我創建了一個刮板,但我一直在努力解決一個問題:獲取與電影/電視節目標題相關的關鍵字。
我有df以下網址
keyword_link_list = ['https://www.imdb.com/title/tt7315526/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11723916/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt7844164/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt2034855/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11215178/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt10941266/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt13210836/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt0913137/keywords?ref_=tt_ql_sm']
df = pd.DataFrame({'keyword_link':keyword_link_list})
print(df)
然后,我喜歡通過 column 回圈keyword_link,獲取所有關鍵字,并將它們添加到字典中。我設法獲得了所有關鍵字,但我沒有設法將它們添加到字典中。這似乎是一個簡單的問題,但我沒有看到我做錯了什么(經過數小時的努力)。非常感謝您的幫助!
# Import packages
import requests
import re
from bs4 import BeautifulSoup
import bs4 as bs
import pandas as pd
# Loop through column keyword_link and get the keywords for each link
keyword_dicts = []
for index, row in df.iterrows():
keyword_link = row['keyword_link']
print(keyword_link)
headers = {"Accept-Language": "en-US,en;q=0.5"}
r=requests.get(keyword_link, headers=headers)
html = r.text
soup = bs.BeautifulSoup(html, 'html.parser')
elements = soup.find_all('td', {'class':"soda sodavote"})
for element in elements:
for keyword in element.find_all('a'):
keyword = keyword['href']
keyword = re.sub(r'\/search/keyword\?keywords=', '', keyword)
keyword = re.sub(r'\?item=kw\d ', '', keyword)
print(keyword)
keyword_dict = {}
keyword_dict['keyword'] = keyword
keyword_dicts.append(keyword_dict)
print(keyword_dicts)
更新
運行定義后,我收到以下錯誤:
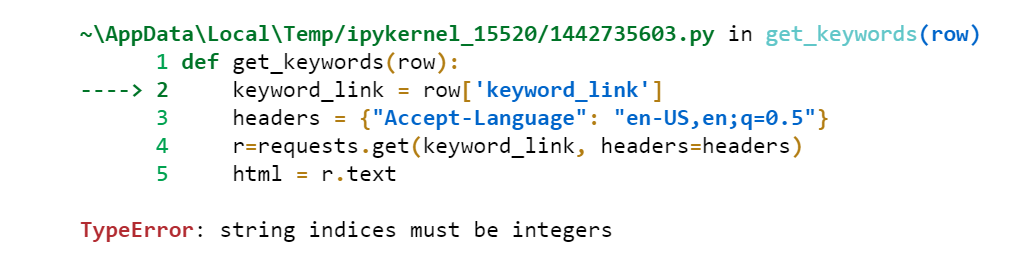
uj5u.com熱心網友回復:
注意: 因為預期的輸出不是很清楚,可以改進,這個例子只處理你的串列上的操作。您可以使用輸出來創建資料框、串列...
怎么了?
你的字典是在回圈后面定義的——你不會得到任何資訊來存盤,你的串列只包含 [{'keyword': ''}]
怎么修?
在迭代關鍵字時附加您的字典。
替代方法:
但是,它不需要資料框,只需一行即可獲取您的關鍵字:
keywords = [e.a.text for e in soup.select('[data-item-keyword]')]
在以下示例中,我提出了一些關于如何收集和收集什么的變體:
只收集由空格分隔的關鍵字:
[e.a.text for e in soup.select('[data-item-keyword]')]
收集與 url 中相同的以“-”分隔的關鍵字:
['-'.join(x.split()) for x in keywords]
收集關鍵字和投票可能也很有趣:
[{'keyword':k,'votes':v} for k,v in zip(keywords,votes)]
例子
import requests, time
from bs4 import BeautifulSoup
import pandas as pd
keyword_link_list = ['https://www.imdb.com/title/tt7315526/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11723916/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt7844164/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt2034855/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt11215178/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt10941266/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt13210836/keywords?ref_=tt_ql_sm',
'https://www.imdb.com/title/tt0913137/keywords?ref_=tt_ql_sm'
]
def cook_soup(url):
#do not harm the website add some delay
#time.sleep(2)
headers ={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36','Accept-Language': 'en-US,en;q=0.5'
}
r = requests.get(url,headers=headers)
soup = BeautifulSoup(r.text,'lxml')
return soup
data = []
for url in keyword_link_list:
soup = cook_soup(url)
keywords = [e.a.text for e in soup.select('[data-item-keyword]')]
votes = [e['data-item-votes'] for e in soup.select('[data-item-votes]')]
data.append({
'url':url,
'keywords':keywords,
})
print(data)
### pd.DataFrame(data)
uj5u.com熱心網友回復:
您的代碼的問題是您沒有在回圈中保存關鍵字。此外,不要迭代資料框行,而是創建一個函式來執行您想要的操作并將其應用于keyword_link列。
def get_keywords(row):
headers = {"Accept-Language": "en-US,en;q=0.5"}
r=requests.get(row, headers=headers)
# ^^^ replace keyword_link to row here
html = r.text
soup = bs.BeautifulSoup(html, 'html.parser')
elements = soup.find_all('td', {'class':"soda sodavote"})
keyword_dict = {'keyword':[]}
# ^^^ declare the dict here
for element in elements:
for keyword in element.find_all('a'):
keyword = keyword['href']
keyword = re.sub(r'\/search/keyword\?keywords=', '', keyword)
keyword = re.sub(r'\?item=kw\d ', '', keyword)
if keyword:
keyword_dict['keyword'].append(keyword)
# ^^^ move this inside the loop
return keyword_dict
但是,存盤關鍵字串列可能會更好,因為'keyword'鍵在這里實際上什么都不做。
無論如何,那么您可以將其用作
df[keywords] = df['keyword_link'].apply(get_keywords)
現在,如果您需要關鍵字字典串列,您可以這樣做
keyword_dicts = df[keywords].tolist()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/410057.html
標籤:
上一篇:如何檢查字典是否包含與另一個字典相同的專案-Python
下一篇:基于字典列印句子