有一個點的陣列,如下所示。點集合中有列結構。
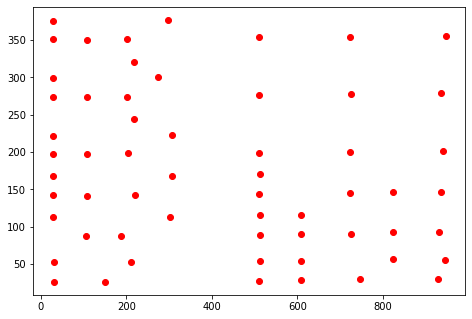
如何將這些點分組到不同的列中?
np.array([[151, 26],[ 30, 26],[511, 27],[747, 30],[609, 28],[930, 30],
[ 30, 52],[211, 53],[513, 54],[608, 54],[824, 56],[946, 55],
[106, 87],[187, 87],[512, 89],[609, 90],[725, 90],[823, 92],
[931, 92],[ 28, 113],[301, 113],[512, 115],[609, 116],[ 28, 142],
[107, 141],[220, 142],[511, 143],[724, 145],[823, 146],[937, 146],
[ 29, 168],[308, 168],[512, 171],[ 28, 197],[107, 197],[205, 198],
[511, 199],[724, 200],[940, 201],[ 29, 222],[307, 223],[217, 244],
[107, 273],[ 28, 274],[201, 273],[511, 276],[725, 277],[937, 279],
[ 28, 299],[273, 301],[218, 321],[ 28, 351],[107, 350],[201, 351],
[511, 354],[723, 354],[947, 356],[ 29, 376],[297, 377]])
預期輸出是
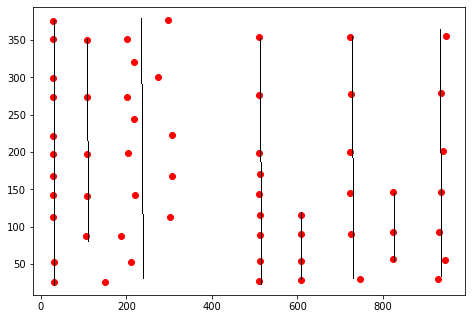
其中線代表視覺上形成一列的每組坐標。
提前感謝您的時間——如果我遺漏了任何東西,過分強調或過分強調某個特定點,請在評論中告訴我。
uj5u.com熱心網友回復:
要按點對列進行分組(按 x 分組),您可以執行以下操作。
xy = np.array([
[151, 26],[ 30, 26],[511, 27],[747, 30],[609, 28],[930, 30],
[ 30, 52],[211, 53],[513, 54],[608, 54],[824, 56],[946, 55],
[106, 87],[187, 87],[512, 89],[609, 90],[725, 90],[823, 92],
[931, 92],[ 28, 113],[301, 113],[512, 115],[609, 116],[ 28, 142],
[107, 141],[220, 142],[511, 143],[724, 145],[823, 146],[937, 146],
[ 29, 168],[308, 168],[512, 171],[ 28, 197],[107, 197],[205, 198],
[511, 199],[724, 200],[940, 201],[ 29, 222],[307, 223],[217, 244],
[107, 273],[ 28, 274],[201, 273],[511, 276],[725, 277],[937, 279],
[ 28, 299],[273, 301],[218, 321],[ 28, 351],[107, 350],[201, 351],
[511, 354],[723, 354],[947, 356],[ 29, 376],[297, 377]])
n = np.unique(xy[:,0])
cols = { i: list(xy[xy[:,0]==i,1]) for i in n }
這將創建一個包含列作為鍵及其對應的 y 值的字典。如果您想按 y 分組以獲取行,那么您只需翻轉 0 和 1,即可按 y 分組。
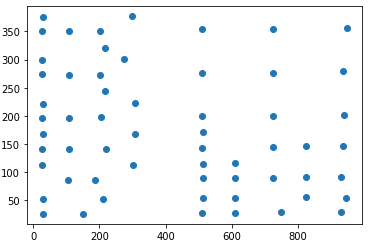
然后,要重新列印圖形,您可以這樣做(可能有更好的方法)
x, y = np.array([]), np.array([])
for i in cols.items():
x = np.append(x, [i[0]] * len(i[1]))
y = np.append(y, (i[1]))
plt.scatter(x, y)
plt.show()
回傳原始圖形。
uj5u.com熱心網友回復:
從頭開始
# Create variables
grouped = []
unique = {}
# Get all unique x values and store y as array in dictionary
for point in points:
unique[point[0]] = unique.get(point[0], []) point[1]
# Convert the x's into columns of points
for x in unique:
grouped.append([[x, y] for y in unique[x]])
# Extra polishing
grouped = np.array(grouped)
這將創建一個新的 NumPy 陣列:
data = [columns [points within columns]]
請注意,這不會處理重新繪制,因為沒有為該部分提供足夠的資訊,只提供了分組。
uj5u.com熱心網友回復:
您可以使用 defaultdict 將您在列中找到的每個點附加到串列中。
from collections import defaultdict
d = defaultdict(list)
for point in array:
x, _ = point
d[x].append(point)
grouped_by_columns = list(d.values())
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/376358.html
上一篇:如何重新排序dstack
下一篇:使用Pandas反轉復雜的列和行