我知道這個問題之前已經回答過,但它沒有做我想要它做的事情。我在 R 中有一個資料框。我想在不同類別之間建立配對點。資料框是:
sample <- data.frame(city_name = c(rep('Wahsington',10),rep('Seattle',10)),
experience = rep(c("ten","five"),5),
test = rep(c('manager','manager','team lead','team lead',
'CFO','CFO','CEO','CEO','Executive',
'Executive'),2),
score = c(87.10,27.20,98.15,67.20,68.30,23.00,78.75,49.30,63.30,37.90,
69.10,20.20,90.65,56.05,69.40,47.35,52.55,37.85,
70.90,47.75))
為了繪制成對的點,我這樣做:
options(repr.plot.width=30, repr.plot.height=8)
ggplot(sample, aes(x = test, y = score, group = test))
geom_line()
geom_point(size = 2, aes(color = experience))
facet_wrap(~ city_name)
scale_x_discrete("")
theme_minimal()
ylab('Score') xlab('') theme(axis.text.x=element_text(angle = 90, hjust = 0))
我得到的情節看起來像:
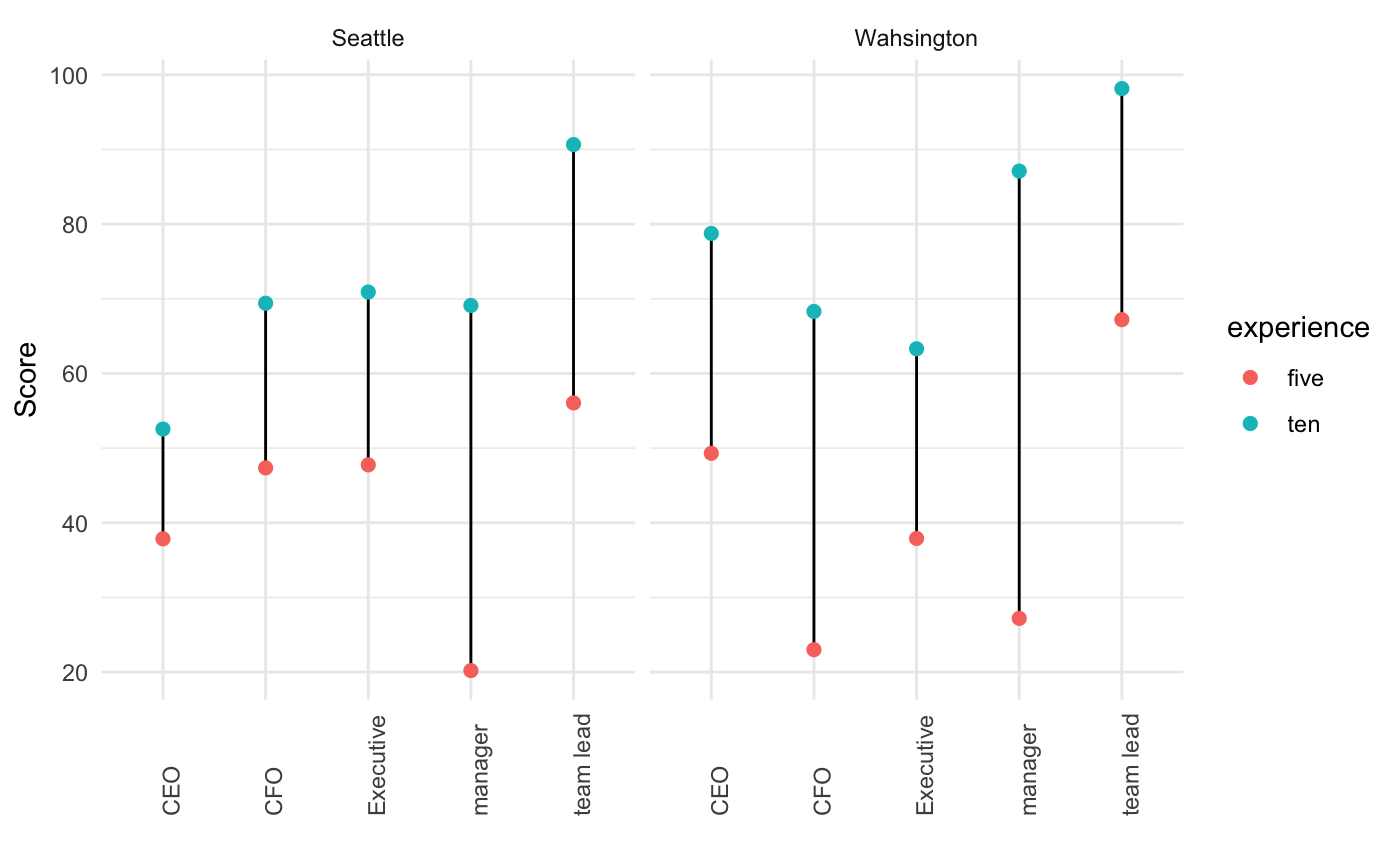
但是,我將這些配對點不低于彼此,而是為了美學目的而有點傾斜,如這里,但對于不同的類別,如在 x 軸上注釋的“CFO”和“CEO”,如第一張圖所示:
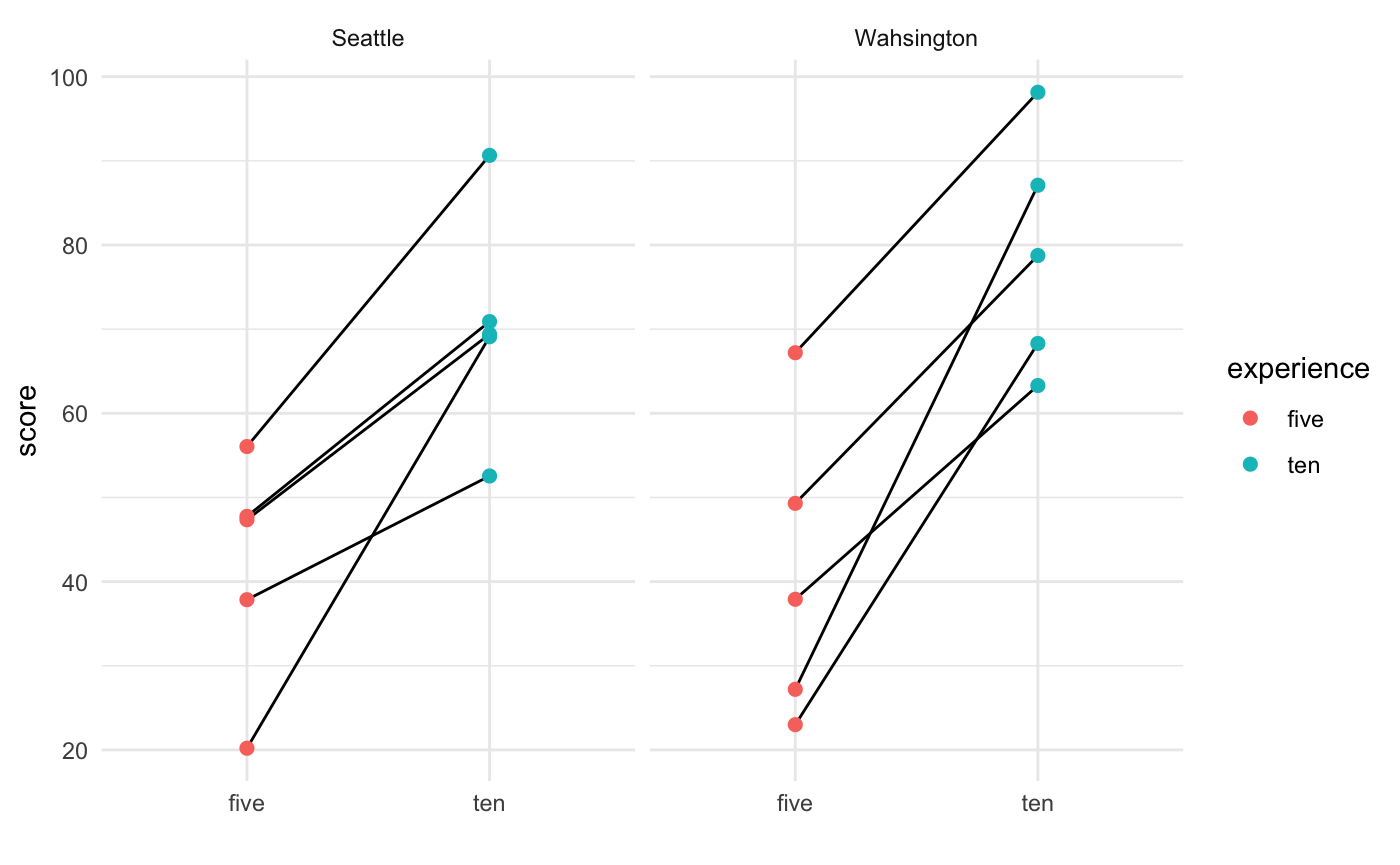
如何在 R 中使用 ggplot 實作這一目標?
編輯:這是我想要實作的一個例子:
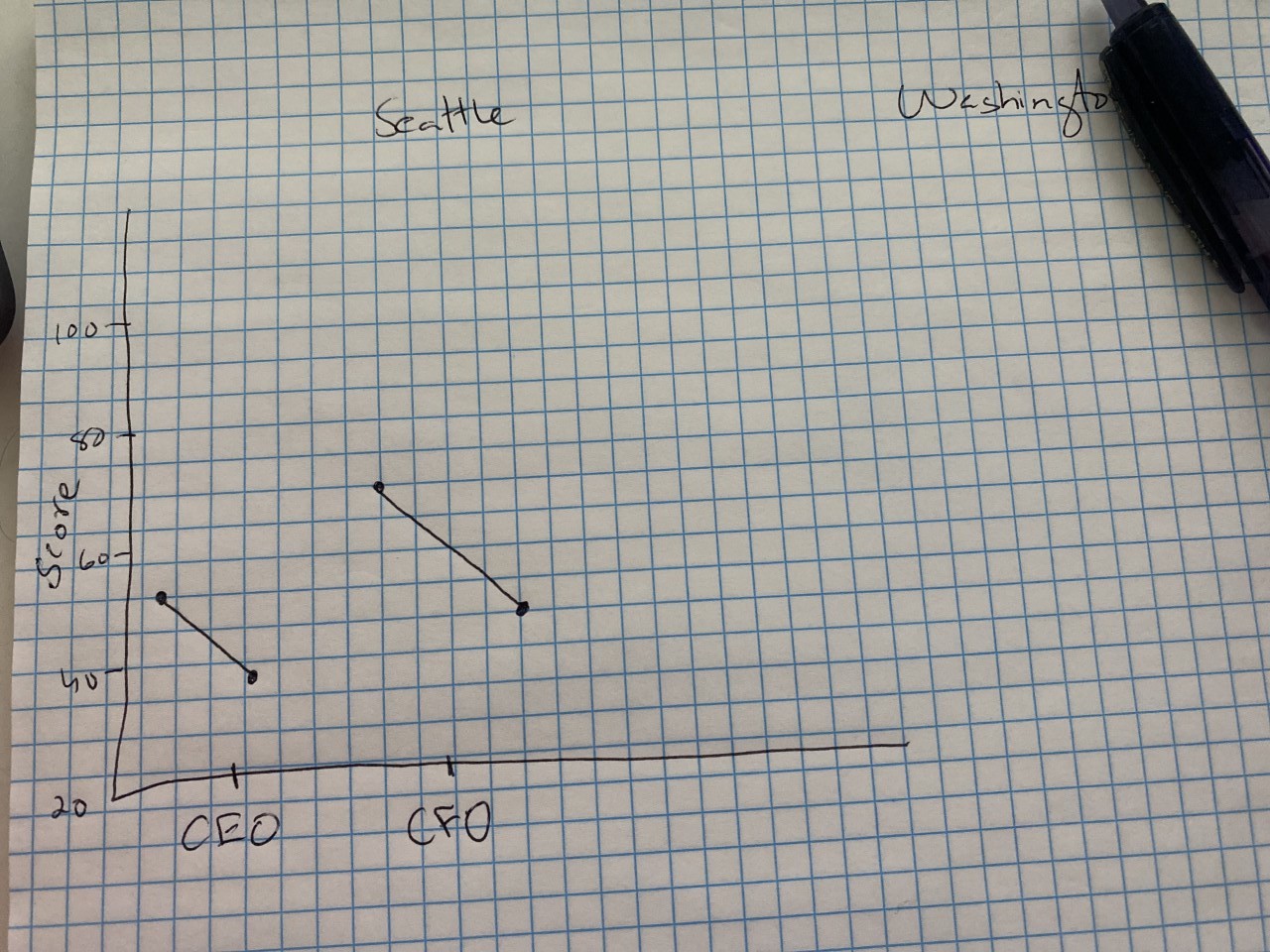
uj5u.com熱心網友回復:
另一種選擇是使用嵌套分面(使用 {ggh4x})。(它并沒有真正給出您想要的外觀,而只是指出該選項)。另請參閱下文,了解有關使用散點圖可視化配對資料的不同方式的建議。
library(tidyverse)
library(ggh4x)
## bad idea to call an object like a very commonly used function (sample)
## df is also a function, but much less commonly used
df <- data.frame(city_name = c(rep('Wahsington',10),rep('Seattle',10)),
experience = rep(c("ten","five"),5),
test = rep(c('manager','manager','team lead','team lead',
'CFO','CFO','CEO','CEO','Executive',
'Executive'),2),
score = c(87.10,27.20,98.15,67.20,68.30,23.00,78.75,49.30,63.30,37.90,
69.10,20.20,90.65,56.05,69.40,47.35,52.55,37.85,
70.90,47.75))
ggplot(df, aes(x = experience, y = score, group = test))
geom_line()
geom_point(size = 2, aes(color = experience))
facet_nested(~ city_name test)
## one call to labs reduces the code to relabel the axis
labs(x = NULL, y = "Score")
theme_minimal()
theme(axis.text.x=element_blank())
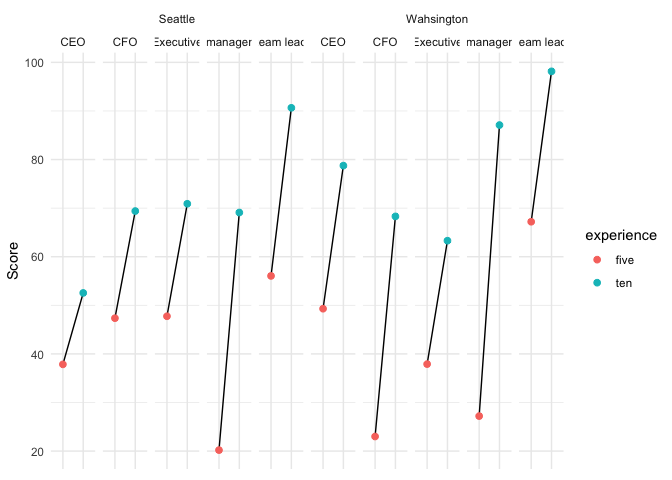
散點圖可以更引人注目地可視化配對資料
df_wide <-
df %>%
pivot_wider(names_from = experience, values_from = score)
lims <- c(0, 100)
ggplot(df_wide, aes(five, ten, color = test))
geom_point()
geom_abline(slope = 1, intercept = 0)
ggrepel::geom_text_repel(aes(label = test))
scale_color_brewer(NULL, palette = "Set1")
facet_grid(~city_name)
coord_equal(xlim = lims, ylim = lims)
cowplot::theme_minimal_grid()
theme(legend.position = "none")
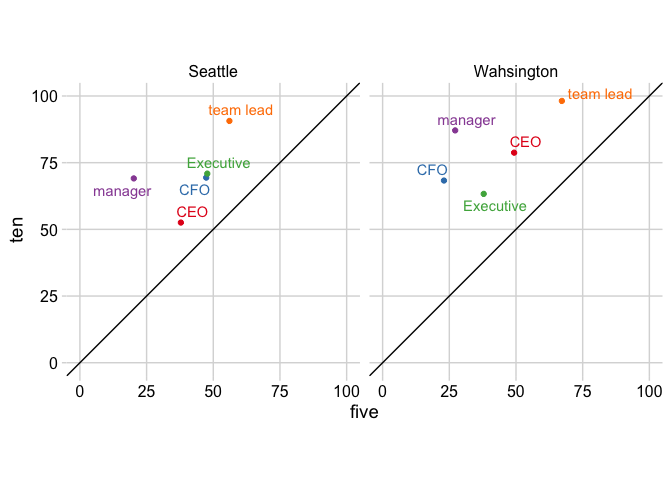
由reprex 包(v2.0.1)于 2021 年 12 月 12 日創建
uj5u.com熱心網友回復:
一種方法是使 x 軸連續以獲得經驗值和測驗值;當經驗為“十”時使用 x 偏移量。
library(ggplot2)
library(dplyr)
offset = 0.4
# modify the data to allow for x values to control the location of points and line ends.
df <-
df %>%
group_by(city_name, experience) %>%
arrange(city_name, experience, test) %>%
mutate(x = as.numeric(row_number()),
x_lab_pos = x 0.5 * offset,
x = if_else(experience == "ten", x offset, x))
x_breaks <- sort(unique(df$x_lab_pos))
x_label <- sort(unique(df$test))
ggplot(df, aes(x = x, y = score, group = test))
geom_line()
geom_point(size = 2, aes(color = experience))
facet_wrap(~ city_name)
scale_x_continuous(breaks = x_breaks,
labels = x_label)
theme_minimal()
labs(x = NULL,
y = 'Score')
theme(axis.text.x=element_text(angle = 90, hjust = 0))
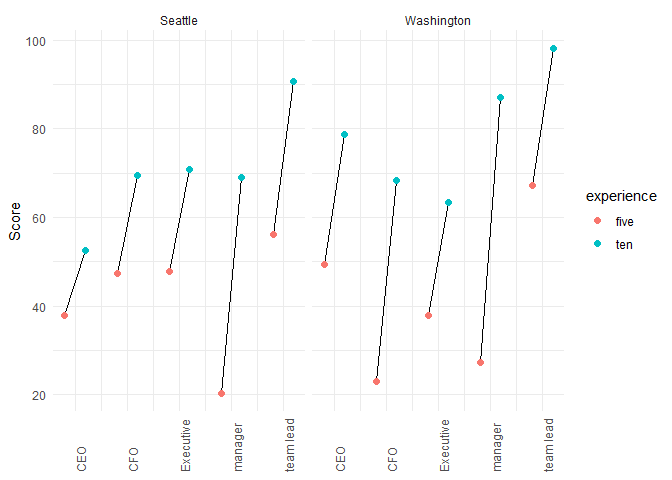
由reprex 包(v2.0.1)于 2021 年 12 月 12 日創建
資料
df <- data.frame(city_name = c(rep('Washington',10),rep('Seattle',10)),
experience = rep(c("ten","five"),5),
test = rep(c('manager','manager','team lead','team lead',
'CFO','CFO','CEO','CEO','Executive',
'Executive'),2),
score = c(87.10,27.20,98.15,67.20,68.30,23.00,78.75,49.30,63.30,37.90,
69.10,20.20,90.65,56.05,69.40,47.35,52.55,37.85,
70.90,47.75))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/381235.html
上一篇:錯誤:提供給連續尺度問題的離散值