我得到了一些丑陋的資料。我有一個帶有列 C 的資料框,它的值是 ea 的字串。排。但是,它有點復雜。字串如下所示。

是的,它們是字串。不,絕對不是字串集串列……完全是字串。
我想遍歷 ea。行并從具有 cat=1 和 cat=2 的集合(實際上是字串)中獲取“資訊”值(實際上是字串)以創建兩個要填充的新列。我想要的是:
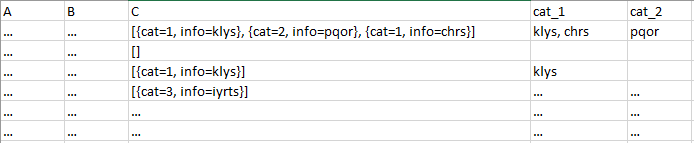
想法?
uj5u.com熱心網友回復:
您可以像這樣清理:
temp = df['C'].str.strip('[]').str.split('}, ').explode()
df['cat_1'] = temp.apply(lambda x: x[13:].strip('}') if x[1:6]=='cat=1' else '').reset_index().groupby('index').agg(lambda x: ', '.join(x))['C'].str.strip(', ')
df['cat_2'] = temp.apply(lambda x: x[13:].strip('}') if x[1:6]=='cat=2' else '').reset_index().groupby('index').agg(lambda x: ', '.join(x))['C'].str.strip(', ')
輸出:
C cat_1 cat_2
0 []
1 [{cat=1, data=adjks}, {cat=1, data=pqoek}, {ca... adjks, pqoek hjksy
2 []
3 [{cat=1, data=alpqi}] alpqi
4 [{cat=5, data=weee}, {cat=6, data=wolpwolp}]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/380857.html