前言
隨著前端智能化的火熱,AI機器學習進入前端開發者們的視野,AI能夠解決編程領域不能直接通過規則和運算解決的問題,通過自動推理產出最佳策略,成為了前端工程師們解決問題的又一大利器,
可能很多同學都躍躍欲試過,打開 TensorFlow 或者 Pytorch 官網,然后按照檔案想要寫一個機器學習的 Hello World ,然后就會遇到一些不知道是什么的函式,跑完例子卻一頭霧水,這是因為 TensorFlow 和 Pytorch 是使用機器學習的工具,而沒有說明什么是機器學習,所以這篇文章以實踐為最終目的出發,介紹一些機器學習入門的基本原理,加上一丟丟影像處理的卷積,希望可以幫助你理解,
基礎概念
首先,什么是機器學習?機器學習約等于找這樣一個函式,比如在語音識別中,輸入一段語音,輸出文字內容

在影像識別中,輸入一張影像,輸出圖中的物件,

在圍棋中,輸入棋盤資料,輸出下一步怎么走,
在對話系統中,輸入一句 hi ,輸出一句回應,
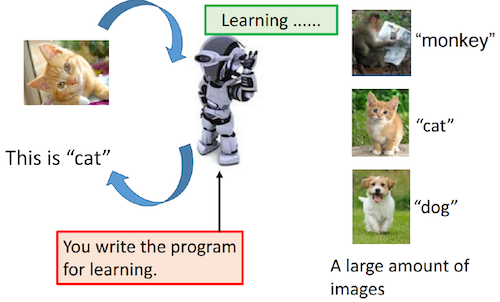
而這個函式,是由你寫的程式加上大量的資料,然后由機器自己學習到的,
怎么找這樣一個函式呢,讓我們從線性模型入手,線性模型形式簡單,易于建模,但是蘊含著機器學習中一些重要的基本思想,許多功能更為強大的非線性模型都可在線性模型的基礎上通過引入層級結構或高維映射而得到,
線性模型
我們以一個貓和狗的分類來看,我們在教一個小朋友區分貓和狗的時候,并不會給到一個維奇百科的定義,而是不斷的讓小朋友看到貓和狗,讓他判斷,然后告訴他正確答案,糾結錯誤認知,機器學習也是同理,不斷告知計算機怎樣是正確的,糾正計算機的認知,不同的是,小朋友的認知是人腦自動處理完成的,而計算機并不能自動的構建貓和狗的記憶,計算機只認識數字,
所以我們需要提取出代表貓和狗的特征,然后用數字來表示,為了簡化例子,我們這里只用到兩個特征,鼻子的大小以及耳朵的形狀,一般來說貓貓的鼻子更小,耳朵更尖,而狗狗鼻子比較大,耳朵比較圓,
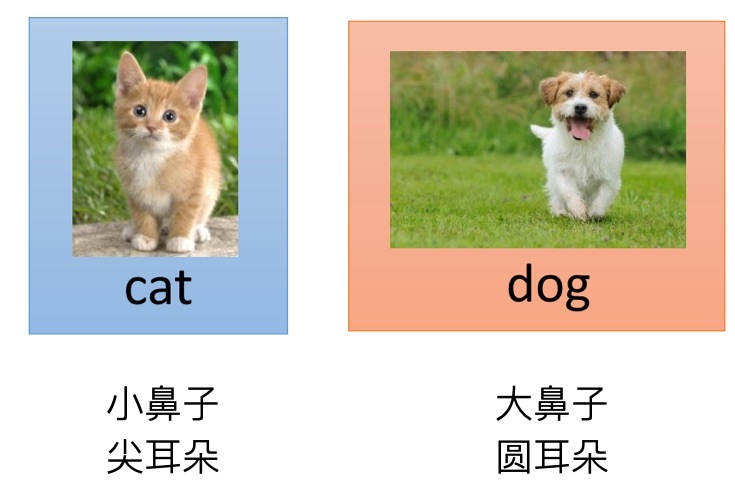
我們對多張圖片,統計圖片中耳朵以及鼻子特征,在一個二維坐標中表現出來,可以看到貓貓和狗狗會分布在坐標系的不同區域,
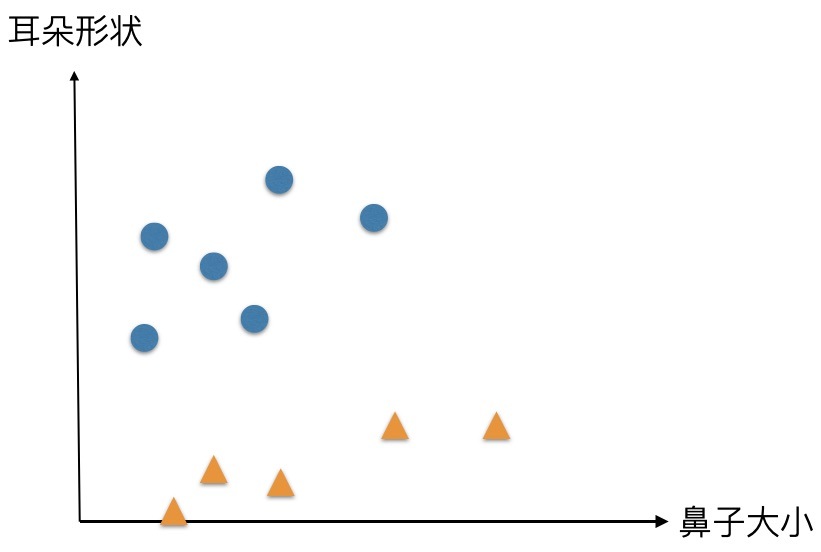
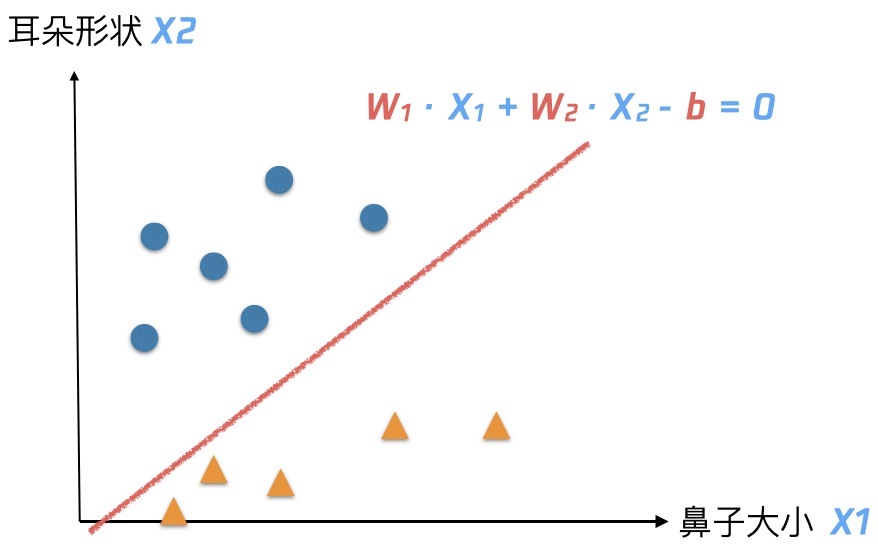
肉眼可見,我們可以用一條直線來區分,但是,計算機并看不到哪里可以畫條線,如何將資訊傳遞給計算機呢,讓我們定義兩個變數,x1 表示鼻子大小,x2 表示耳朵形狀,再定義這樣一個直線方程 W1 · X1 + W2 · X2 - b = 0,也就相當于,令y=W1 · X1 + W2 · X2 - b ,當 y 大于0,判斷是貓,當 y 小于 0 ,判斷是狗,
現在,從計算機的角度來看,它擁有了一堆資料,
以及一個線性模型,
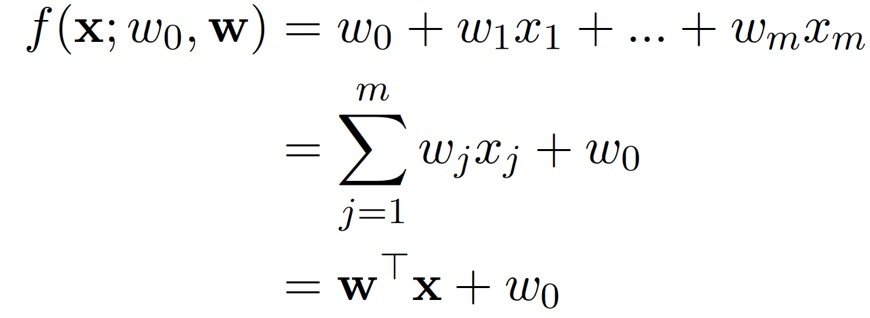
還差一個目標/任務,我們的期望是,當給一個沒有見過的 x ,通過 f(x) ,可以得到一個預測值 y ,這個 y 要能夠盡可能的貼近真實的值,這樣,就有了一臺有用的萌寵分類機了!這樣的目標如何用數字來表示呢,這就要引入一個概念損失函式(Loss function)了,損失函式計算的是預測值與真實值之間的差距,
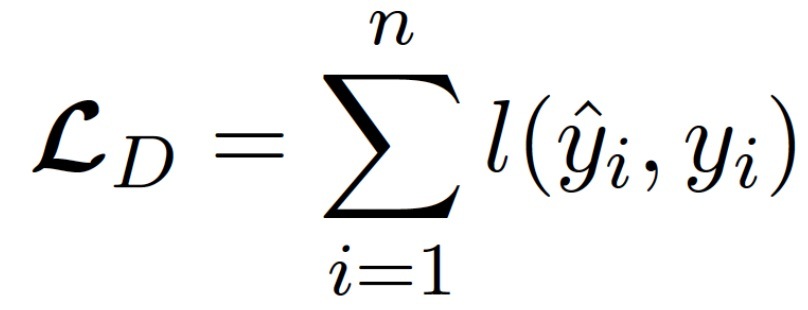
常用的損失函式有絕對值損失函式(Absolute value loss),也就是兩個數值差的絕對值,就很直觀,距離目標差多少,加起來,就醬
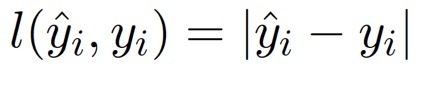
還有平方損失函式(最小二乘法, Least squares loss)
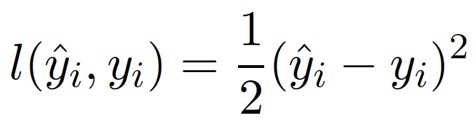
平方損失函式的目標是讓每個點到回歸直線的距離最小,這個距離算的是歐幾里得距離,
現在,我們給計算機的目標就變成了求一個最小值,

為了求這個值,讓我們回憶一下久違的微積分,(同樣,為了簡化到二維坐標系,假設只有一個需要求的 w ),導數為 0 的地方即是函式的極大值或者極小值,
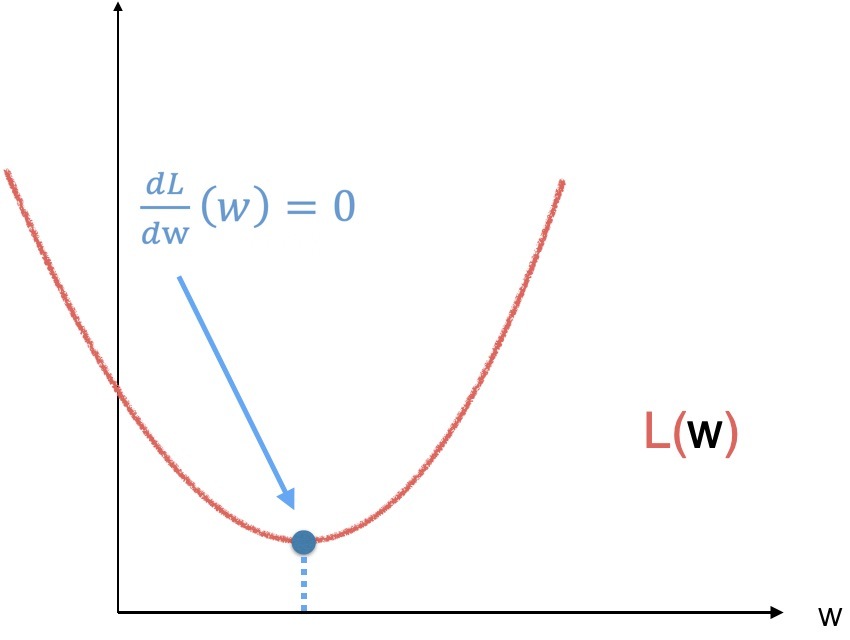
對于圖中這樣一個簡單的一元二次方程,我們可以直接對引數 w 求導,求得極小值,但是,如果是下圖中這樣一個函式呢,就..不好求了,而且對于不同的函式求導有不同的公式,那就..比較麻煩了,畢竟我們的目標是讓機器自己學習,是吧,
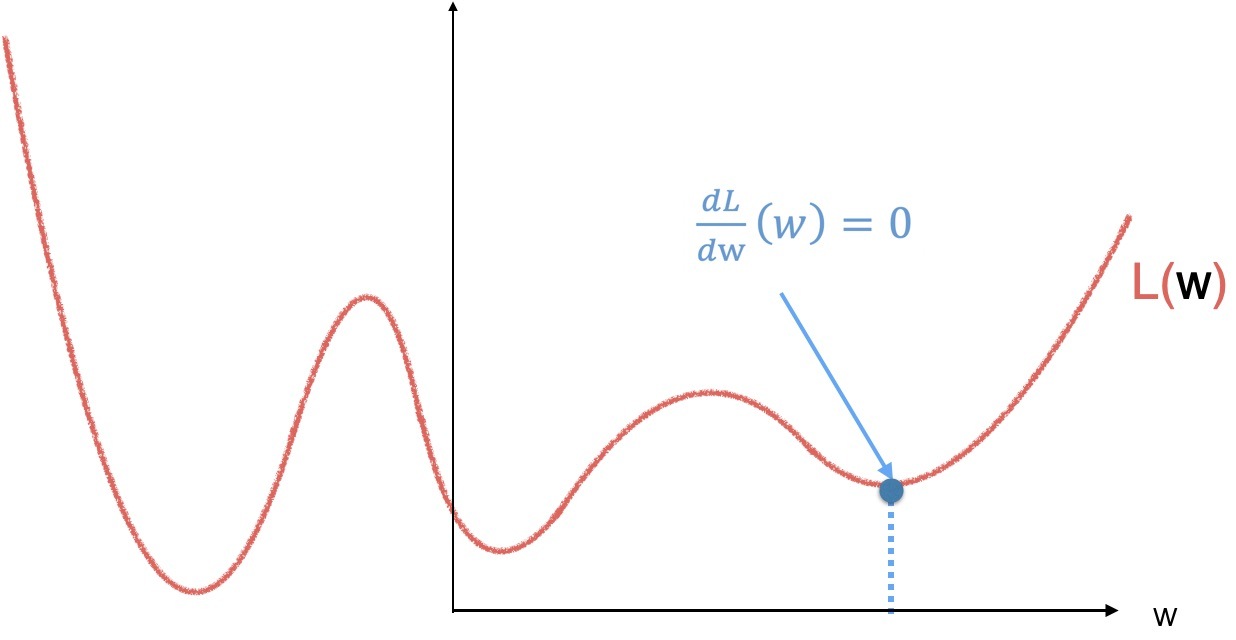
所以,我們需要一個更通用的計算方法,那就是梯度下降(Gradient descent,
梯度下降的基本流程如下,首先,我們隨機取一個點作為初始值,計算這個點的斜率,也就是導數,
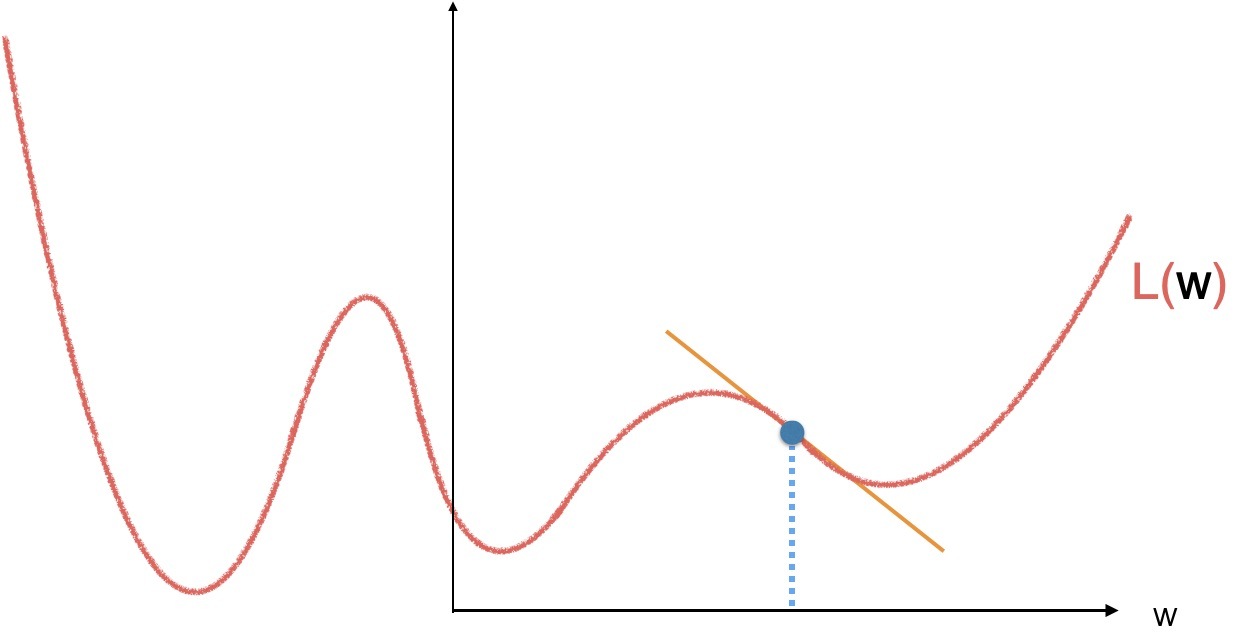
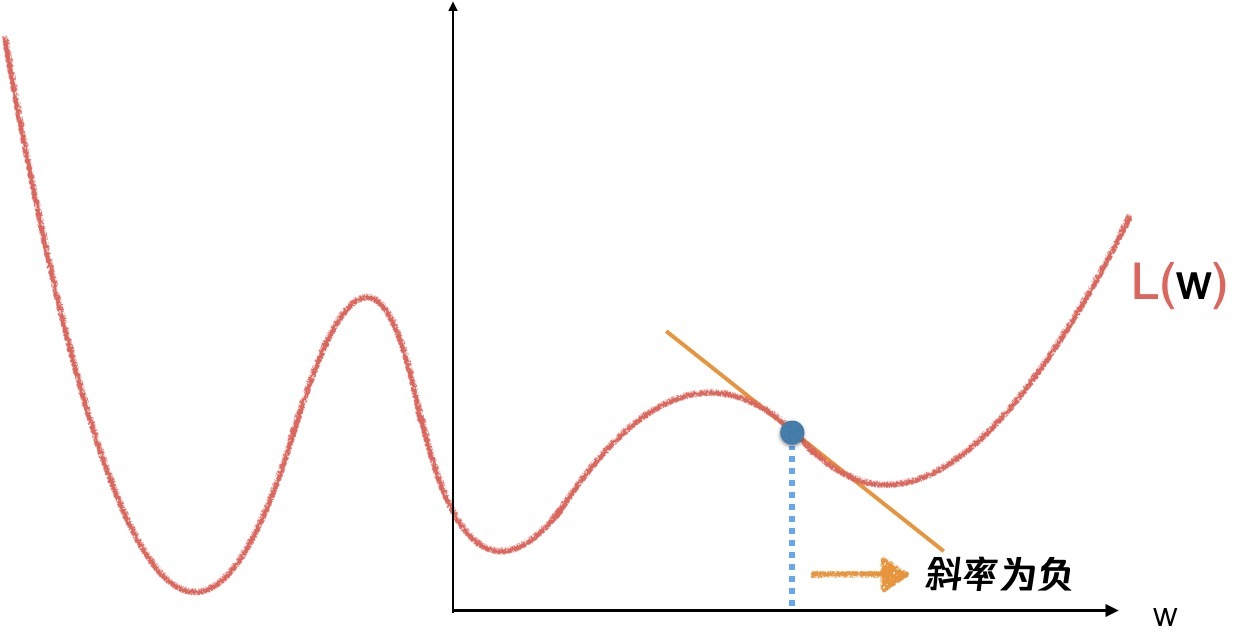
當斜率為負的時候,往右走一小步,
當斜率為正的時候,往左走一小步,
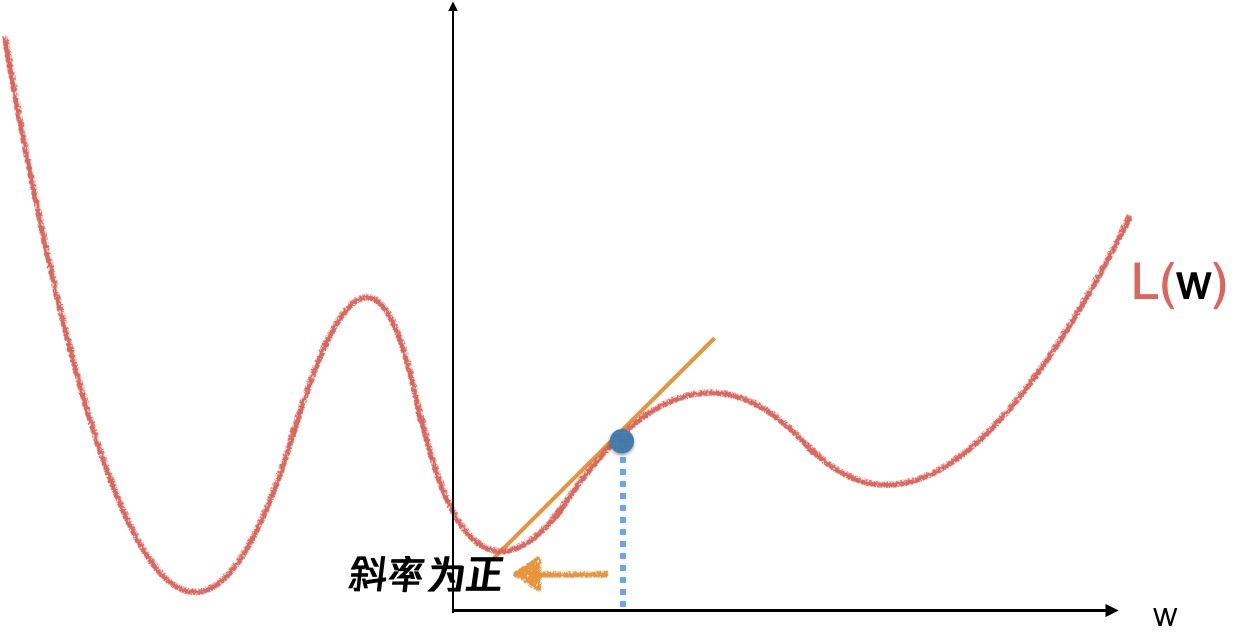
在每個點上重復,計算新的斜率,再適當的走一小步,就會逼近函式的某個區域最小值,就像一個小球從山上滾下來,不過初始位置不同,會到達不同的區域最小值,無法保證是全域最小,但是,其實,大部分情況我們根據問題抽象的函式基本都是凸函式,能夠得到一個極小值,在極小值不唯一的情況下,也可以加入亂數,來給到一個跳出當前極小值區域的機會,我們需要明確的是,機器學習的理論支撐是概率論與統計學,我們通過機器學習尋找的問題答案,往往不是最優解,而是一個極優解,
想象一個更復雜的有兩個輸入一個輸出的二元函式,我們的 loss function 可以呈現為三維空間中的一個曲面,問題就變成了,曲面上某個點要往空間中哪個方向走,才能讓結果下降得最快,
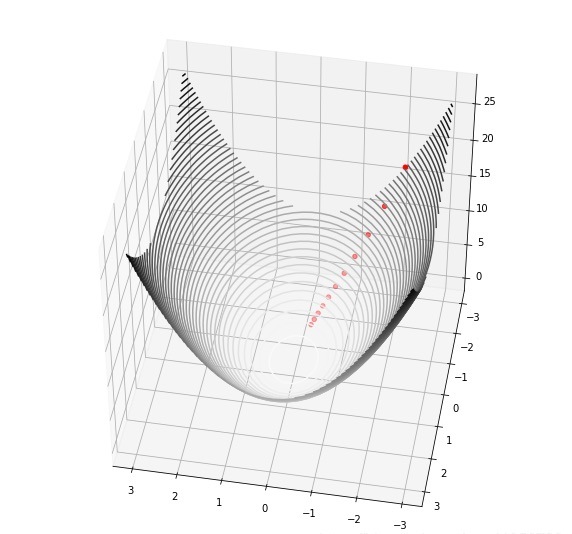
步驟依舊是,計算梯度,更新,計算,更新....用公示來表示就是如下,
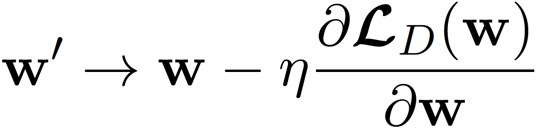
這時候,我們就遇到了第一個超引數 η ,即學習率(Learning rate),機器學習中的引數分為兩類,模型引數與超引數,模型引數是 w 這種,讓機器自己去學習的,超引數則是在模型訓練之前由開發人員指定的,
通過上面的公式,可以看到
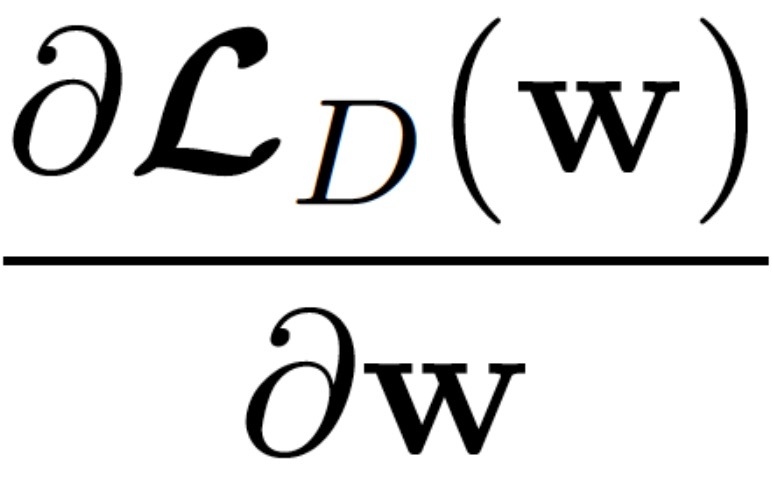
是 Loss function 函式對于引數 w 的導數,決定了我們走的方向,那么學習率則決定了在這個方向每一小部走的距離,
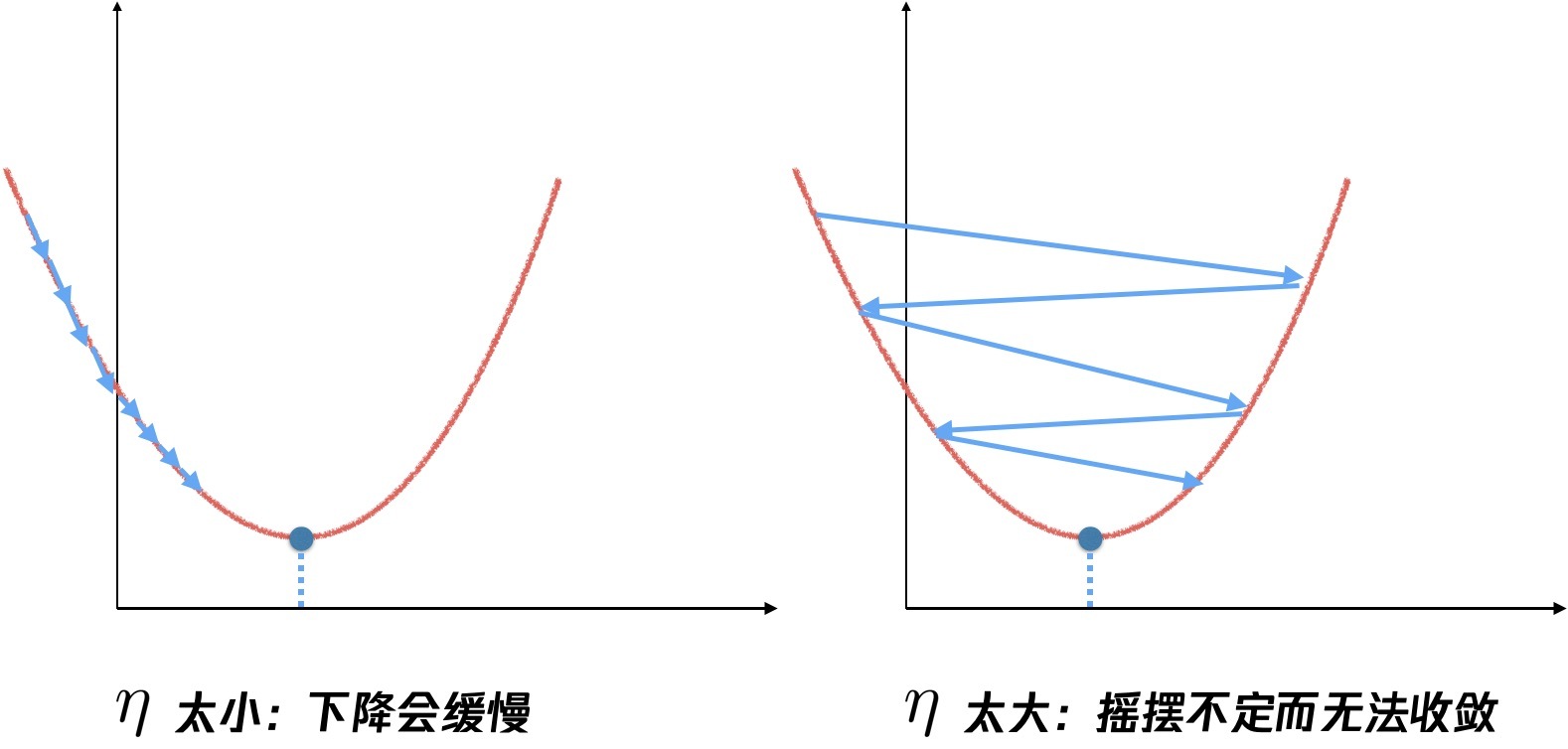
當 η 太小,到達極小值的程序會非常的緩慢,而如果 η 太大,則會因為步伐太大,直接越過最低點,那么,η 的值要怎么取呢,
比較常規的做法是,以從 0.1 這樣的值開始,然后再指數下降,取0.01,0.001,當我們用一個很大的學習率,會發現損失函式的值幾乎沒有下降,那可能就是在搖擺,當我們取到一個較小的值,能夠讓損失函式下降,那么繼續往下取,不斷縮小范圍,這個程序也可以通過計算機自動來做,如果有計算資源的話,
了解了梯度下降、學習率后,我們已經可以使用線性模型解決比較簡單的問題了,
基本步驟:
- 提取特征
- 設定模型
- 計算梯度,更新
是不是想試一下了!
這里有一個簡單的房價預測的栗子,可以本地跑跑看,試試調整不同的學習率,看 loss function 的變化,
https://github.com/xs7/MachineLearning-demo/blob/master/RegressionExperiment.ipynb
其中關鍵代碼如下:
# 損失函式
def lossFunction(x,y,w,b):
cost=np.sum(np.square(x*w+b-y))/(2*x.shape[0])
return cost
# 求導
def derivation(x,y,w,b):
#wd=((x*w+b-y)*x)/x.shape[0]
wd=x.T.dot(x.dot(w)+b-y)/x.shape[0]
bd=np.sum(x*w+b-y)/x.shape[0]
return wd,bd
# 線性回歸模型
def linearRegression(x_train,x_test,y_train,y_test,delta,num_iters):
w=np.zeros(x.shape[1]) # 初始化 w 引數
b=0 # 初始化 b 引數
trainCost=np.zeros(num_iters) # 初始化訓練集上的loss
validateCost=np.zeros(num_iters) # 初始化驗證集上的loss
for i in range(num_iters): # 開始迭代啦
trainCost[i]=lossFunction(x_train,y_train,w,b) # 計算訓練集上loss
validateCost[i]=lossFunction(x_test,y_test,w,b) # 計算測驗集上loss
Gw,Gb=derivation(x_train,y_train,w,b); # 計算訓練集上導數
Dw=-Gw # 斜率>0 往負方向走,所以需要加負號
Db=-Gb # 同上
w=w+delta*Dw # 更新引數w
b=b+delta*Db # 更新引數b
return trainCost,validateCost,w,b
多層感知機
我們剛剛說到的線性模型,實際上是一個單層的網路,它包括了機器學習的基本要素,模型、訓練資料、損失函式和優化演算法,但是受限于線性運算,并不能解決更加復雜的問題,
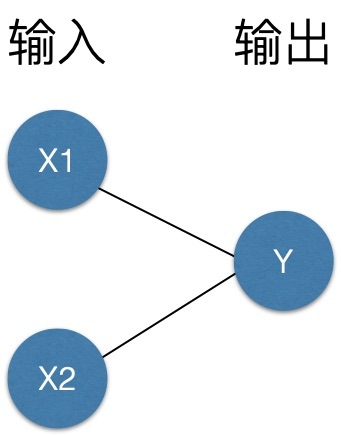
我們需要更為通用的模型來適應不同的資料,比如多加一層?加一層的效果約等于對坐標軸進行變換,可以做更復雜一丟丟的問題了,
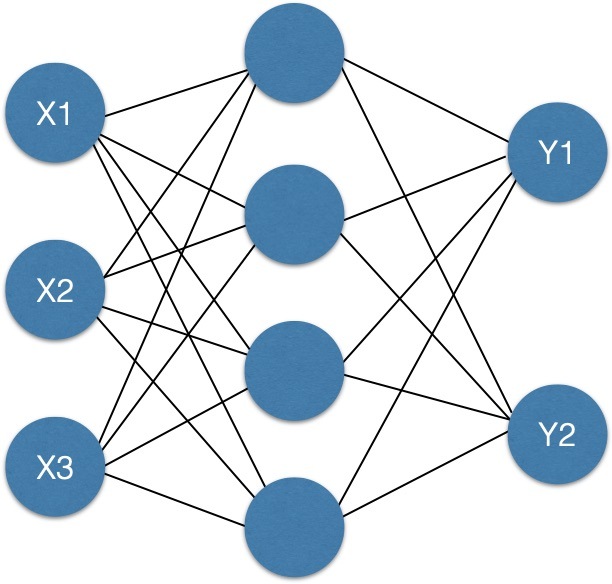
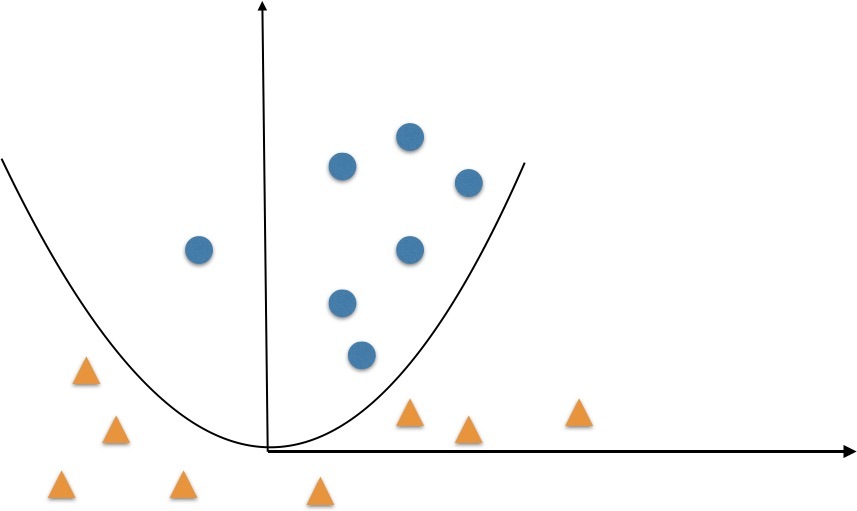
但是依舊是線性模型,沒有辦法解決非線性問題,比如下圖中,沒有辦法用一條直線分開,但是用 y= x2 這樣一個二元一次方程就可以輕輕松松,這就是非線性的好處了,
加一個非線性的結構,也就引入了神經網路中另一個基本概念,激活函式(Activation Function),常見的激活函式如下
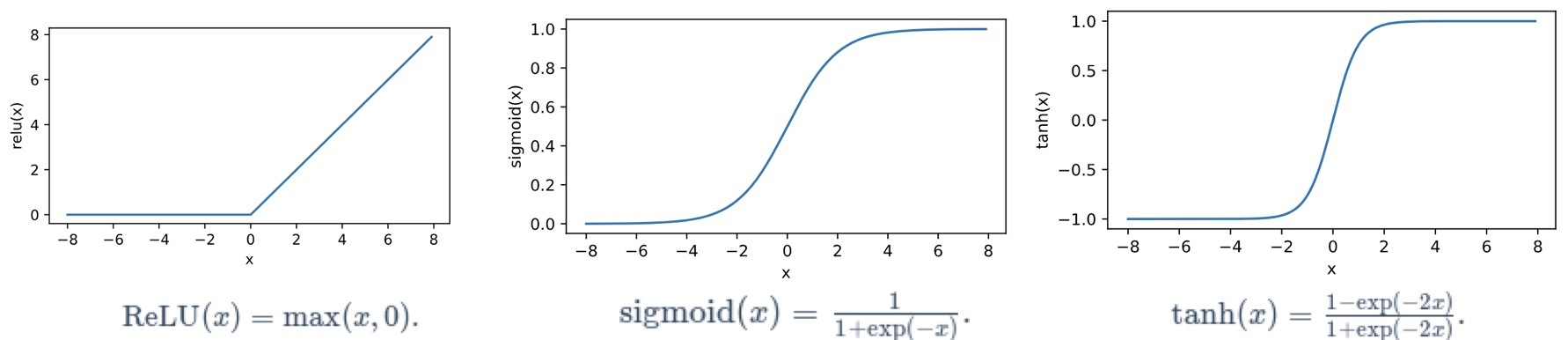
Relu 函式只保留正數元素,清零負數元素,sigmoid 函式可以把元素的值變換到 0~1 之間,tanh 函式可以把元素的值變換到 -1~1 之間,其中用到最廣泛的是看上去最簡單的 Relu ,Relu函式就好比人腦神經元,達到神經元的刺激閾值就輸出,達不到閾值就置零,
激活函式的選擇要考慮到輸入輸出以及資料的變化,比如通常會用 sigmoid 作為輸出層的激活函式,比如做分類任務的時候,將結果映射到 0~1 ,對于每個預設的類別給到一個 0~1 的預測概率值,
可以理解為,我們提供了非線性的函式,然后神經網路通過自己學習,使用我們提供的非線性元素,可以逼近任意一個非線性函式,于是可以應用到眾多的非線性模型中,
加入激活函式后,我們就擁有了多層感知機(multi layer perceptron),多層感知機就是含有至少一個隱藏層的由全連接層組成的神經網路,且每個隱藏層的輸出通過激活函式進行變換,
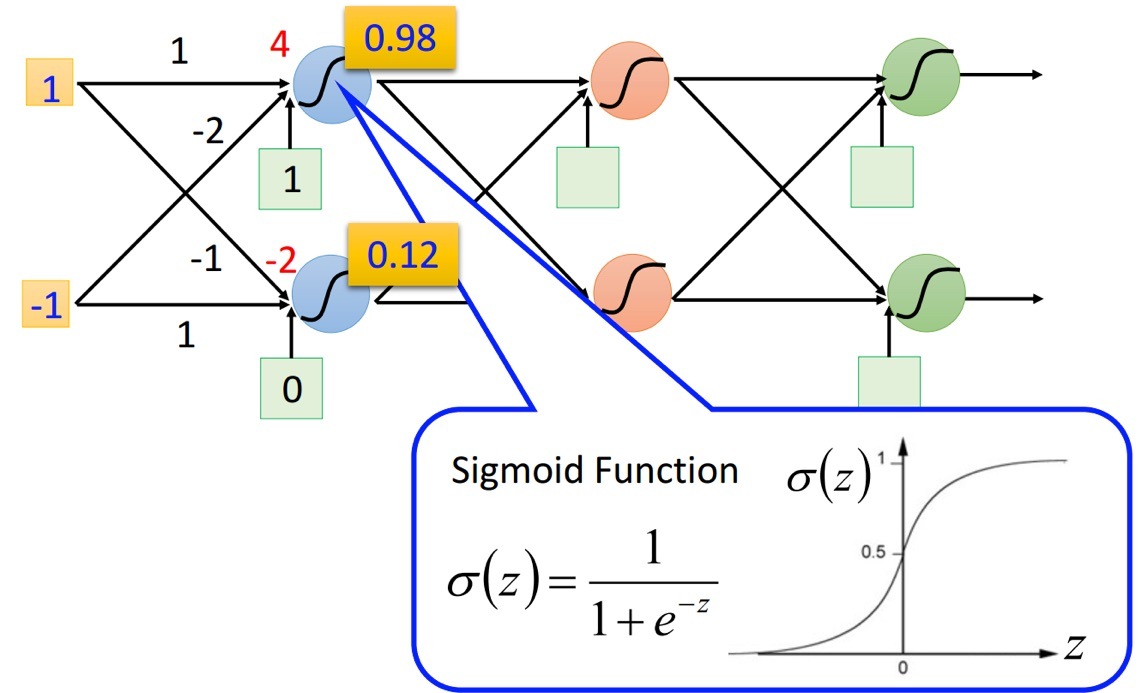
類似上圖這樣,就構成了一個簡單的多層感知網路,即深度神經網路,網路層級變復雜之后,依舊是使用梯度下降來進行迭代優化,但是梯度的計算卻變復雜了,網路中的每條線上都有一個 w 權重引數,需要用 loss function 對每個 w 求梯度,大概估一下,假設輸入層有10個節點,有兩個隱藏層,每個隱藏層隱藏層那從輸入層到隱藏層 1 再到隱藏層 2 就有 30000*3 個引數,而且引數之間是存在函式關系的,最終輸出的 loss 對第一層隱藏層的 w 求導需要逐層求過來,計算量++++++n, 直接求導是萬萬不可能的,所以我們需要反向傳播演算法(Backpropagation,bp演算法),
反向傳播演算法
反向傳播演算法是用來在多層網路中快捷的計算梯度的,其推導相對而言要復雜一些,使用框架的時候..直接呼叫api即可,也沒有什么開發者能調整的地方,大家應該..不想寫代碼計算偏導數吧..那就作為進階內容,先挖個坑..下次來填..
中途小結
到現在我們應該對神經網路的計算已經有了一個基本的印象,回顧一下,
就是給到一個多層網路結構模型,然后輸入資料,不斷求梯度來更新模型的引數,不斷減少模型預測的誤差,其中使用梯度來更新引數的步伐由超引數學習率決定,用偽代碼表示就是:
for i in 迭代次數:
loss = 預測值和真實值的差距
d = loss 對 w求導
w = w - d * 學習率
到這里,我們已經知道了一個深度神經網路基本結構以及計算流程,可以看懂一些簡單的使用神經網路的代碼了,繼續回去看 Pytorch 官方教程,結果 demo 里面都是影像的栗子,所以..那就再看看什么是卷積神經網路叭,
卷積神經網路
我們前面提到的網路模型中,相鄰兩層之間任意兩個節點之間都有連接,稱之為全連接網路(Fully Connected Layer),當我們用一個深度網路模型處理圖片,可以把圖片中每個像素的 rgb 值均作為輸入,一張 100*100 的圖片,網路的輸入層就有 100*100*3 個節點,哪怕只給一個隱藏層,輸入層到隱藏層就已經有 30000*100 個引數了,再添加幾層或者換稍微大一點的圖片,引數數量就更爆炸了,影像需要處理的資料量太大,使用全連接網路計算的成本太高,而且效率很低,直到卷積神經網路(Convolutional Neural Network, CNN)出現,才解決了影像處理的難題,
直接來看卷積神經網路是什么樣子的吧,如下
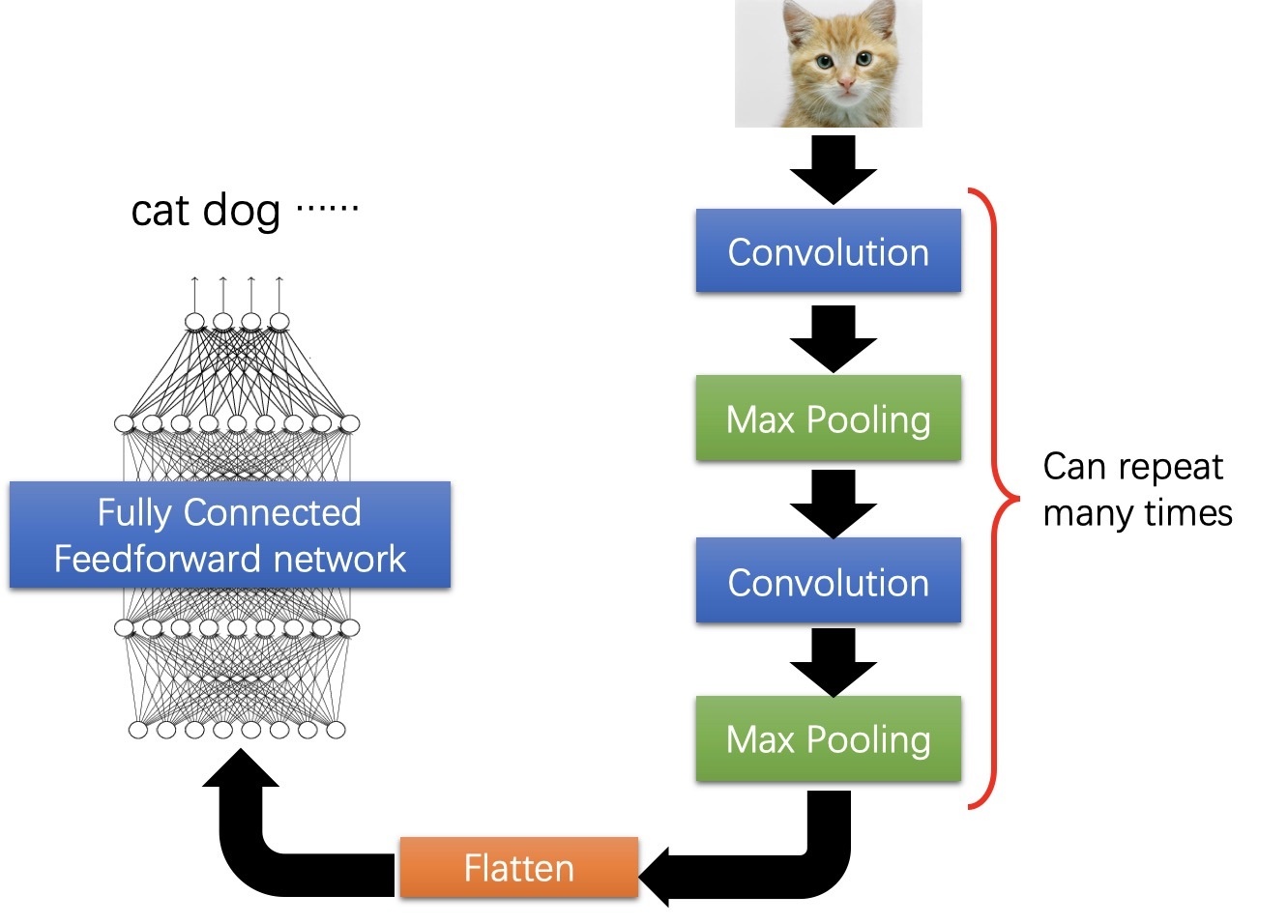
一個典型的卷積神經網路包括了三部分
- 卷積層
- 池化層
- 全連接層
其中,卷積層用來提取圖片的特征,池化層用來減少引數,全連接層用來輸出我們想要的結果,
先來看卷積,
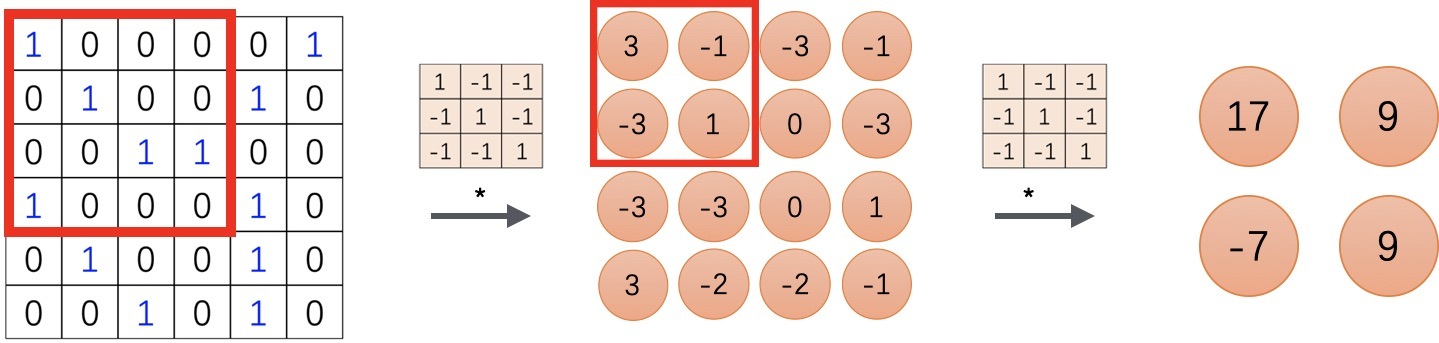
輸入一張圖片,再給到一個卷積核(kernel,又稱為filter濾波器)
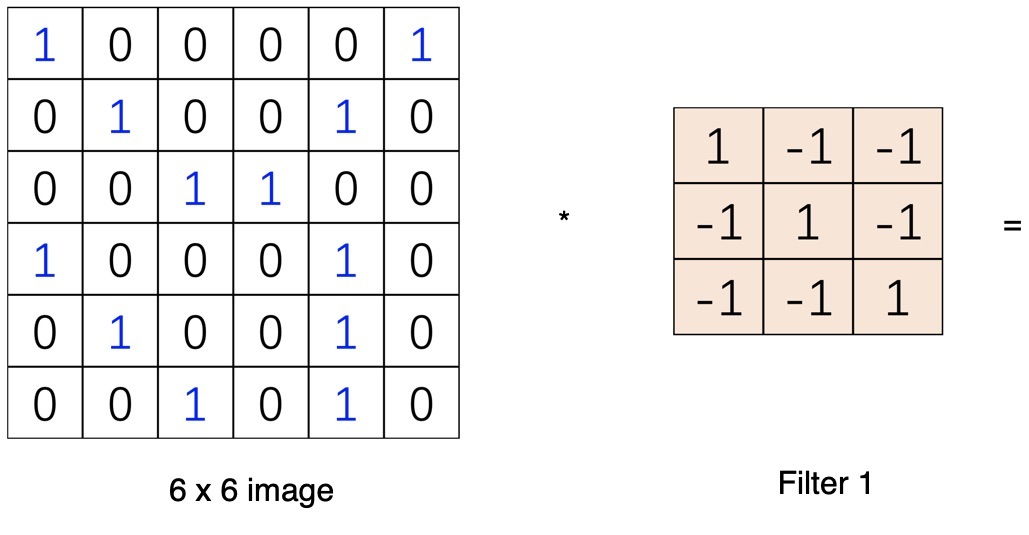
將濾波器在影像上滑動,對應位置相乘求和,
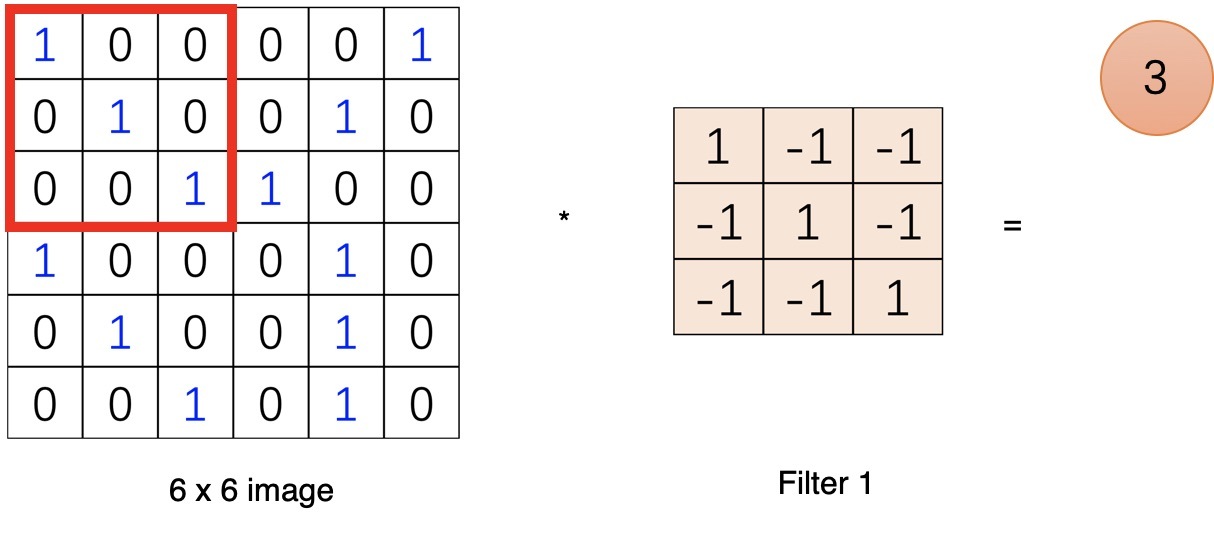
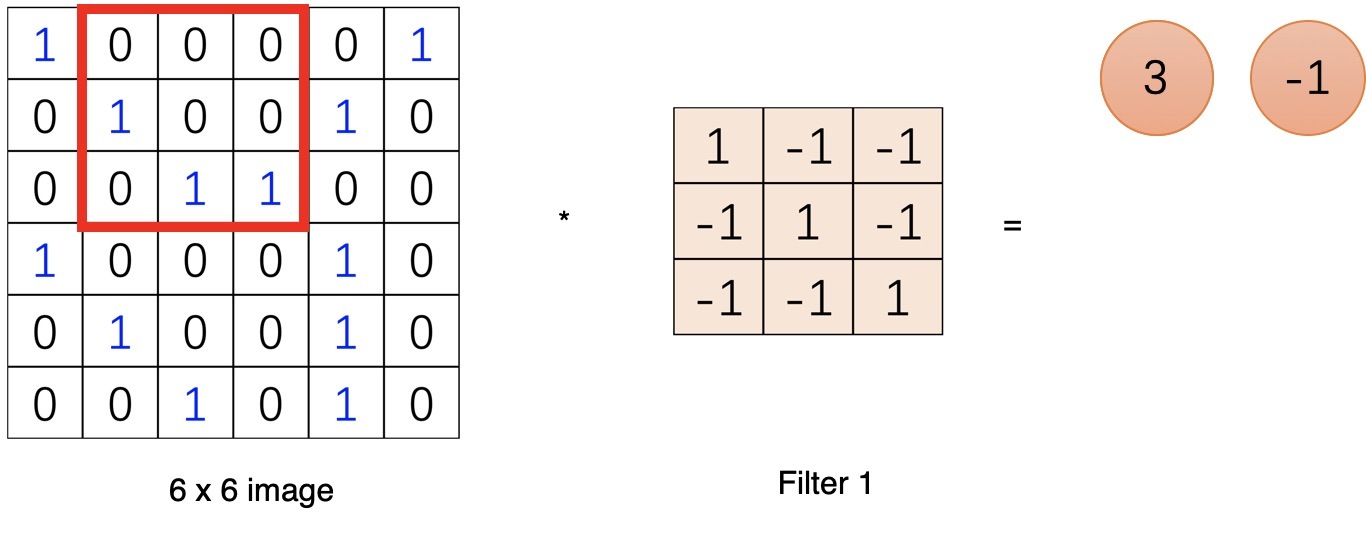
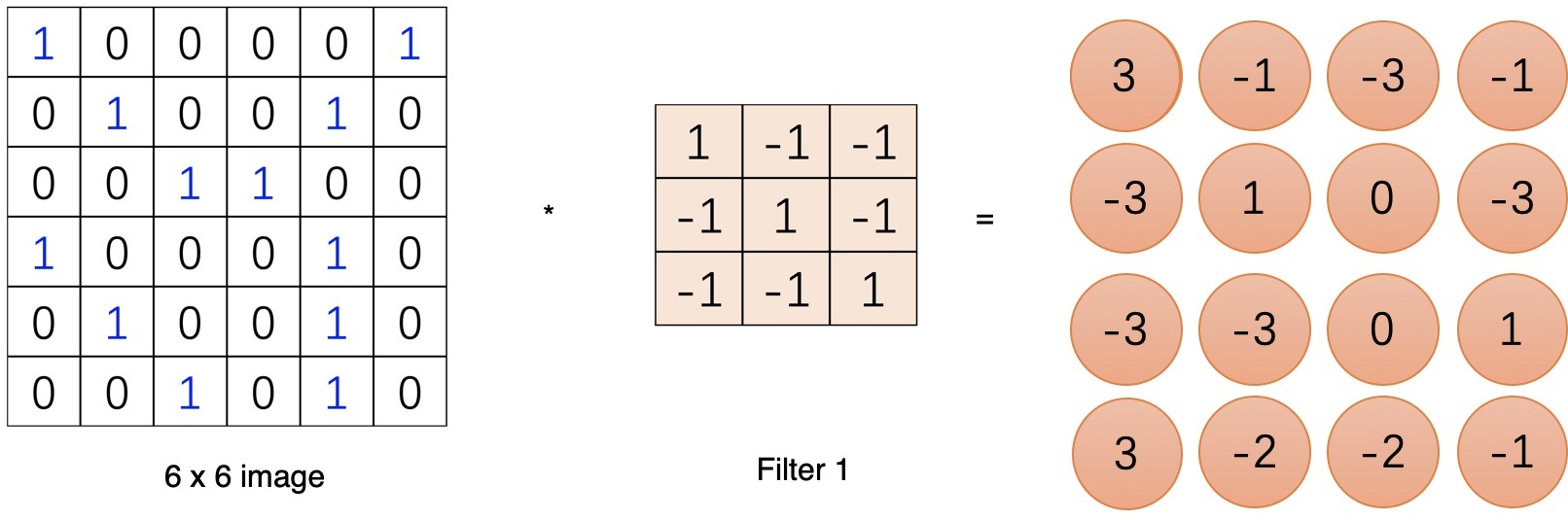
滑完可以得到一個新的二維陣列,這就是卷積運算了,是的..就是這樣簡單的加法,
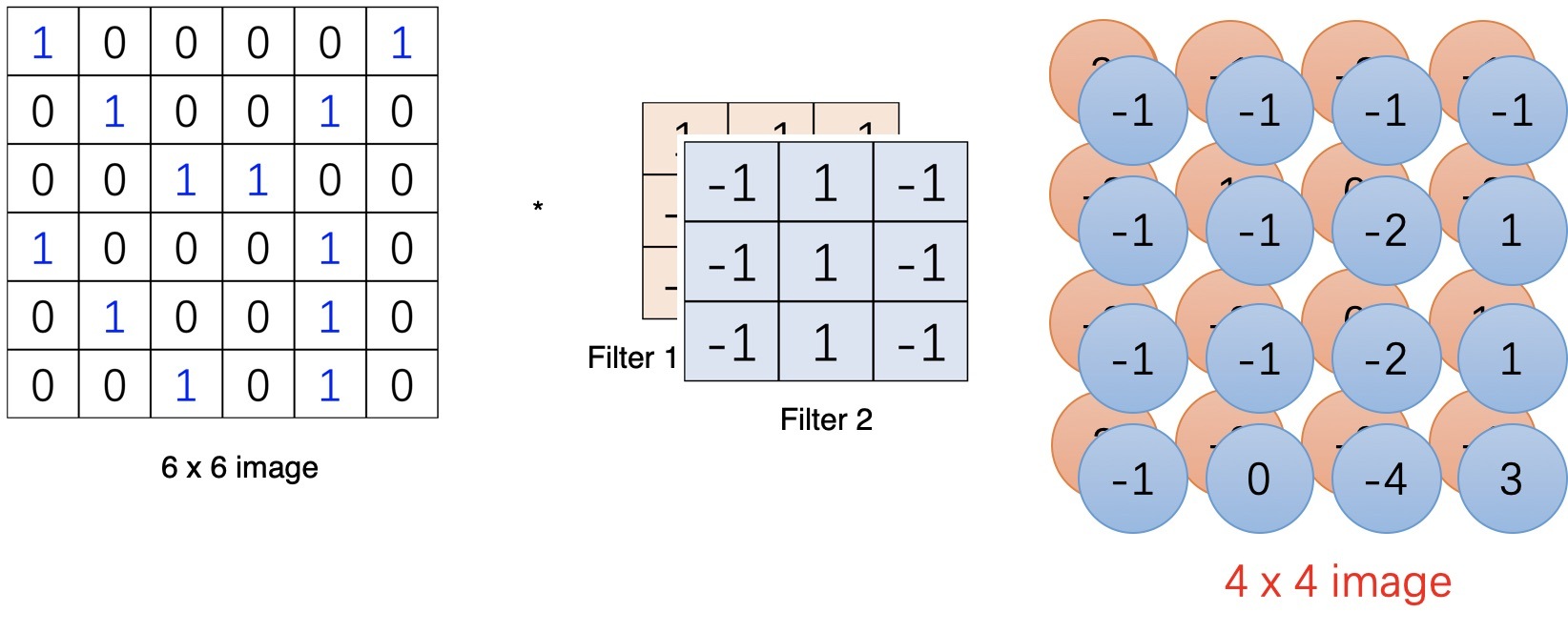
如果再加一個卷積核,運算完畢就得到了兩個通道的陣列,
二維卷積層輸出的二維陣列可以看作是輸入在空間維度(寬和高)上某一級的表征,也叫特征圖(feature map),
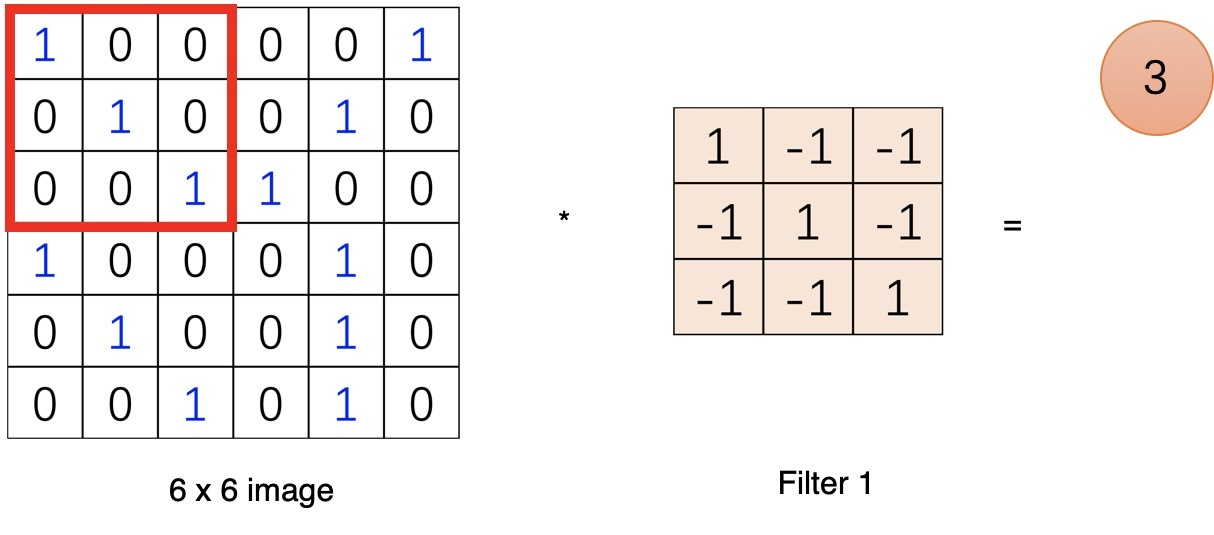
一個節點的輸入來源區域稱為其感受野(receptive field),比如特征圖中第一個節點 3 的輸入野就是輸入圖片左上角 3*3 的區域,
如果我們對結果再來一次卷積,最后得到的特征圖中的第一個節點 17 ,其感受野就變成了其輸入節點的感受野的并集,即圖片左上角 4*4 的區域,我們可以通過更深的卷積神經網路使特征圖中單個元素的感受野變得更加廣闊,從而捕捉輸入上更大尺寸的特征,
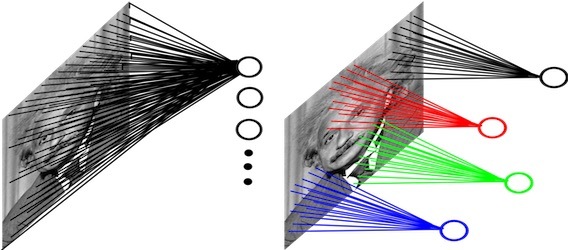
這其實是模擬人類視覺原理,當我們接收到視覺信號,大腦皮層的某些細胞會做初步處理,發現邊緣以及方向,然后再進行抽象,判定眼前物體的形狀是圓的還是方的,然后進一步抽象是什么物體,通過多層的神經網路,較低層的神經元識別初級的影像特征,若干底層特征組成更上一層特征,最終得到最高抽象的特征來得到分類結果,
了解了多層卷積是從區域抽象到全域抽象這樣一個識別程序后,再回過頭來看一下卷積核本身,
從函式的角度來理解,卷積程序是在影像每個位置進行線性變換映射成新值的程序, 在進行逐層映射,整體構成一個復雜函式,從模版匹配的角度來說,卷積核定義了某種模式,卷積運算是在計算每個位置與該模式的相似程度,或者說每個位置具有該模式的分量有多少,當前位置與該模式越像,回應越強,
比如用邊緣檢測算子來做卷積,sobel 算子包含兩組 3*3 的矩陣,分別為橫向及縱向,將之與影像作平面卷積,如果以A代表原始影像,G(x) 及 G(y) 分別代表經橫向及縱向邊緣檢測的影像:
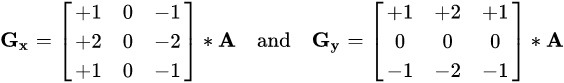
sobel 偏 x 方向的邊緣檢測計算結果如下所示:

再看一些直觀表現不同卷積核算子效果的栗子,

是不是感覺卷積大法好,當然,我們可以直接找一些有趣的卷積核來用,比如用卷積來檢測影像邊緣,也可以通過資料來學習卷積核,讓神經網路來學習到不同的算子,
剛剛在卷積計算的時候,每次滑動了一個小格,也就是 stride 步伐為 1,其實也可以把步伐加大,每次滑動 2 個小格,也可以跳著取值,來擴大感受野,也可以為了保持輸出陣列的長寬與輸入一致,在原圖邊緣加一圈 padding ,作為最最基礎的入門,這里就不展開了,
回到我們的網路結構,可以看到兩層神經元間只有部分連接了,更少的連接,代表更少的引數,
但是這樣還不夠,圖片像素太多,哪怕我們只對區域取特征,依舊需要許多許多的引數,所以還需要池化(pooling),
池化層的作用其實就是下采樣,縮小圖片,池化的計算也非常的簡單,對輸出資料的一個固定大小視窗的元素進行計算,然后輸出,最大池化(Max Pooling) 就是取池化視窗內元素的最大值,平均池化則是取輸入視窗的元素的平均值,
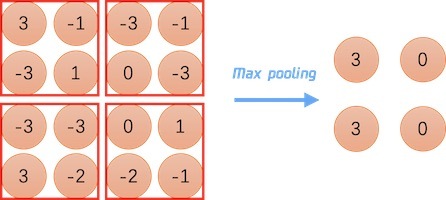
除了下采樣,減小圖片大小,池化還可以緩解卷積層對位置的過度敏感性,避免模型過擬合,舉一個極端的例子,一張圖片只有四個像素,如果某個位置像素為 255 ,我們就判定是某個型別的物品,如果我們輸入的用來學習的訓練集圖片中,每張圖片都是左上角第一個像素為 255 ,如果沒有池化,模型訓練的結果就是,當左上角第一個像素為 255 ,那么輸出判斷為該物品,當我們用這個模型去預測一張右上角像素為255的圖片,模型會認為不是該物體,判斷錯誤,而如果有池化,不管 255 出現在哪一個位置,池化后都會取到 255,判斷為是該物品,
經過多個卷積層和池化層降維,資料就來到了全連接層,進行高層級抽象特征的分類啦,
最后
到這里,應該已經介紹完看懂 Pytorch / Tensorflow 官網入門教程所需要的絕大部分原理知識了,可以愉快的跑官網的圖片分類示例然后寫自己的網路了,
具體框架使用那就下篇《超基礎的機器學習入門-實踐篇》見,
最后的最后
Deco 智能代碼專案是凹凸實驗室在「前端智能化」方向上的探索,我們嘗試從設計稿生成代碼(DesignToCode)這個切入點入手,對現有的設計到研發這一環節進行能力補全,進而提升產研效率,其中使用到不少AI能力來實作設計稿的決議與識別,感興趣的童鞋歡迎關注我們的賬號「凹凸實驗室」(知乎、掘金),
參考資料
- http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML19.html
- 如何估算深度神經網路的最優學習率
- 卷積神經網路之卷積計算、作用與思想
- 數字影像 - 邊緣檢測原理 - Sobel, Laplace, Canny算子
- https://zh.wikipedia.org/wiki/%E7%B4%A2%E8%B2%9D%E7%88%BE%E7%AE%97%E5%AD%90
- https://medium.com/@pkqiang49/%E4%B8%80%E6%96%87%E7%9C%8B%E6%87%82%E5%8D%B7%E7%A7%AF%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C-cnn-%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86-%E7%8B%AC%E7%89%B9%E4%BB%B7%E5%80%BC-%E5%AE%9E%E9%99%85%E5%BA%94%E7%94%A8-6047fb2add35
- http://cs231n.stanford.edu/
歡迎關注凹凸實驗室博客:aotu.io
或者關注凹凸實驗室公眾號(AOTULabs),不定時推送文章:

轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/373926.html
標籤:JavaScript
上一篇:全新Java入門到架構師教程之JavaScript函式定義、函式引數和呼叫
下一篇:react 性能優化