這個問題與
我的問題是,每當我計算分箱平均值(也調整分箱)時,結果主要是nan值,因為我的資料包含nan我不想丟棄的s間隔。這是一些重現問題的代碼:
from scipy.stats import binned_statistic
import numpy as np
#defining a generic data similar to mine
a=np.array([0.1, 0.15, 0.17, 0.2, 0.3, 0.4, np.nan, 0.12, 0.15, 0.17, 0.22, np.nan, 0.37, np.nan, 0.12, 0.15, 0.17, 0.17, 0.35, 0.42, np.nan])
b=np.linspace(1,len(a),len(a))
plt.scatter(b,a)
plt.hlines(np.nanmean(a),b[0],b[-1], linestyles='--')
plt.show() #you can uncomment this line to separate the plots.
#filtering nans
nana= a[~np.isnan(a)]
nanb= np.linspace(1,len(nana),len(nana))
plt.scatter(nanb,nana, marker='o')
plt.hlines(np.nanmean(a),b[0],b[-1], linestyles='--')
#calculating a binned mean
bmean_nana = binned_statistic(nanb, nana,
statistic='mean',
bins=3,
range=(0, len(nana)))
bin_centers = bmean_nana.bin_edges[1:] - (abs(bmean_nana.bin_edges[0]-bmean_nana.bin_edges[1]))/2
plt.scatter(bin_centers, bmean_nana.statistic, marker='x', s=90)
帶輸出:
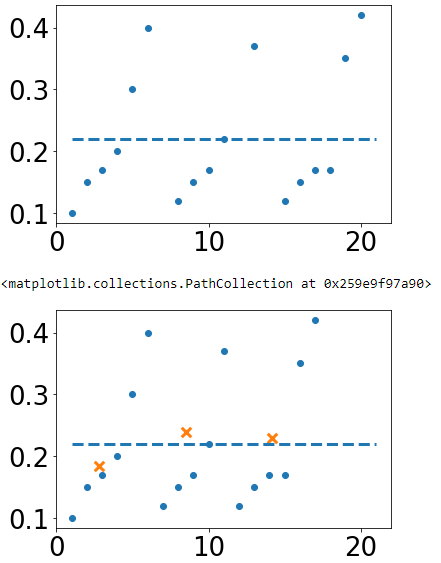
當分箱均值與a資料一起繪制時,您可以看到計算不匹配(這是有道理的)。問題 1:是否有一個簡單的通用解決方案來執行分箱均值忽略nan值?
一些注意事項:
- 這里有一個分箱演算法有一個
nanHandling : None選項
‘ignore’: In this case, NaNs contained in the input data are removed from the data prior binning. Note however, that x0, unless specified explicitly, will still refer to the first data point, whether or not this holds a NaN value.
- Also there's an issue reported in GitHub: "scipy.stats.binned_statistic regressed in v1.4.0 #11365" in which
barentsenreports that
PR #10664 recently changed the behavior of scipy.stats.binned_statistic to raise a ValueError whenever the data contains a non-finite number (e.g.,
nan,inf). This new behavior is counter-intuitive because many other statistical methods do not raise exceptions in the presence of NaNs, e.g.np.mean([np.nan])returnsnanrather than raising an exception.
and
(...) 用戶可以通過提供自定義統計函式來選擇忽略 NaN,例如
np.nanmean:
>>> import scipy.stats, numpy as np
>>> x = [0.5, 0.5, 1.5, 1.5]
>>> values = [10, 20, np.nan, 40]
>>> scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
截至
SciPy v1.4.0, 上面的例子提出了這個ValueError
>>> scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/gb/bin/anaconda/envs/sp14/lib/python3.7/site-packages/scipy/stats/_binned_statistic.py", line 180, in binned_statistic
[x], values, statistic, bins, range)
File "/home/gb/bin/anaconda/envs/sp14/lib/python3.7/site-packages/scipy/stats/_binned_statistic.py", line 519, in binned_statistic_dd
raise ValueError('%r or %r contains non-finite values.' % (sample, values,))
ValueError: [[0.5, 0.5, 1.5, 1.5]] or [10, 20, nan, 40] contains non-finite values.
問題2:有沒有簡單的使用方法statistic=np.nanmean?
uj5u.com熱心網友回復:
問題 1 和 2 的答案都是np.nanmean用于忽略nan資料中的s。您鏈接到的回歸是我無意中引入的一個錯誤,然后在它提出后修復。我不確定為什么你的環境中有 SciPy 1.5.2,看起來1.5.4 是最新的 1.5.X 版本,所以你可能想要更新你正在使用的環境。但是,該向后移植已應用于 1.5.0 版發布版本,因此如果您擁有最新版本,這些版本應該不會有問題。
此外,我使用 scipy 版本 1.7.3 進行了設定,這也適用于我的預期。這里是片段。
版本 1.5.4
import scipy
scipy.__version__
'1.5.4'
import numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
版本 1.7.3
import scipy
scipy.__version__
'1.7.3'
import scipy.stats, numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
版本 1.5.2
import scipy
scipy.__version__
'1.5.2'
import scipy.stats, numpy as np
x = [0.5, 0.5, 1.5, 1.5]
values = [10, 20, np.nan, 40]
scipy.stats.binned_statistic(x, values, statistic='mean', bins=(0, 1, 2)).statistic
array([15., nan])
scipy.stats.binned_statistic(x, values, statistic=np.nanmean, bins=(0, 1, 2)).statistic
array([15., 40.])
請嘗試使用.__version__來確認您的 SciPy 版本。如果它是 1.4.1 版本 - 它沒有變化。我懷疑您的版本是 1.4.1 而不是其他(更高)版本。請使用上面代碼示例的部分來確認您的環境中使用的 scipy 版本。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/376360.html
上一篇:使用Pandas反轉復雜的列和行
下一篇:Numpy:遞回生成矩陣