我有 2 個資料框 df1 和 df2。
import pandas as pd
df1 = pd.DataFrame({
'id':['1','1','1','2','2','2', '3', '4','4', '5', '6', '7'],
'group':['A','A','B', 'A', 'A', 'C', 'A', 'A', 'B', 'B', 'A', 'C']
})
df2 = pd.DataFrame({
'id':['1','2','3','4','5','6','7']
})
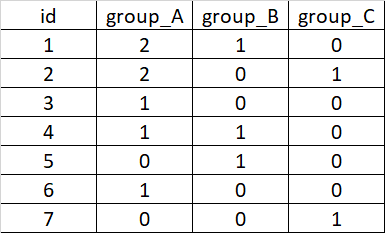
我想向 df2 添加 3 列,名為 group_A、group_B 和 group_C,其中每列根據 id 列計算 df1 中每個組的重復次數。所以 df2 的結果應該是這樣的:
uj5u.com熱心網友回復:
使用crosstabwith DataFrame.join,兩者的型別id必須相同,就像這里的字串:
print (pd.crosstab(df1['id'], df1['group']).add_prefix('group_'))
group group_A group_B group_C
id
1 2 1 0
2 2 0 1
3 1 0 0
4 1 1 0
5 0 1 0
6 1 0 0
7 0 0 1
df = df2.join(pd.crosstab(df1['id'], df1['group']).add_prefix('group_'), on='id')
print (df)
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
如果id兩個DataFrames 中的 s相同,則無需連接的解決方案是可能的:
print (pd.crosstab(df1['id'], df1['group']).add_prefix('group_').reset_index().rename_axis(None, axis=1))
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
uj5u.com熱心網友回復:
一種選擇是在加入 df1 之前獲取 df2 的計數:
counts = df1.value_counts().unstack(fill_value=0).add_prefix('group_')
df2.join(counts, on='id')
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
另一種選擇是與get_dummies,結合groupby:
counts = pd.get_dummies(df1, columns = ['group']).groupby('id').sum()
df2.join(counts, on='id')
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
uj5u.com熱心網友回復:
另一個選項是groupbyon ['id', 'group']、 applysize和unstack。
out = (df1.groupby(['id','group']).size().unstack(fill_value=0)
.add_prefix('group_').reset_index().rename_axis([None], axis=1)
.merge(df2, on='id'))
輸出:
id group_A group_B group_C
0 1 2 1 0
1 2 2 0 1
2 3 1 0 0
3 4 1 1 0
4 5 0 1 0
5 6 1 0 0
6 7 0 0 1
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/387639.html
上一篇:索引錯誤和屬性錯誤