假設一個資料集由兩組組成:
dataA<-rnorm(200,3,sd=2)
dataB<-rnorm(500,5,sd=3)
all<-data.frame(dataset=c(rep('A',length(dataA)),rep('B',length(dataB))),value=c(dataA,dataB))
我們可以像這樣用兩組繪制直方圖:
ggplot(all,aes(value,fill=dataset)) geom_histogram(bins=50,position='stack')
我想獲得相同的情節,但每組的比例而不是每個 bin 的計數。
我通過手動計算每個組的比例找到了以下方法:
ggplot(all,aes(x=value,fill=dataset)) geom_histogram(aes(y=c(..count..[..group..==1]/(..count..[..group..==1] ..count..[..group..==2]),..count..[..group..==2]/(..count..[..group..==1] ..count..[..group..==2]))),position='stack',bins=50) ylab('proportion')
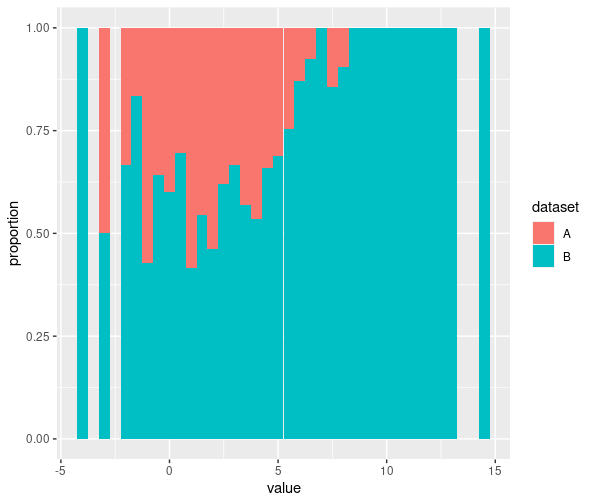
這給出了預期的結果(如下),但這是一個非常不雅的解決方案。我可能在這里遺漏了一些東西,有沒有更好的方法來獲得相同(或相似)的結果?
uj5u.com熱心網友回復:
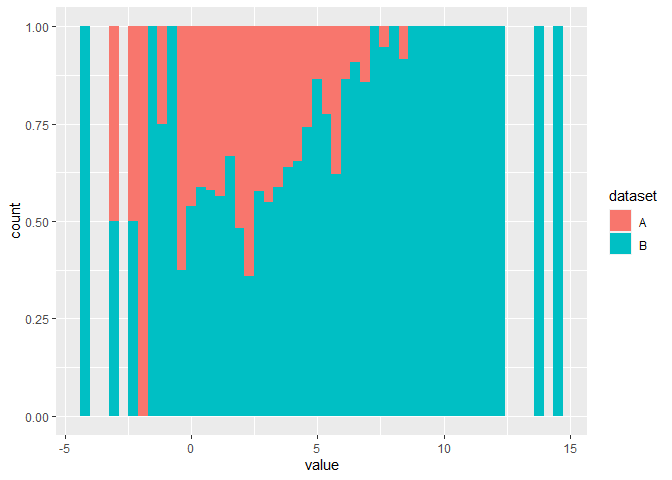
您可能正在尋找position = 'fill'而不是'stack'.
library(ggplot2)
set.seed(42)
dataA <- rnorm(200, 3, sd = 2)
dataB <- rnorm(500, 5, sd = 3)
all <- data.frame(
dataset = c(rep('A', length(dataA)),rep('B', length(dataB))),
value = c(dataA, dataB)
)
ggplot(all, aes(value, fill = dataset))
geom_histogram(bins = 50, position = 'fill')
#> Warning: Removed 14 rows containing missing values (geom_bar).
由reprex 包于 2022-01-15 創建(v2.0.1)
uj5u.com熱心網友回復:
library(ggplot2)
library(scales)
dataA<-rnorm(200,3,sd=2)
dataB<-rnorm(500,5,sd=3)
all<-data.frame(dataset=c(rep('A',length(dataA)),rep('B',length(dataB))),value=c(dataA,dataB))
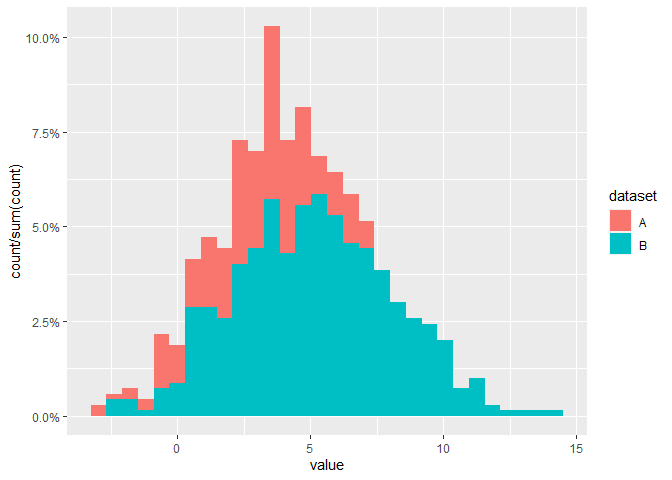
ggplot(all, aes(value, fill = dataset))
geom_histogram(aes(y = stat(count / sum(count))))
scale_y_continuous(labels = scales::percent_format())
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
由reprex 包于 2022-01-15 創建(v2.0.1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/416790.html
標籤: