我有這樣的清單(簡化版):
data = [{'layer1': [{'idx': 'idx_102',
'size': 8 },
{'idx': 'idx_112',
'size': 25 },
{'idx': 'idx_142',
'size': 10 }]
},
{'layer2': [{'idx': 'idx_125',
'size': 28 },
{'idx': 'idx_258',
'size': 21 },
{'idx': 'idx_658',
'size': 12 }]
},
{'layer3': [{'idx': 'idx_158',
'size': 78 }]
}]
excel檔案的結構應該是這樣的:
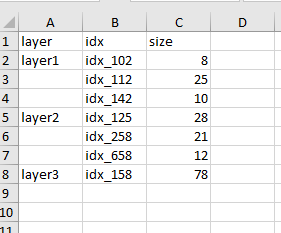
有人可以幫忙嗎,我迷失了熊貓
uj5u.com熱心網友回復:
將嵌套串列與字典推導結合使用:
L = [{**{'layer': k}, **x} for d in data for k, v in d.items() for x in v]
df = pd.DataFrame(L)
print (df)
layer idx size
0 layer1 idx_102 8
1 layer1 idx_112 25
2 layer1 idx_142 10
3 layer2 idx_125 28
4 layer2 idx_258 21
5 layer2 idx_658 12
6 layer3 idx_158 78
最后如果需要洗掉重復項:
df.loc[df['layer'].duplicated(), 'layer'] = ''
print (df)
layer idx size
0 layer1 idx_102 8
1 idx_112 25
2 idx_142 10
3 layer2 idx_125 28
4 idx_258 21
5 idx_658 12
6 layer3 idx_158 78
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/387634.html