我嘗試實作性能改進,并在 SIMD 方面取得了一些不錯的經驗。到目前為止,我一直在使用 OMP,并且喜歡使用內在函式進一步提高我的技能。
在以下場景中,由于元素 n 1 測驗所需的 last_value 的資料依賴性,我未能改進(甚至矢量化)。
環境是具有AVX2的x64,所以想找到一種方法來矢量化和SIMDfy這樣的函式。
inline static size_t get_indices_branched(size_t* _vResultIndices, size_t _size, const int8_t* _data) {
size_t index = 0;
int8_t last_value = 0;
for (size_t i = 0; i < _size; i) {
if ((_data[i] != 0) && (_data[i] != last_value)) {
// add to _vResultIndices
_vResultIndices[index] = i;
last_value = _data[i];
index;
}
}
return index;
}
輸入是一個有符號的 1 位元組值陣列。每個元素都是 <0,1,-1> 之一。輸出是輸入值(或指標)的索引陣列,表示更改為 1 或 -1。
輸入/輸出示例
in: { 0,0,1,0,1,1,-1,1, 0,-1,-1,1,0,0,1,1, 1,0,-1,0,0,0,0,0, 0,1,1,1,-1,-1,0,0, ... }
out { 2,6,7,9,11,18,25,28, ... }
我的第一次嘗試是,使用各種無分支版本,并通過比較匯編輸出來查看自動矢量化或 OMP 是否能夠將其轉換為 SIMDish 代碼。
示例嘗試
int8_t* rgLast = (int8_t*)alloca((_size 1) * sizeof(int8_t));
rgLast[0] = 0;
#pragma omp simd safelen(1)
for (size_t i = 0; i < _size; i) {
bool b = (_data[i] != 0) & (_data[i] != rgLast[i]);
_vResultIndices[index] = i;
rgLast[i 1] = (b * _data[i]) (!b * rgLast[i]);
index = b;
}
由于沒有實驗導致 SIMD 輸出,我開始嘗試使用內在函式,目的是將條件部分轉換為掩碼。
對于 != 0 部分,這非常簡單:
__m256i* vData = (__m256i*)(_data);
__m256i vHasSignal = _mm256_cmpeq_epi8(vData[i], _mm256_set1_epi8(0)); // elmiminate 0's
測驗“最后一次翻轉”的條件方面我還沒有找到方法。
為了解決以下輸出打包方面,我假設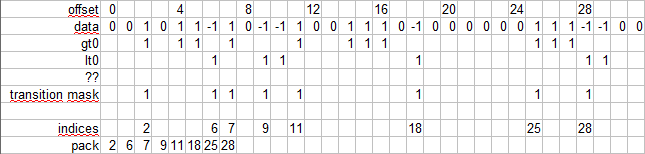 The challenge now is how to create the transition mask based on gt0 and lt0 masks.
The challenge now is how to create the transition mask based on gt0 and lt0 masks.
Update 2
Appearently an approach of splitting 1's and -1's into 2 streams (see in answer how), introduces a dependency while acessing elements for scanning alternating: How to efficiently scan 2 bit masks alternating each iteration
Creation of a transition mask as @aqrit worked out using
transition mask = ((~lt gt) & lt) | ((~gt lt) & gt) is possible. Eventhough this adds quite some instructions, it apears to be a beneficial tradeoff for data dependency elimination. I assume the gain grows the larger a register is (might be chip dependent).
Update 3
By vectorizing transition mask = ((~lt gt) & lt) | ((~gt lt) & gt)
I could get this output compiled
vmovdqu ymm5,ymmword ptr transition_mask[rax]
vmovdqu ymm4,ymm5
vpandn ymm0,ymm5,ymm6
vpaddb ymm1,ymm0,ymm5
vpand ymm3,ymm1,ymm5
vpandn ymm2,ymm5,ymm6
vpaddb ymm0,ymm2,ymm5
vpand ymm1,ymm0,ymm5
vpor ymm3,ymm1,ymm3
vmovdqu ymmword ptr transition_mask[rax],ymm3
On first look it appears efficient compared to potential condition related pitfalls of post-processing (vertical scan append to output), although it appears to be right and logical to deal with 2 streams instead of 1.
This lacks the ability to generate the initial state per cycle (transition from 0 to either 1 or -1).
Not sure if there is a way to enhance the transition_mask generation "bit twiddling", or use auto initial _tzcnt_u32(mask0) > _tzcnt_u32(mask1) as Soons uses here: https://stackoverflow.com/a/70890642/18030502 which appears to include a branch.
uj5u.com熱心網友回復:
完全矢量化對于您的情況不是最佳的。這在技術上是可行的,但我認為生成 uint64_t 值陣列的開銷(我假設你正在為 64 位 CPU 編譯)會吃掉所有的利潤。
相反,您應該加載 32 位元組的塊,并立即將它們轉換為位掩碼。就是這樣:
inline void loadBits( const int8_t* rsi, uint32_t& lt, uint32_t& gt )
{
const __m256i vec = _mm256_loadu_si256( ( const __m256i* )rsi );
lt = (uint32_t)_mm256_movemask_epi8( vec );
const __m256i cmp = _mm256_cmpgt_epi8( vec, _mm256_setzero_si256() );
gt = (uint32_t)_mm256_movemask_epi8( cmp );
}
您的其余代碼應處理這些位圖。要找到第一個非零元素(您只需要在資料的開頭執行此操作),請掃描(lt | gt)整數中的最低有效設定位。要查找-1數字,請掃描整數中的最低有效設定位lt,查找 1數字掃描整數中的最低有效設定位gt。找到并處理后,您可以使用按位與清除兩個整數的低位部分,或者將它們都向右移動。
CPU 有BSF指令,它掃描整數中的最低設定位,并一次回傳兩件事:一個指示整數是否為零的標志,以及該設定位的索引。如果您使用的是 VC ,則有_BitScanForward內在的,否則使用行內 ASM,該指令僅在 VC 中公開;GCC__builtin_ctz不完全一樣,它只回傳一個值而不是兩個。
但是,在 AMD CPU 上,來自BMI 1集的TZCNT指令比老式BSF 稍快(在 Intel 上它們是相等的)。在 AMD 上,TZCNT 可能會稍微快一些,盡管有額外的指令來與 0 進行比較。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/422653.html
標籤: