我有一個這樣的資料集(樣本)
data.frame(loan_status=c('Y','N','Y','N','Y','N'), property_area=c('Semiurban', 'Urban', 'Rural', 'Semiurban', 'Urban', 'Rural'))
這loan_status=='Y'意味著貸款被接受。
我想繪制 each 的接受百分比property_area,如下所示:
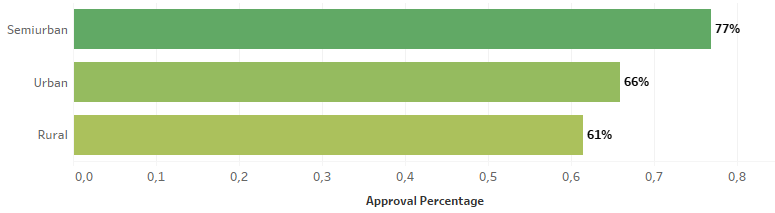
我嘗試使用 ggplot 庫但沒有成功。
最簡單的方法是什么?
uj5u.com熱心網友回復:
這是一個基本的 R解決方案,包括根據百分比改變色調。我擴展您的資料以顯示不同的百分比,而不僅僅是 50%。另外,我將“Y”改為TRUE“N” FALSE。
# adjust data
df1$loan_status[df1$loan_status == "Y"] <- T
df1$loan_status[df1$loan_status == "N"] <- F
# get groups
pl <- aggregate( loan_status ~ property_area, df1, function(x)
sum(as.logical(x))/length(x) )
# adjust plotting area
par(mar=c(14,6,14,4))
# plot data, add percentages and grid
bp <- barplot( pl$loan_status,
names=pl$property_area,
horiz=T, border=F, las=1,
col=rgb(0.1, 1-pl$loan_status, 0.1, 1),
xlim=c(0,1.14) );
text(pl$loan_status, bp, labels=paste(round(pl$loan_status*100, digits=2),"%"), pos=4);
abline(v = seq(0,1,by=0.2), col = "grey", lty = "dotted")
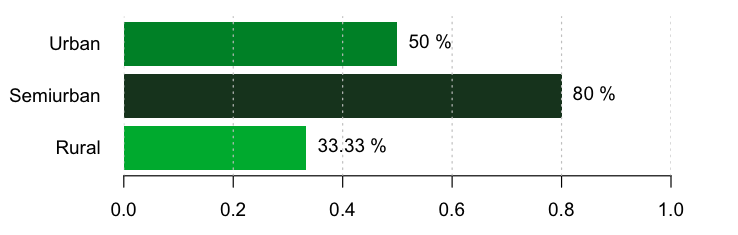
資料
df1 <- structure(list(loan_status = c("Y", "N", "Y", "N", "Y", "N",
"Y", "Y", "Y", "N"), property_area = c("Semiurban", "Urban",
"Rural", "Semiurban", "Urban", "Rural", "Semiurban", "Semiurban",
"Semiurban", "Rural")), row.names = c("1", "2", "3", "4", "5",
"6", "7", "8", "9", "10"), class = "data.frame")
uj5u.com熱心網友回復:
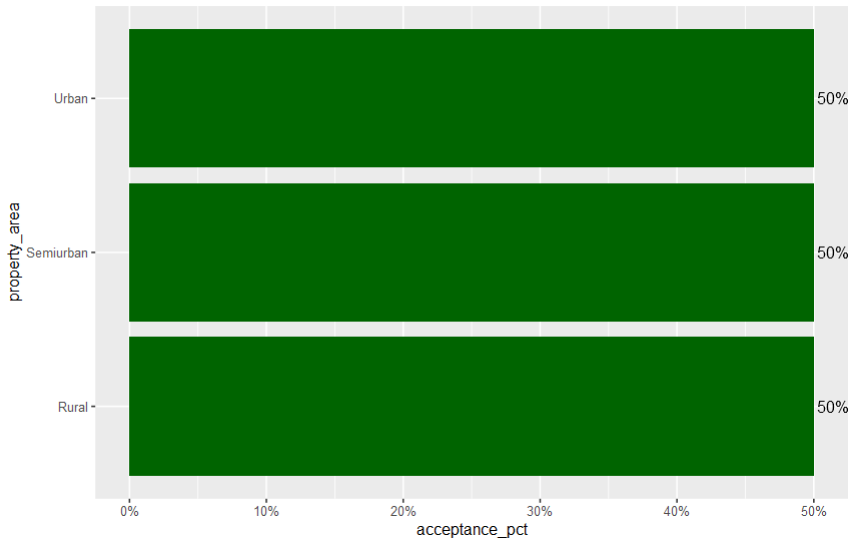
你可以從這樣的事情開始。該scales庫允許輕松地將標簽轉換為百分比。
library(scales); library(ggplot2); library(dplyr)
df %>% group_by(property_area) %>%
summarise(acceptance_pct = sum(loan_status == 'Y') / n()) %>%
ggplot(aes(x = acceptance_pct, y = property_area))
geom_col(fill = "darkgreen")
geom_text(aes(label = percent(acceptance_pct)), hjust = -0.1)
scale_x_continuous(labels = percent_format(accuracy = 1))
uj5u.com熱心網友回復:
你能從這個開始嗎?
p = ggplot(mydataf, aes(y = foo))
geom_bar(aes(x = (..count..)/sum(..count..)))
scale_x_continuous(formatter = 'percent')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/375186.html
標籤:r