我正在為雙重拍賣實施匹配系統。我buy和sell訂單的陣列,[price, quantity]每個訂單。例如buy:
[[ 2 44]
[ 6 47]
[10 64]
[ 4 67]
[ 1 67]
[ 6 9]
[ 1 83]
[ 2 21]
[ 3 36]
[ 5 87]
[ 3 70]]
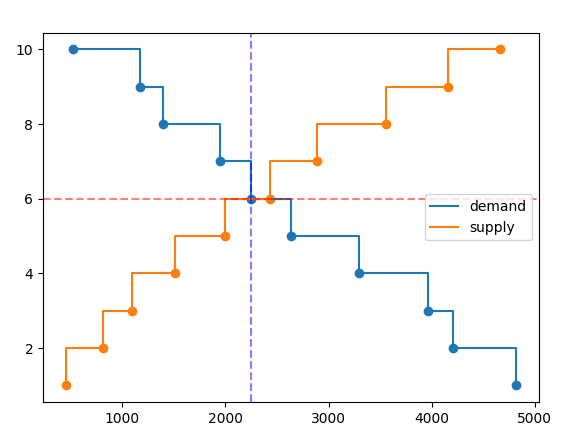
因此,第一個購買訂單是針對44價格為單位的單位2。價格僅限于價格網格,例如1, 2, ..., 10。對于每個可能的價格,我創建了顯示總需求和供應的累積陣列。例如,對于總需求,我查看P價格網格上每個價格的累計數量,對價格大于或等于 的所有買單求和P。然后我發現清算價格是總買單小于總賣單的價格。該結算量為總水平在清除價格越小。
例如這里的清算價格是6(紅色虛線)和周圍的清算數量2250(藍色虛線)
我的問題是,是否有更快/更清潔的方法來計算清算價格?假設價格網格變得非常精細(例如 10000 個可能的價格),而無需檢查每個可能的價格水平,我如何使其更有效率?速度和效率是主要問題。
在此處顯示 Python 實作(生產可能使用其他低級語言)
import numpy as np
MAX_QTY = 100
MIN_QTY = 0
MIN_PX = 1
MAX_PX = 11
TICK_SIZE = 1
price_grid = np.arange(MIN_PX, MAX_PX, TICK_SIZE)
def gen_orders(num, price_grid):
qty = np.random.randint(MIN_QTY, MAX_QTY, num)
px = np.random.choice(price_grid, num)
return np.array((px, qty)).T
buy = gen_orders(100, price_grid)
sell = gen_orders(100, price_grid)
agg = np.array([[x, np.sum(buy[buy[:, 0]>=x][:, 1]), np.sum(sell[sell[:, 0]<=x][:, 1])] for x in price_grid])
matched = agg[agg[:, 1]<agg[:, 2]][0, :] # price_grid is sorted
cleared_px = matched[0]
cleared_qty = np.min(matched[1:])
uj5u.com熱心網友回復:
您可以嘗試一些技巧:
當數量匹配時停止,如本筆記本所示
buy_sum = np.sum(buy[buy[:, 0]>=x][:, 1]) sell_sum = np.sum(sell[sell[:, 0]<=x][:, 1]) if buy_sum < sell_sum: cleared_px = x cleared_qty = buy_sum break首先對
buy和 進行排序,sell以便在sum_of_quantity回圈buy和時該函式可以更快sell。不幸的是,forPython 中的回圈有很多開銷,所以像np.sum(buy[buy[:, 0]>=x][:, 1])在 Python 中一樣使用 numpy 向量化操作會更快。但是,這在低級語言中很有用。如果您對
buy和sell訂單進行了排序,則快取總和值,例如在 bin 中。例如,可以將 的總和存盤x <= 4在記憶體中,因此當您要計算 的總和時x <= 5,可以使用 sum ofx <= 4加上 的總和x == 5。這需要x在訂單串列中跟蹤更改的索引。請注意,它不能與 numpy 向量化操作一起使用,因為這樣做與 numpybuy[:, 0]==5一樣昂貴buy[:, 0]<=5。嘗試諸如搜索演算法之類的方法。這對于更大的搜索空間很有用,即
price_grid有更多的值。例如price_grid <= 10,- 先試試
x == 5。 - 如果結果是
buy_sum > sell_sum,請嘗試一些x更大的,例如x == 7。 - 如果
buy_sum < sell_sum,通過檢查確認它是最優惠的價格x是x - 1;否則,選擇一個x更大的更小,5然后重復
- 先試試
uj5u.com熱心網友回復:
您在此陳述句中隱式創建了幾個嵌套回圈:
agg = np.array([[x, np.sum(buy[buy[:, 0]>=x][:, 1]), np.sum(sell[sell[:, 0]<=x][:, 1])] for x in price_grid])
盡管它們主要以矢量化格式執行,但當價格網格很大或訂單數量很大時,這會讓您感到厭煩。
您可以通過合并訂單以線性方式執行此操作。我在下面使用字典。然后,再一次線性遍歷buys字典以創建您需要的總需求數,這仍然是 O(n) 而不是 O(n^2)。
對于更大的n,這是一個巨大的變化。我對原點和模組(如下)進行計時,對于 5000 個訂單和 10K 的價格網格(您的價值),這個模組numpy在完全沒有操作的情況下快了 100 倍。
注意:如果供應 == 需求恰好在任何價格步長,則該模塊會提前停止,這在邏輯上略有不同。(不清楚這是錯誤還是功能...... :),但邏輯可以很容易地調整)。我已經展示了它們與時差匹配的(有點罕見的)事件的捕獲。
帶時間的編輯代碼
import numpy as np
import time
MAX_QTY = 10
MIN_QTY = 0
MIN_PX = 1
MAX_PX = 10_000
TICK_SIZE = 1
price_grid = np.arange(MIN_PX, MAX_PX, TICK_SIZE)
def gen_orders(num, price_grid):
qty = np.random.randint(MIN_QTY, MAX_QTY, num)
px = np.random.choice(price_grid, num)
return np.array((px, qty)).T
buy = gen_orders(5000, price_grid)
sell = gen_orders(5000, price_grid)
tic = time.time()
agg = np.array([[x, np.sum(buy[buy[:, 0]>=x][:, 1]), np.sum(sell[sell[:, 0]<=x][:, 1])] for x in price_grid])
matched = agg[agg[:, 1]<agg[:, 2]][0, :] # price_grid is sorted
cleared_px = matched[0]
cleared_qty = np.min(matched[1:])
toc = time.time()
print(f'ORIG: computed clear px: {cleared_px} and qty: {cleared_qty} in {toc-tic:0.6f} sec')
### ALTERNATE ###
# Start the clock again for the mod method...
tic = time.time()
buys = {}
sells = {}
# "bin" the buys by price
for b in buy:
buys[b[0]] = buys.get(b[0], 0) b[1]
# need to aggregate the demand...
agg_demand = {MAX_PX: buys.get(MAX_PX,0)} # starting point
for px in range(MAX_PX-1, MIN_PX-1, -1): # backfill down to min px
agg_demand[px] = agg_demand[px 1] buys.get(px, 0)
# "bin" the sells similarly
for s in sell:
sells[s[0]] = sells.get(s[0], 0) s[1]
# set up the loop
selling_px = MIN_PX
supply = sells.get(selling_px, 0)
demand = agg_demand.get(selling_px, 0)
while demand > supply:
# updates
selling_px = 1
demand = agg_demand.get(selling_px) # update with the pre-computed aggregate demand
supply = sells.get(selling_px, 0) # keep running aggregation of supply
new_cleared_px = selling_px
new_cleared_qty = min(demand, supply)
toc = time.time()
print(f'MOD: computed clear px: {new_cleared_px} and qty: {new_cleared_qty} in {toc-tic:0.6f} sec')
if cleared_px != new_cleared_px or cleared_qty != new_cleared_qty: # somethign wrong...??
print(agg[cleared_px-5:cleared_px 5,:])
輸出:
ORIG: computed clear px: 4902 and qty: 11390 in 1.183204 sec
MOD: computed clear px: 4899 and qty: 11398 in 0.020830 sec
[[ 4898 11411 11398]
[ 4899 11398 11398]
[ 4900 11398 11398]
[ 4901 11398 11398]
[ 4902 11390 11398]
[ 4903 11385 11398]
[ 4904 11385 11398]
[ 4905 11385 11398]
[ 4906 11385 11398]
[ 4907 11384 11398]]
[Finished in 1.3s]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/372354.html
上一篇:Python:用變數名填充串列?