我使用以下代碼使用隨機值創建了一個資料框:
values = random(5)
values_1= random(5)
col1= list(values/ values .sum())
col2= list(values_1)
df = pd.DataFrame({'col1':col1, 'col2':col2})
df.sort_values(by=['col2','col1'],ascending=[False,False]).reset_index(inplace=True)
在我的案例中創建的資料框如下所示:
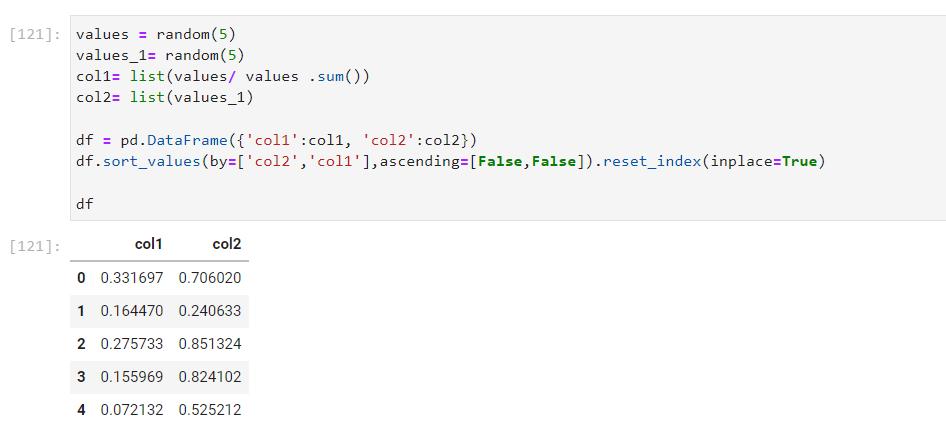
如您所見,資料框未按“col2”降序排序。我想要實作的是它首先按“col2”排序,如果任何 2 行具有相同的“col2”值,那么它也應該按“col1”排序。有什么建議?任何幫助,將不勝感激。
uj5u.com熱心網友回復:
您的解決方案幾乎運行良好,但如果inplace在其中使用reset_index它不會在sort_values.
可能的解決方案是 add ignore_index=True,所以reset_index沒有必要。
np.random.seed(2022)
df = pd.DataFrame({'col1':np.random.random(5), 'col2':np.random.random(5)})
df = df.sort_values(by=['col2','col1'],ascending=False, ignore_index=True)
print (df)
col1 col2
0 0.499058 0.897657
1 0.049974 0.896963
2 0.685408 0.721135
3 0.113384 0.647452
4 0.009359 0.486988
或者,如果只想使用inplace添加它sort_values并添加ignore_index=True:
df.sort_values(by=['col2','col1'],ascending=False, ignore_index=True,inplace=True)
print (df)
col1 col2
0 0.499058 0.897657
1 0.049974 0.896963
2 0.685408 0.721135
3 0.113384 0.647452
4 0.009359 0.486988
uj5u.com熱心網友回復:
您的邏輯是正確的,但是您在 sort_values 中錯過了 inplace=True。因此,排序實際上并沒有在您的資料框中進行。用這個替換它:
df.sort_values(by=['col2','col1'],ascending=[False,False],inplace=True)
df.reset_index(inplace=True,drop=True)
uj5u.com熱心網友回復:
您還想進行排序inplace=True,而不僅僅是reset_index()
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/424144.html
標籤:python-3.x 熊猫 数据框 麻木的 排序
上一篇:標準化多維numpy陣列