我是編碼新手。我想要一個適用于 csv 檔案的邏輯。假設我有一個列名為“標簽”的資料框,我想讓輸出看起來像列“預期標簽”。
print (df)
label
0 A
1 B
2 C
3 A
4 B
5 C
6 A
7 B
8 C
9 B
10 C
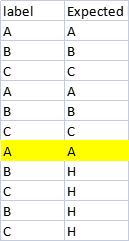
我需要找到值“A”的最后一次出現并替換其他值(在本例中“B”和“C”與“H”)僅在最后一次出現之后發生。這是我的代碼,之后不知道如何進行。
last=df['labels']
max(loc for loc, val in enumerate(last) if val == 'A')
這讓我最后一次出現“A”。我需要的是如何在找到我在“預期標簽”列中提到的最后一次出現后替換值。我真的很感謝你的幫助。
uj5u.com熱心網友回復:
使用Series.cummax與交換順序iloc[::-1]進行False了最后一次后,所有的值A并設定值Series.where:
df['Expected'] = df['label'].where(df['label'].eq('A').iloc[::-1].cummax(),
df['label'].replace(to_replace =["B", "C"], value ="H"))
print (df)
label Expected
0 A A
1 B B
2 C C
3 A A
4 B B
5 C C
6 A A
7 B H
8 C H
9 B H
10 E E
或者:
df['Expected'] = df['label'].where(df['label'].eq('A').iloc[::-1].cummax() |
~df['label'].isin(['B','C']), 'H')
print (df)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/372884.html
下一篇:如何對調查資料執行預測演算法?