我想讓傳奇變得更好()
我正在尋找根據更高分類(門)分組的圖例,但同時顯示屬(屬)。
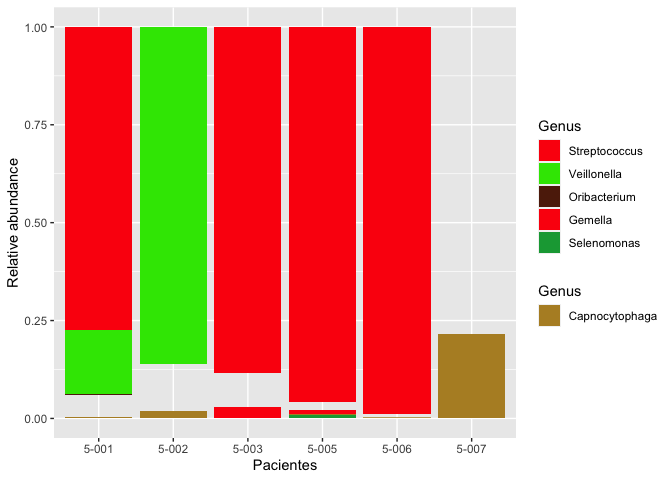
我想要這樣的東西: 我試著做這樣的東西
我運行這段代碼:
ggplot(d4)
geom_bar(aes(x=Pacientes, y=`Relative abundance`,fill=Genus), position="fill", stat="identity") scale_x_discrete("Patients")
scale_y_continuous("Relative abundance",labels=scales::percent)
labs(title = "CAP",subtitle = "Relative abundance of phylum and genus")
theme_classic()
scale_fill_manual(values=c ("#FC000D", "#30E500", "#E10072", "#730183", "#B58E2C","#10A542","#6C1429",
"#00B9B9", "#E36582","orange3","#800009",
"#5E230B","#CC6187","#949285","#FF6A00",
"#FF9D69","#B08A04","#005A3F","#120A5F","#E7BECD"))
輸出
示例資料
d4<-structure(list(Pacientes = c("5-006", "5-005", "5-005", "5-001",
"5-003", "5-002", "5-001", "5-001", "5-005", "5-001", "5-003",
"5-003", "5-007", "5-006", "5-003", "5-001", "5-002", "5-003",
"5-002", "5-002", "5-001", "5-002", "5-003", "5-005", "5-002",
"5-001", "5-006", "5-005", "5-007", "5-005"), Filum = c("Firmicutes",
"Firmicutes", "Firmicutes", "Firmicutes", "Firmicutes", "Firmicutes",
"Firmicutes", "Firmicutes", "Proteobacteria", "Proteobacteria",
"Proteobacteria", "Proteobacteria", "Proteobacteria", "Proteobacteria",
"Proteobacteria", "Proteobacteria", "Proteobacteria", "Proteobacteria",
"Spirochaetes", "Spirochaetes", "Spirochaetes", "Spirochaetes",
"Firmicutes", "Firmicutes", "Bacteroidetes", "Bacteroidetes",
"Bacteroidetes", "Bacteroidetes", "Bacteroidetes", "Firmicutes"
), Genus = structure(c(1L, 1L, 1L, 1L, 1L, 2L, 2L, 12L, 13L,
13L, 13L, 13L, 13L, 14L, 15L, 15L, 15L, 15L, 20L, 20L, 20L, 20L,
21L, 21L, 25L, 25L, 25L, 25L, 25L, 26L), .Label = c("Streptococcus",
"Veillonella", "Haemophilus", "Actinobacillus", "Serratia", "Fusobacterium",
"Neisseria", "Moraxella", "Abiotrophia", "Granulicatella", "Actinomyces",
"Oribacterium", "Aggregatibacter", "Escherichia-Shigella", "Lautropia",
"Geobacillus", "Leptotrichia", "Johnsonella", "Campylobacter",
"Treponema 2", "Gemella", "Megasphaera", "Atopobium", "Bifidobacterium",
"Capnocytophaga", "Selenomonas", "Mycoplasma", "Porphyromonas",
"Alloprevotella", "Lachnoanaerobaculum", "Eikenella", "[Eubacterium] brachy group",
"Stomatobaculum", "Atopostipes", "Selenomonas 3", "Kingella",
"Dialister", "F0058", "Parvimonas", "No identificado", "Solobacterium",
"Otros finales", "Olsenella", "Filifactor", "Rodentibacter",
"Alloscardovia", "Otros", "[Eubacterium] yurii group", "Anaeroglobus",
"Staphylococcus", "Ruminococcaceae UCG-014", "Lactobacillus",
"Rothia", "Selenomonas 4", "Scardovia", "Fluviicola", "Cardiobacterium",
"Bilophila", "Simonsiella", "[Eubacterium] nodatum group", "Catonella",
"Peptoniphilus", "uncultured", "Shuttleworthia", "Butyrivibrio 2",
"Peptostreptococcus", "Mogibacterium", "Bergeyella", "Peptococcus",
"Faucicola", "Blautia", "Rikenellaceae RC9 gut group", "Eggerthia",
"Desulfobulbus", "Tannerella", "Lactococcus", "Prevotella", "Otro",
"Prevotella 7", "Erysipelotrichaceae UCG-006", "Defluviitaleaceae UCG-011",
"W5053", "Craurococcus", "Dolosigranulum", "Sneathia", "Anaerococcus",
"Pseudoramibacter", "Family XIII UCG-001", "Ruminococcus 2",
"Howardella", "Cryptobacterium", "Listeria", "Pantoea", "Akkermansia",
"Prevotella 6", "Macrococcus", "Paracoccus", "Comamonas", "TM7 phylum sp. oral clone FR058",
"Peptoanaerobacter", "Rubellimicrobium", "Fastidiosipila", "Brachymonas",
"Candidatus Tammella", "Slackia", "DNF00809", "Truepera", "Finegoldia",
"Erysipelotrichaceae UCG-004", "uncultured bacterium", "Bulleidia",
"Flexilinea", "Methylobacterium", "Propionivibrio", "Ochrobactrum"
), class = "factor"), `Relative abundance` = c(1.797989737427,
1.17051056033446, 0.967773967968912, 0.890190018788368, 0.875168325944855,
0.203636768715721, 0.190978038791412, 0.0011814814596022, 0.0411830680204194,
0.031674955321716, 0.018003527003462, 0.00559797167763897, 0.0032912697803204,
0.0189880948864639, 0.0386794525465004, 0.0337566131314913, 0.0279054668553661,
0.0242766309437308, 0.000168783065657456, 0.000112522043771638,
8.43915328287282e-05, 8.43915328287282e-05, 0.0290306872930825,
0.0263020277316203, 0.00458527328369423, 0.00393827153200732,
0.00351631386786368, 0.00210978832071821, 0.000900176350173101,
0.021744884958869)), row.names = c(NA, -30L), class = c("tbl_df",
"tbl", "data.frame"))
分組列是Filum,正常圖例是資料中的Genus。
謝謝
uj5u.com熱心網友回復:
實作您想要的結果的一種選擇是通過ggnewscale允許具有相同美學的多個比例和圖例的包。
- 將您的顏色放入一個命名向量中,該向量為您的每個指定顏色
Genus - 列出哪些
Filums 關聯了Genuss。為此,我使用dplyr::distinctandsplit。
library(ggplot2)
library(ggnewscale)
library(dplyr)
cols <- c("#FC000D", "#30E500", "#E10072", "#730183",
"#B58E2C", "#10A542", "#6C1429",
"#00B9B9", "#E36582", "orange3", "#800009",
"#5E230B", "#CC6187", "#949285", "#FF6A00",
"#FF9D69", "#B08A04", "#005A3F", "#120A5F", "#E7BECD")
cols <- rep_len(cols, length.out = length(levels(d4$Genus)))
names(cols) <- levels(d4$Genus)
groups <- d4 %>%
distinct(Filum, Genus) %>%
# Add order of Filum and legends
mutate(order = as.numeric(forcats::fct_inorder(Filum))) %>%
split(.$Filum)
- 對于每個
Filum添加一個geom_col顯示整個資料和一個scale_fill_manual使用limits引數的位置,我們只顯示Genus與 this 關聯的 sFilum。這樣做Genus將分配給NA我們選擇transparent顏色的所有其他 s。
為了了解我們在這里所做的事情的基本概念,只需要兩個組的代碼:
ggplot(d4)
geom_col(aes(x = Pacientes, y=`Relative abundance`, fill = Genus), position = "fill")
scale_fill_manual(values = cols, limits = groups$Firmicutes$Genus, na.value = "transparent")
new_scale_fill()
geom_col(aes(x = Pacientes, y=`Relative abundance`, fill = Genus), position = "fill")
scale_fill_manual(values = cols, limits = groups$Bacteroidetes$Genus, na.value = "transparent")
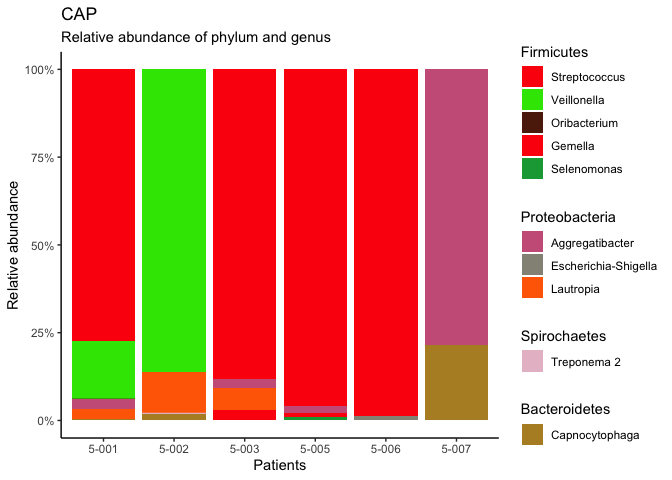
如果我們有很多組,我們可以使用lapply回圈遍歷組并動態添加圖層,而不是復制和粘貼變得麻煩,如下所示:
ggplot(d4)
lapply(groups, function(x) {
list(
geom_col(aes(x = Pacientes, y=`Relative abundance`, fill = Genus), position = "fill"),
scale_fill_manual(name = unique(x$Filum),
values = cols, limits = x$Genus, na.value = "transparent",
guide = guide_legend(order = unique(x$order))),
new_scale_fill()
)
})
scale_x_discrete("Patients")
scale_y_continuous("Relative abundance", labels = scales::percent)
labs(title = "CAP", subtitle = "Relative abundance of phylum and genus")
theme_classic()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/420817.html
標籤: