我需要對我的真實 df 使用 lapply/sapply 或其他遞回方法來計算每列/變數中有多少重復值。
這里我用一個小例子來重現我的案例:
library(dplyr)
df <- data.frame(
var1 = c(1,2,3,4,5,6,7,8,9,10 ),
var2 = c(1,1,2,3,4,5,6,7,9,10 ),
var3 = c(1,1,1,2,3,4,5,6,7,8 ),
var4 = c(2,2,1,1,2,1,1,2,1,2 ),
var5 = c(1,1,1,1,1,4,5,5,6,7 ),
var6 = c(4,4,4,5,5,5,5,5,5,5 )
)
我r nrow(df)在我的資料集中,現在我需要獲取每列的重復值的百分比。假設我的 realdf有很多列,我需要遞回地做。我嘗試使用lapply/sapply,但它沒有作業...
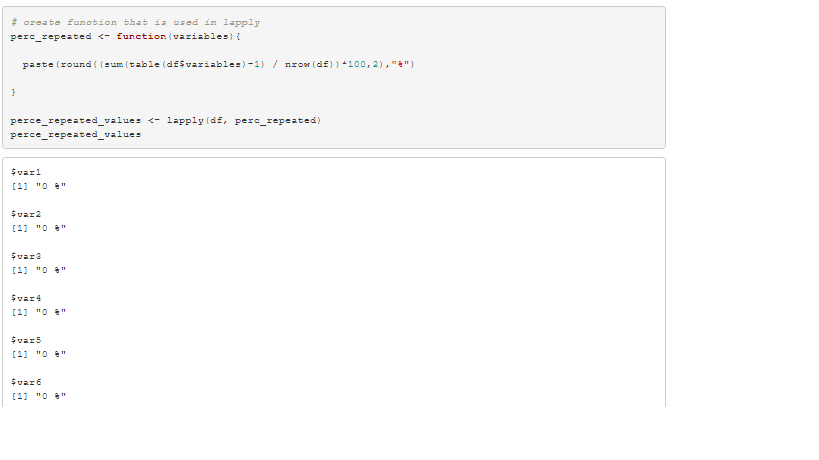
# create function that is used in lapply
perc_repeated <- function(variables){
paste(round((sum(table(df$variables)-1) / nrow(df))*100,2),"%")
}
perce_repeated_values <- lapply(df, perc_repeated)
perce_repeated_values
如果我的資料框的列數增加到 700 左右,對每列使用一些遞回函式并在資料框中從最大到最小有序地獲取結果,如何以最佳方式執行此操作?(例如,對于達到 0% 的變數具有 100% 重復值的變數),例如:
df_repeated
variable perc_repeated_values
var6 80%
var4 80%
var5 50%
var3 20%
var2 20%
var1 0%
uj5u.com熱心網友回復:
這可以很容易地完成 dplyr::summarize()
library(tidyverse)
df <- data.frame(
var1 = c(1,2,3,4,5,6,7,8,9,10 ),
var2 = c(1,1,2,3,4,5,6,7,9,10 ),
var3 = c(1,1,1,2,3,4,5,6,7,8 ),
var4 = c(2,2,1,1,2,1,1,2,1,2 ),
var5 = c(1,1,1,1,1,4,5,5,6,7 ),
var6 = c(4,4,4,5,5,5,5,5,5,5 )
)
df %>%
summarise(across(everything(),
~100 * (1 - n_distinct(.)/n()))) %>%
pivot_longer(everything(),
names_to = "var",
values_to = "percent_repeated") %>%
arrange(desc(percent_repeated))
#> # A tibble: 6 x 2
#> var percent_repeated
#> <chr> <dbl>
#> 1 var4 80
#> 2 var6 80
#> 3 var5 50
#> 4 var3 20
#> 5 var2 10
#> 6 var1 0
由reprex 包(v2.0.1)創建于 2022-01-09
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/406817.html
標籤: