火花作業的定義是:
作業 - 由多個任務組成的并行計算,這些任務回應 Spark 操作(例如保存、收集)而產生;您會在驅動程式日志中看到該術語。
那么,為什么每個spark-submit人在我可以看到的 dataproc 控制臺中只創建一個作業 ID?
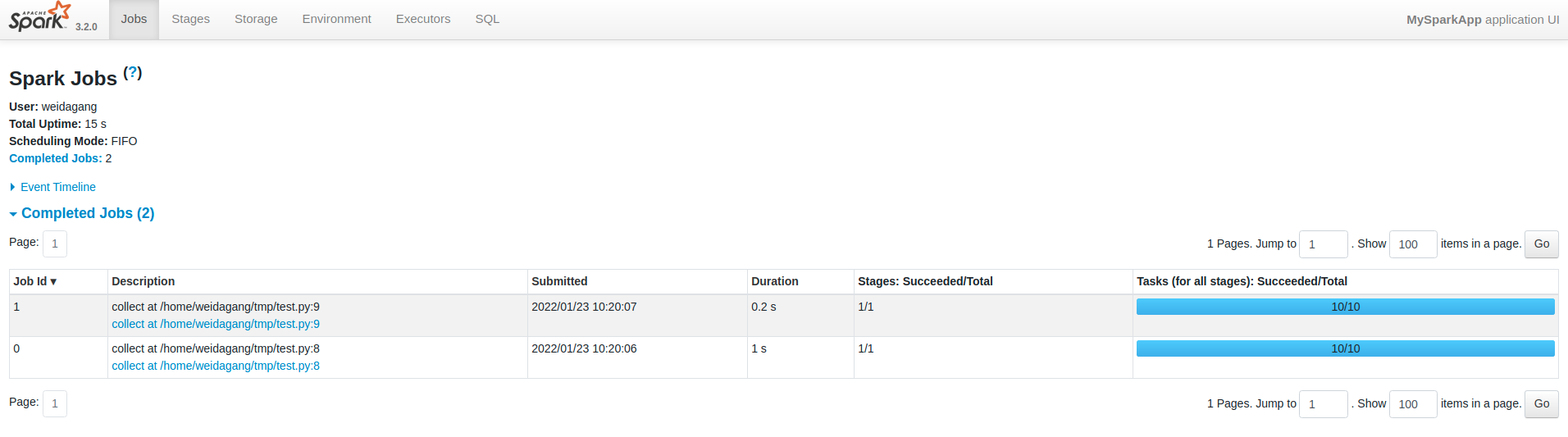
示例:以下應用程式應該有 2 個 Spark 作業
sc.parallelize(range(1000),10).collect()
sc.parallelize(range(1000),10).collect()
uj5u.com熱心網友回復:
Dataproc 作業和 Spark 作業之間存在差異。當您通過 Dataproc API/CLI 提交腳本時,它會創建一個 Dataproc 作業,該作業反過來呼叫spark-submit以將腳本提交到 Spark。但在 Spark 內部,上面的代碼確實創建了 2 個 Spark 作業。您可以在 Spark UI 中看到它:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/419847.html
標籤: