:
if row[3] in my_list:
new_list.append(row)
else:
new_list.append(['Unknown', 'Unkown', 'Unkown', row[3]])
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/364994.html
上一篇:無法將值從輸入傳遞給reactjs中的fromData
下一篇:需要從給定日期中提取季度