我有一個包含多行和多列的資料框,我已將其轉換為一個 numpy 陣列以加快計算速度。Dataframe 的前五列如下所示:
par1 par2 par3 par4 par5
1.502366 2.425301 0.990374 1.404174 1.929536
1.330468 1.460574 0.917349 1.172675 0.766603
1.212440 1.457865 0.947623 1.235930 0.890041
1.222362 1.348485 0.963692 1.241781 0.892205
...
這些列現在存盤在一個 numpy 陣列中 a = df.values
我需要檢查五列中是否至少有兩列滿足條件(即,它們的值大于某個閾值)。最初我撰寫了一個直接在資料幀上執行操作的函式。但是,因為我的資料量非常大,需要一遍遍地重復計算,所以我切換到 numpy 以利用矢量化。
檢查我想使用的條件
df['Result'] = np.where(condition_on_parameters > 2, True, False)
但是,condition_on_parameters當 5 個引數中至少有 2 個大于閾值時,我無法弄清楚如何撰寫它以回傳 True 或 False。我想在 上使用該sum()函式,condition_on_parameters但我不確定如何撰寫這樣的條件。
編輯
指定每個引數的閾值不同很重要。例如thr1=1.2, thr2=2.0, thr3=1.5, thr4=2.2, thr5=3.0。所以我需要檢查 par1 > thr1, par2 > thr2, ..., par5 > thr5。
uj5u.com熱心網友回復:
假設condition_on_parameters回傳一個a與條目大小相同的陣列Trueor False,您可以使用np.sum(condition_on_parameters, axis=1)對True每行的真實值(數值為 1)求和。這提供了一個一維陣列,其中條目為滿足條件的列數。然后可以使用此陣列where來獲取您要查找的行號。
df['result'] = np.where(np.sum(condition_on_parameters, axis=1) > 2)
uj5u.com熱心網友回復:
看來您正在尋找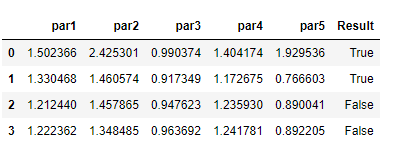
uj5u.com熱心網友回復:
你能利用熊貓的功能嗎?例如,您可以使用.apply和 然后有效地檢查多行/列上的條件.sum(axis=1)。
這里有一些示例代碼:
import pandas as pd
df = pd.DataFrame([[1.50, 2.42, 0.88], [0.98,1.3, 0.56]], columns=['par1', 'par2', 'par3'])
# custom_condition, e.g. value less or equal than threshold
def leq(x, t):
return x<=t
condition = df.apply(lambda x: leq(x, 1)).sum(axis=1)
# filter
df.loc[condition >=2]
我認為這在效率方面應該等同于 numpy,因為 Pandas 最終建立在它之上,但是我不完全確定......
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/390644.html