我正在嘗試使用前瞻來檢查字串是否在任何位置包含模式,但是,我很難理解它。
該模式(?=.*px)[\d] 應該匹配(根據我的理解)任何在字母 p 和 x 之前或之后也有的數字(作為組,因此 12 將是一個匹配),無論位置 ( .*)。
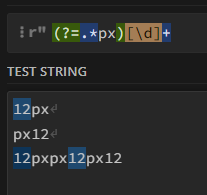
該模式在使用“12px”時按預期作業,匹配 12 但不匹配 px。但是,如果我使用 px12,它就不再匹配 12,我很難理解為什么。此外,字串“12pxpx12px12”匹配第一個和第二個 12,因為后面都有 px,但不是最后一個。
以下是一些示例供參考:
如果有人能夠向我解釋我期待實作的目標以及撰寫正則運算式的正確方法有什么問題,我將不勝感激。
uj5u.com熱心網友回復:
前瞻(?=px)意味著“緊跟在這一點之后的子串是px”,并\d 意味著“此時的子串是多個數字”。這些是相互不兼容的陳述。Lookarounds 是零寬度斷言,這意味著如果您想在像 那樣的具體斷言之前匹配某些內容\d ,則不能使用lookahead,您需要使用lookbehind。
在我的腦海中,我能想到的最佳解決方案是使用異或:
(?<=px)\d |\d (?=px)
在 regex101 上試試
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/398909.html
標籤:Python 正则表达式 regex-lookarounds
下一篇:從FileProvider.getUriForFile()檢索的imageUri在imageView上設定但顯示空ImageView