使用串列集并將此資料創建或匯出到csv檔案的最佳方法是什么?
首先,我必須強調我的資料是型別的,string所以我需要一種方法來收集這些資料并將逗號和值過濾為整數型別。
signals = ['-108', '-107', '-107', '-107', '-107', '-107', '-94', '-87', '-108']
Costs = ['8325', '5175', '2698', '1754', '4767', '3652', '2417', '7527', '3698']
我想要什么:
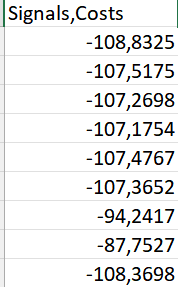
我得到這樣的檔案:

我的代碼中寫入 csv 檔案的部分:
import csv
fieldnames = ['Signals','Costs']
s = ' '.join(signals)
c = ' '.join(costs)
with open('Data_to_Csv.csv', 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Signals':s,'Costs':c})
uj5u.com熱心網友回復:
我假設信號和成本的長度是相同的。如果這是真的,這就是你的問題:
s = ' '.join(signals)
c = ' '.join(costs)
這樣做是創建了一個名為 s 的字串,其值為所有數字signals與空格連接在一起,以及一個名為 c 的字串,其值為 . 中的所有數字costs。因此,您將有效地擁有以下內容:
>>> signals = ['-108', '-107', '-107', '-107', '-107', '-107', '-94', '-87', '-108']
>>> costs = ['8325', '5175', '2698', '1754', '4767', '3652', '2417', '7527', '3698']
>>> s = ' '.join(signals)
>>> c = ' '.join(costs)
>>> print(s)
-108 -107 -107 -107 -107 -107 -94 -87 -108
>>> print(c)
8325 5175 2698 1754 4767 3652 2417 7527 3698
因此,當您呼叫 時writer.writerow({'Signals': s, 'Costs': c}),它只會將兩個字串與','它們之間的 連接起來。這就是您在生成的 CSV 檔案中看到的內容。
您需要做的是遍歷串列和信號中的每個索引,獲取成本,然后將其寫入您的 CSV 檔案。像這樣的東西:
with open('Data_to_Csv.csv', 'w') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for i in range(len(signals)):
writer.writerow({'Signals':signals[i],'Costs':costs[i]})
這將產生一個 Data_to_Csv.csv 檔案,如下所示:
Signals,Costs
-108,8325
-107,5175
-107,2698
-107,1754
-107,4767
-107,3652
-94,2417
-87,7527
-108,3698
請注意,此方法僅適用于len(signals) == len(costs). 如果這不是真的,你需要處理這種情況。
uj5u.com熱心網友回復:
使用pandas.DataFrame.to_csvfrompandas并將當前資料匯出到csv檔案中。
>>> import pandas
>>> signals = ['-108', '-107', '-107', '-107', '-107', '-107', '-94', '-87', '-108']
>>> costs = ['8325', '5175', '2698', '1754', '4767', '3652', '2417', '7527', '3698']
>>> df = pandas.DataFrame({'Signals':signals, 'Costs':costs})
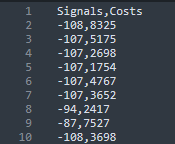
>>> df.to_csv(index=False)
'Signals,Costs\r\n-108,8325\r\n-107,5175\r\n-107,2698\r\n-107,1754\r\n-107,4767\r\n-107,3652\r\n-94,2417\r\n-87,7527\r\n-108,3698\r\n'
壓縮并寫入csv檔案:
>>> compression_opts = dict(method='zip', archive_name='out.csv')
>>> df.to_csv(index=False, compression=compression_opts)
uj5u.com熱心網友回復:
只需使用csv:
import csv
signals = ['-108', '-107', '-107', '-107', '-107', '-107', '-94', '-87', '-108']
costs = ['8325', '5175', '2698', '1754', '4767', '3652', '2417', '7527', '3698']
with open("Data_to_Csv.csv", "w") as f:
writer = csv.writer(f)
writer.writerow(["Signals", "Costs"])
writer.writerows(zip(signals, costs))
但是,如果您發現convtools有用,那么您可以:
from convtools.contrib.tables import Table
Table.from_rows(
zip(signals, costs),
header=["Signals", "Costs"]
).into_csv("Data_to_Csv.csv")
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/372804.html
上一篇:用熊貓(python)繪制資料框