我有如下 csv 資料。
1,2,3,4
a,b,c,d
1,2,3,4不是 csv 標頭。它是資料。
該值是所有字串資料。
我想通過 Pandas 加入 1 和 2 的索引(串列)列。
我想得到如下結果。
結果資料是字串。
1,23,4
a,bc,d
Python 的代碼如下所示。
lines = [
['1', '2', '3', '4'],
['a', 'b', 'c', 'd'],
]
vals = lines[0]
s = vals[0] ',' (vals[1] vals[2]) ',' vals[3] '\n'
vals = lines[1]
s = vals[0] ',' (vals[1] vals[2]) ',' vals[3] '\n'
print(s)
你怎么做?
uj5u.com熱心網友回復:
如果您想使用 pandas,您可以創建新列并洗掉舊列:
import pandas as pd
lines = [
['1', '2', '3', '4'],
['a', 'b', 'c', 'd'],
]
df = pd.DataFrame(lines)
# Create new column
df['new_col'] = df[1] df[2]
print(df)
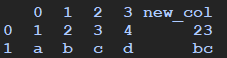
# 0 1 2 3 new_col
# 0 1 2 3 4 23
# 1 a b c d bc
# Remove old columns if needed
df.drop([1, 2], axis=1, inplace=True)
print(df)
# 0 3 new_col
# 0 1 4 23
# 1 a d bc
如果您希望列按特定順序排列,請使用以下內容:
print(df[[0, 'new_col', 3]])
# 0 new_col 3
# 0 1 23 4
# 1 a bc d
但最好將標題保存在 csv 中
uj5u.com熱心網友回復:
for您可以使用或串列理解來回圈它。
lines = [
['1', '2', '3', '4'],
['a', 'b', 'c', 'd'],
]
vals = [','.join([w, f'{x}{y}', *z]) for w, x, y, *z in lines]
s = '\n'.join(vals)
print(x)
# prints:
1,23,4
a,bc,d
uj5u.com熱心網友回復:
你可以做這樣的事情。
import pandas as pd
lines = [
['1', '2', '3', '4'],
['a', 'b', 'c', 'd'],
]
df = pd.DataFrame(lines)
df['new_col'] = df.iloc[:, 1] df.iloc[:, 2]
print(df)
輸出
然后,您可以洗掉不需要的列。
uj5u.com熱心網友回復:
由于 OP 指定了 pandas,因此這是一個可行的解決方案。
一旦進入熊貓,例如pd.read_csv()
您可以簡單地將文本(物件)列與
import pandas as pd
lines = [ ['1', '2', '3', '4'],
['a', 'b', 'c', 'd']]
df = pd.DataFrame(lines)
df[1] = df[1] df[2]
df.drop(columns=2, inplace=True)
df
# 0 1 3
# 0 1 23 4
# 1 a bc d
應該在熊貓資料框中為您提供所需的內容。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/418857.html
標籤: