一、前言
在軟體發開技術管理里有兩個永恒經典的問題,適合我們初到一家軟體企業或一家公司的科技團隊,來判斷自己該從哪里入手幫助整個團隊提升科技水平和產能,問題一是“在我們團隊里,只涉及一行代碼的變更需要多久才能上線?”,問題二是“在我們團隊里,定位一個線上問題需要多久?流程是什么?”,問題一關注的是“交付”,問題二關注的是“保障”,今天寫這邊文章跟大家聊聊有關問題二的故事,
不怕大家笑話,我最初的公司每個服務生產上就兩臺Tomcat,定位生產問題,就是連上一臺機器,然后用使用 cd / tail / grep / sed / awk 等 Linux 腳本去日志里查找故障原因,如果發現不在這臺機器上,就去另一臺機器上查日志,(如果你現在的公司還是這樣干,記住出去面試的時候也不要說是這樣干,不然很容易由于你之前的公司的整體技術水平太low而把你pass掉)
但在應用服務器規模較大的場景中,此方法效率低下,面臨問題包括日志量太大如何歸檔、文本搜索太慢怎么辦、如何多維度查詢,需要集中化的日志管理,所有服務器上的日志收集匯總,常見解決思路是建立集中式日志收集系統,將所有節點上的日志統一收集,管理,訪問,一般大型系統是一個分布式部署的架構,不同的服務模塊部署在不同的服務器上,問題出現時,大部分情況需要根據問題暴露的關鍵資訊,定位到具體的服務器和服務模塊,構建一套集中式日志系統,可以提高定位問題的效率,
以搜索引擎聞名世界的開源軟體提供商-Elastic為我們大家提供了一套完整的日志收集以及展示的解決方案——ELK,是三個產品的首字母縮寫,分別是ElasticSearch、Logstash 和 Kibana,
二、ELK簡介
Logstash主要是用來負責搜集、分析、過濾日志的工具,支持大量的資料獲取方式,一般作業方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責將收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去,
ElasticSearch用來負責存盤最終資料、建立索引和對外提供搜索日志的功能,它是個開源分布式搜索引擎,提供搜集、分析、存盤資料三大功能,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
Kibana是一個優秀的前端日志展示框架,它可以非常詳細的將日志轉化為各種圖表,為用戶提供強大的資料可視化支持,

三、不同級別的ELK架構
1、入門級
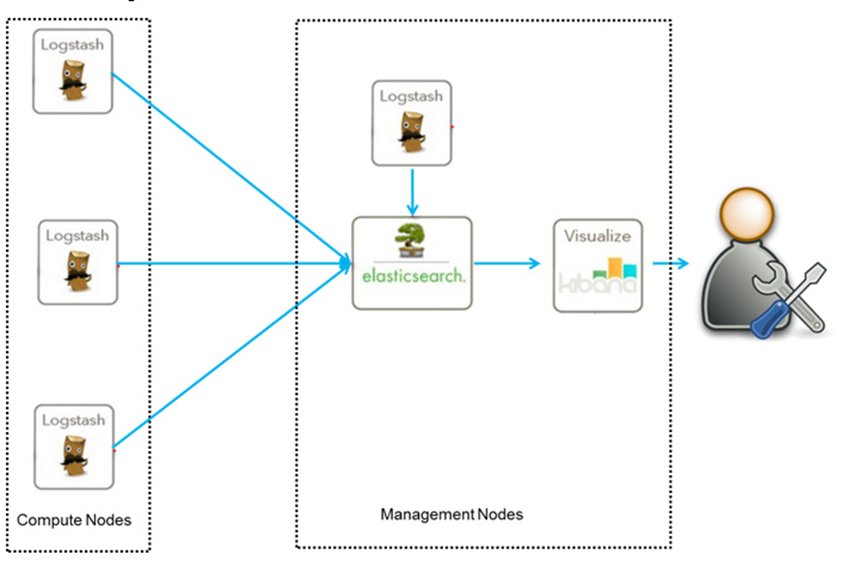
這是最簡單的ELK架構,這種架構下我們把 Logstash實體與Elasticsearch實體直接相連,主要就是圖一個簡單,我們的程式App將日志寫入Log,然后Logstash將Log讀出,進行過濾,寫入Elasticsearch,最后瀏覽器訪問Kibana,提供一個可視化輸出,
入門級版本的缺點主要是兩個
- 在大并發情況下,日志傳輸峰值比較大,如果直接寫入ES,ES的HTTP API處理能力有限,在日志寫入頻繁的情況下可能會超時、丟失,所以需要一個緩沖中間件,
- 注意了,Logstash將Log讀出、過濾、輸出都是在應用服務器上進行的,這勢必會造成服務器上占用系統資源較高,性能不佳,需要進行拆分,
于是我們作為公司最牛的架構師,提出了一個升級版的ELK架構,解決如上兩個問題,
2、升級版
在這版中,加入一個緩沖中間件(訊息佇列),另外對Logstash拆分為Shipper和Indexer,先說一下,LogStash自身沒有什么角色,只是根據不同的功能、不同的配置給出不同的稱呼而已,Shipper來進行日志收集,Indexer從緩沖中間件接收日志,過濾輸出到Elasticsearch,具體如下圖所示
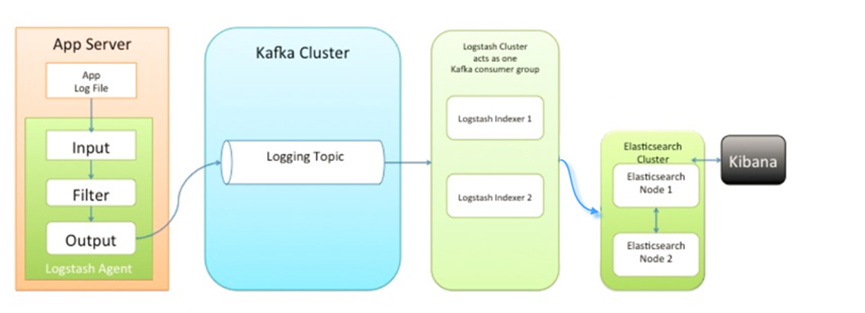
大家會發現,早期的博客,都是推薦使用redis,因為這是ELK Stack 官網建議使用 Redis 來做訊息佇列,但是很多大佬已經通過實踐證明使用Kafka更加優秀,原因如下:
- Redis無法保證訊息的可靠性,這點Kafka可以做到
- Kafka的吞吐量和集群模式都比Redis更優秀
- Redis受限于機器記憶體,當記憶體達到Max,資料就會拋棄,當然,你可以說我們可以加大記憶體啊?但是,在Redis中記憶體越大,觸發持久化的操作阻塞主執行緒的時間越長,相比之下,Kafka的資料是堆積在硬碟中,不存在這個問題,
但這個升級版仍然存在缺陷:
- Logstash Shipper是jvm跑的,非常占用JAVA記憶體! ,據《ELK系統使用filebeat替代logstash進行日志采集》這篇文章說明,8執行緒8GB記憶體下,Logstash常駐記憶體660M(JAVA),因此,這么一個巨無霸部署在應用服務器端就不大合適了,我們需要一個更加輕量級的日志采集組件,
- 上述架構如果部署成集群,所有業務放在一個大集群中相互影響,一個業務系統出問題了,就會拖垮整個日志系統,因此,需要進行業務隔離!
于是我們給我們在Elastic公司的朋友打了個電話,說明了他們這個集中型日志解決方案的弊端——太費CPU也就太費電,Elastic公司的朋友電話中告訴我們最近新研發了一個FileBeat,它是一個輕量級的日志收集處理工具(Agent),Filebeat占用資源少,適合于在各個服務器上搜集日志后傳輸給Logstash,官方也推薦此工具,
3、大師版
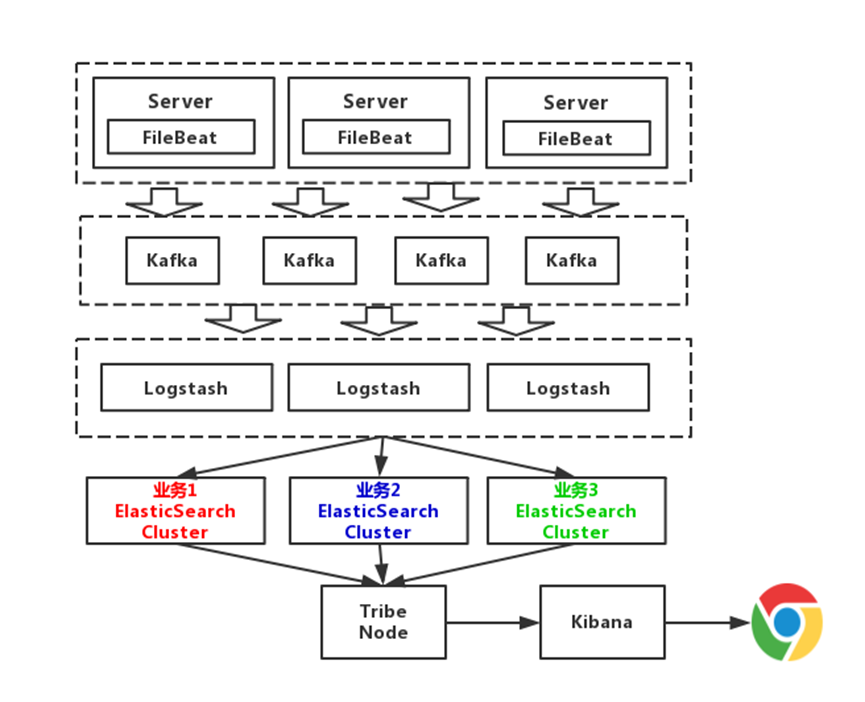
從上圖可以看到,Elasticsearch根據業務部了3個集群,他們之間相互獨立,避免出現,一個業務拖垮了Elasticsearch集群,整個日志系統就一起宕機的情況,而且,從運維角度來說,這種架構運維起來也更加方便,
這套架構的缺點在于對日志沒有進行冷熱分離,因為我們一般來說,一個月之內不排查的錯誤日志,那都是不重要的錯誤,以30天作為界限,區分冷熱資料,可以大大的優化查詢速度,
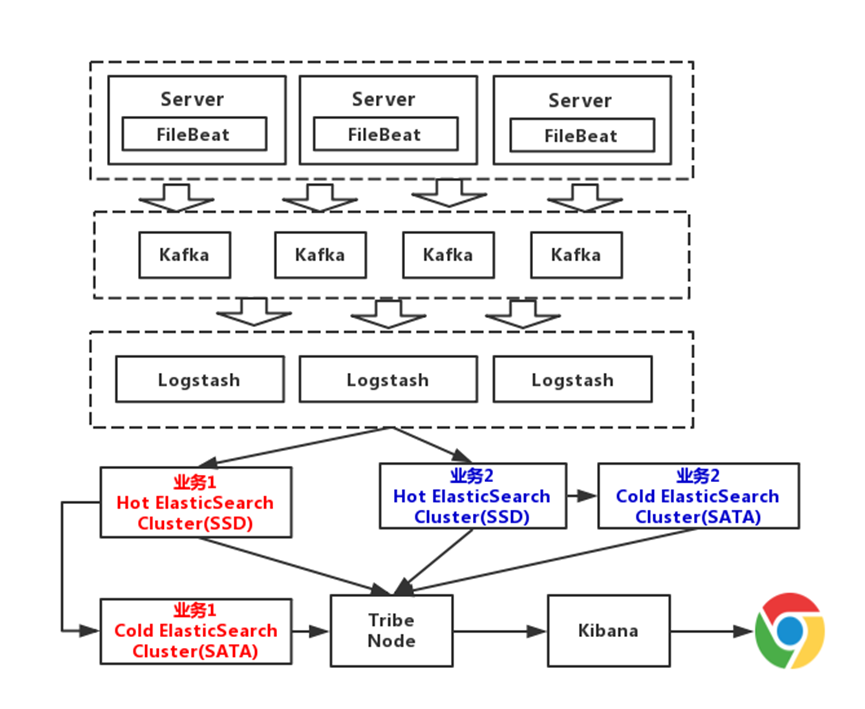
4、專家版
這一版,我們對資料進行冷熱分離,每個業務準備兩個Elasticsearch集群,可以理解為冷熱集群,7天以內的資料,存入熱集群,以SSD存盤索引,超過7天,就進入冷集群,以SATA存盤索引,這么一改動,性能又得到提升
四、ELK的作業原理
1、Filebeat作業原理
Filebeat由兩個主要組件組成:prospectors 和 harvesters,這兩個組件協同作業將檔案變動發送到指定的輸出中,
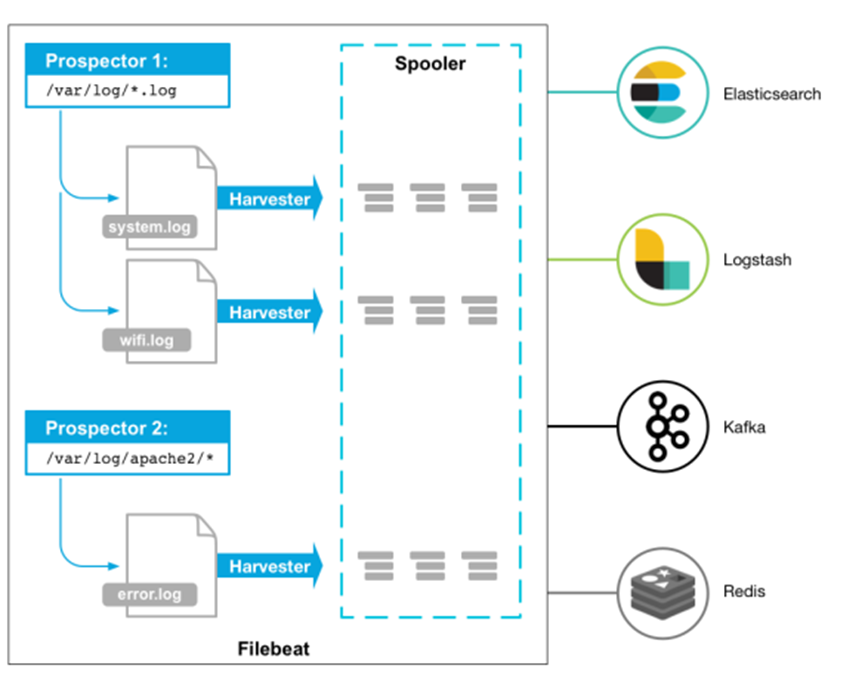
Harvester(收割機):負責讀取單個檔案內容,每個檔案會啟動一個Harvester,每個Harvester會逐行讀取各個檔案,并將檔案內容發送到制定輸出中,Harvester負責打開和關閉檔案,意味在Harvester運行的時候,檔案描述符處于打開狀態,如果檔案在收集中被重命名或者被洗掉,Filebeat會繼續讀取此檔案,所以在Harvester關閉之前,磁盤不會被釋放,默認情況filebeat會保持檔案打開的狀態,直到達到close_inactive(如果此選項開啟,filebeat會在指定時間內將不再更新的檔案句柄關閉,時間從harvester讀取最后一行的時間開始計時,若檔案句柄被關閉后,檔案發生變化,則會啟動一個新的harvester,關閉檔案句柄的時間不取決于檔案的修改時間,若此引數配置不當,則可能發生日志不實時的情況,由scan_frequency引數決定,默認10s,Harvester使用內部時間戳來記錄檔案最后被收集的時間,例如:設定5m,則在Harvester讀取檔案的最后一行之后,開始倒計時5分鐘,若5分鐘內檔案無變化,則關閉檔案句柄,默認5m),
Prospector(勘測者):負責管理Harvester并找到所有讀取源,
Prospector會找到/apps/logs/*目錄下的所有info.log檔案,并為每個檔案啟動一個Harvester,Prospector會檢查每個檔案,看Harvester是否已經啟動,是否需要啟動,或者檔案是否可以忽略,若Harvester關閉,只有在檔案大小發生變化的時候Prospector才會執行檢查,只能檢測本地的檔案,
Filebeat如何記錄檔案狀態:
將檔案狀態記錄在檔案中(默認在/var/lib/filebeat/registry),此狀態可以記住Harvester收集檔案的偏移量,若連接不上輸出設備,如ES等,filebeat會記錄發送前的最后一行,并再可以連接的時候繼續發送,Filebeat在運行的時候,Prospector狀態會被記錄在記憶體中,Filebeat重啟的時候,利用registry記錄的狀態來進行重建,用來還原到重啟之前的狀態,每個Prospector會為每個找到的檔案記錄一個狀態,對于每個檔案,Filebeat存盤唯一識別符號以檢測檔案是否先前被收集,
Filebeat如何保證事件至少被輸出一次:
Filebeat之所以能保證事件至少被傳遞到配置的輸出一次,沒有資料丟失,是因為filebeat將每個事件的傳遞狀態保存在檔案中,在未得到輸出方確認時,filebeat會嘗試一直發送,直到得到回應,若filebeat在傳輸程序中被關閉,則不會再關閉之前確認所有時事件,任何在filebeat關閉之前為確認的時間,都會在filebeat重啟之后重新發送,這可確保至少發送一次,但有可能會重復,可通過設定shutdown_timeout 引數來設定關閉之前的等待事件回應的時間(默認禁用),
2、Logstash作業原理
Logstash事件處理有三個階段:inputs → filters → outputs,是一個接收,處理,轉發日志的工具,支持系統日志,webserver日志,錯誤日志,應用日志,總之包括所有可以拋出來的日志型別,
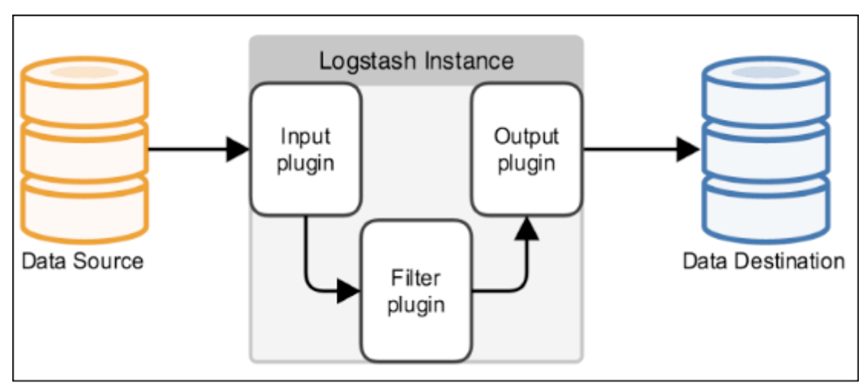
Input:輸入資料到logstash,一些常用的輸入為:
file:從檔案系統的檔案中讀取,類似于tail -f命令
syslog:在514埠上監聽系統日志訊息,并根據RFC3164標準進行決議
redis:從redis service中讀取
beats:從filebeat中讀取
Filters:資料中間處理,對資料進行操作,
一些常用的過濾器為:
grok:決議任意文本資料,Grok 是 Logstash 最重要的插件,它的主要作用就是將文本格式的字串,轉換成為具體的結構化的資料,配合正則運算式使用,內置120多個決議語法,(官方提供的grok運算式:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
grok在線除錯:https://grokdebug.herokuapp.com/)
mutate:對欄位進行轉換,例如對欄位進行洗掉、替換、修改、重命名等,
drop:丟棄一部分events不進行處理,
clone:拷貝 event,這個程序中也可以添加或移除欄位,
geoip:添加地理資訊(為前臺kibana圖形化展示使用)
Outputs:outputs是logstash處理管道的最末端組件,一個event可以在處理程序中經過多重輸出,但是一旦所有的outputs都執行結束,這個event也就完成生命周期,一些常見的outputs為:
elasticsearch:可以高效的保存資料,并且能夠方便和簡單的進行查詢,
file:將event資料保存到檔案中,
graphite:將event資料發送到圖形化組件中,一個很流行的開源存盤圖形化展示的組件,
3、Elasticsearch 基本原理
舉個例子,現在我們要保存唐宋詩詞,關系型資料庫中我們們會怎么設計?詩詞表我們可能的設計如下:
|
朝代 |
作者 |
標題 |
詩詞全文 |
|
唐 |
李白 |
靜夜思 |
床前明月光,疑是地上霜,舉頭望明月,低頭思故鄉, |
|
宋 |
李清照 |
如夢令 |
常記溪亭日暮,沉醉不知歸路,興盡晚回舟,誤入藕花深處,爭渡,爭渡,驚起一灘鷗鷺, |
要根據朝代或者作者尋找詩,都很簡單,比如“select 詩詞全文 from 詩詞表where作者=‘李白’”,如果資料很多,查詢速度很慢,怎么辦?我們可以在對應的查詢欄位上建立索引加速查詢,
但是如果我們現在有個需求:要求找到包含“望”字的詩詞怎么辦?用
“select 詩詞全文 from 詩詞表 where 詩詞全文 like‘%望%’”,這個意味著
要掃描庫中的詩詞全文欄位,逐條比對,找出所有包含關鍵詞“望”字的記錄,,
基本上,資料庫中一般的 SQL 優化手段都是用不上的,數量少,大概性能還能接受,如果資料量稍微大點,就完全無法接受了,更何況在互聯網這種海量資料的情況下呢?
怎么解決這個問題呢,用倒排索引Inverted index
比如現在有:
蜀道難(唐)李白 蜀道之難難于上青天,側身西望長咨嗟,
靜夜思(唐)李白 舉頭望明月,低頭思故鄉,
春臺望(唐)李隆基 暇景屬三春,高臺聊四望,
鶴沖天(宋)柳永 黃金榜上,偶失龍頭望,明代暫遺賢,如何向?未遂風云便,爭不恣狂蕩,何須論得喪?才子詞人,自是白衣卿相,煙花巷陌,依約丹青屏障,
幸有意中人,堪尋訪,且恁偎紅翠,風流事,平生暢,青春都一餉,忍把浮名,換了淺斟低唱!
這些詩詞都有望字,于是我們可以這么保存
|
序號 |
關鍵字 |
蜀道難 |
靜夜思 |
春臺望 |
鶴沖天 |
|
1 |
望 |
有 |
有 |
有 |
有 |
|
|
|
|
|
|
|
其實,上述詩詞的中每個字都可以作為關鍵字,然后建立關鍵字和檔案之間的對應關系,也就是標識關鍵字被哪些檔案包含,
所以,倒排索引就是,將檔案中包含的關鍵字全部提取處理,然后再將關鍵字和檔案之間的對應關系保存起來,最后再對關鍵字本身做索引排序,用戶在檢索某一個關鍵字是,先對關鍵字的索引進行查找,再通過關鍵字與檔案的對應關系找到所在檔案,
Elasticsearch 索引是映射型別的容器,一個 Elasticsearch 索引非常像關系型世界的資料庫,是獨立的大量檔案集合,
當然在底層,肯定用到了倒排索引,最基本的結構就是“keyword”和“PostingList”,Posting list就是一個 int的陣列,存盤了所有符合某個 term的檔案 id,
另外,這個倒排索引相位元定詞項出現過的檔案串列,會包含更多其它資訊,
它會保存每一個詞項出現過的檔案總數,在對應的檔案中一個具體詞項出現的總次數,詞項在檔案中的順序,每個檔案的長度,所有檔案的平均長度等等相關資訊,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/399515.html
標籤:其他