我有一個半小時電力資料的時間序列,如下所示:
Date_Time Metered Electricity (MWh)
0 2016-03-27 00:00:00 8.644511
1 2016-03-27 00:30:00 6.808402
2 2016-03-27 01:00:00 6.507068
3 2016-03-27 01:30:00 5.271631
4 2016-03-27 02:00:00 2.313497
... ... ...
58122 2019-06-30 11:30:00 8.051935
58123 2019-06-30 12:00:00 3.520226
58124 2019-06-30 12:30:00 5.093964
我想將所有資料點平均為每半小時時間步長的平均值,最終我可以創建一個圖表,顯示全天產生的平均電力。
我已經設法使用 groupby 對每小時資料執行此操作,效果很好:
mean_hourly = energy_2018.groupby(energy_2018["Date_Time"].dt.hour).mean()
如果我無法弄清楚如何每半小時進行一次分組,我可以使用它,但這意味著我錯過了所有資料的一半。知道如何每半小時使用一次 groupby 以便我可以使用所有資料嗎?
謝謝!
uj5u.com熱心網友回復:
您可以按小時和分鐘進行分組和分組。由于您僅以半小時為間隔記錄資料,因此每小時和每 30 分鐘會得到一個不同的組。
import pandas as pd
df = pd.DataFrame({
'time': ['2016-03-27 00:00:00',
'2016-03-27 00:00:00',
'2016-03-27 00:30:00',
'2016-03-27 01:00:00',
'2016-03-27 01:30:00',
'2019-06-30 11:30:00',
'2019-06-30 12:00:00',
'2019-06-30 12:30:00'],
'electricity': [8.644511,
6.808402,
6.507068,
5.271631,
2.313497,
8.051935,
3.520226,
5.093964]
})
df['time'] = pd.to_datetime(df['time'])
df['minutes'] = df['time'].apply(lambda x: x.minute)
df['hour'] = df['time'].apply(lambda x: x.hour)
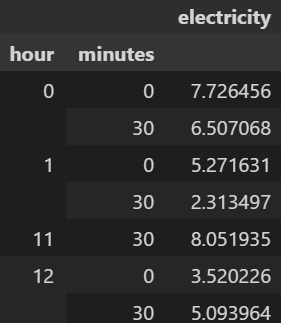
df.groupby(['hour', 'minutes']).mean()
輸出:
編輯:
正如 Quang Hoang 的評論所示,獲得小時和分鐘的更好方法是
df['minutes'] = df['time'].dt.minute
df['hour'] = df['time'].dt.hour
最好使用標準庫中的現有解決方案,以提高可讀性和性能。另一方面,lambda expressions確實提供了一些靈活性,有時非常有用。如果您有興趣,可以在這里閱讀更多內容:
為什么 Python lambdas 很有用?
https://www.code-learner.com/advantages-and-disadvantages-of-lambda-expressions-in-python-and-their-usage-scenarios/
uj5u.com熱心網友回復:
df = pd.read_excel('test.xlsx')
print(df)
輸出:
Date_Time Metered Electricity (MWh)
0 2016-03-27 00:00:00 1
1 2016-03-27 00:29:00 2
2 2016-03-27 00:59:00 3
3 2016-03-27 00:57:00 4
4 2016-03-27 02:00:00 5
然后這樣做:
df.set_index('Date_Time',inplace=True)
df = df.resample("30T").mean().reset_index()
print(df)
輸出:
Date_Time Metered Electricity (MWh)
0 2016-03-27 00:00:00 1.5
1 2016-03-27 00:30:00 3.5
2 2016-03-27 01:00:00 NaN
3 2016-03-27 01:30:00 NaN
4 2016-03-27 02:00:00 5.0
編輯
或者只是這個:
df = df.set_index('Date_Time').resample("30T").mean().reset_index()
uj5u.com熱心網友回復:
energy_2018.groupby(energy_2018["Date_Time"].astype('int64') / 1e9 % 86400 / 3600).mean()
uj5u.com熱心網友回復:
要為該“分組聚合時間”內的所有行生成相同的聚合值,請使用 pd.groupby 和 pd.Grouper 的組合。將聚合值回傳到每一行而不是重新整形的資料幀的技巧是之后使用變換函式(我使用了 numpy 的均值 (np.mean),因此請確保在代碼中將 numpy 作為 np 匯入)。如果您需要更具體的靈活性(例如每 10 分鐘一次,但從某個偏移分鐘而不是零開始第一分鐘(例如 00:02:00 而不是 00:00:00),則需要其他引數。
import numpy as np
energy_2018["mean_hourly"] = energy_2018.groupby(pd.Grouper(key="Date_Time", freq="60Min")).transform(np.mean)
Date_Time Metered Electricity (MWh) mean_hourly
2016-03-27 00:03:00 8.644511 7.726456
2016-03-27 00:31:00 6.808402 7.726456
2016-03-27 01:00:00 6.507068 5.889349
2016-03-27 01:30:00 5.271631 5.889349
2016-03-27 02:00:00 2.313497 2.313497
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/371450.html