初級開發人員在這里。
目標: 實作第二個自動生成的行,其中一個專案預先填寫。第一行是空白的。
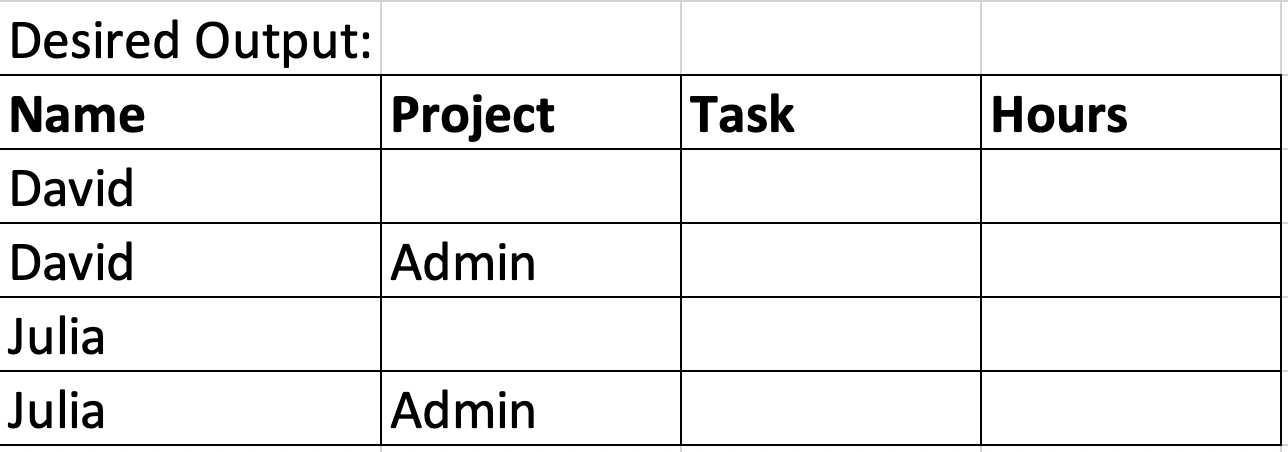
要求:
- 每個資源的第一行將保持空白。
- 第二行將有一個名為“Admin”的預生成專案名稱。
- 每個資源的行必須彼此相鄰。
- 按 ASC 順序對“名稱”行進行排序。
- 這必須應用于整個資料集(約 900 個資源,為說明幫助而創建的演示 df)。
我想我必須用 lamda 函式做一些事情,但我不清楚如何從每個資源中只填充 1 行。
當前輸出: 我在熊貓資料框中有表格。控制臺輸出是我目前擁有的。
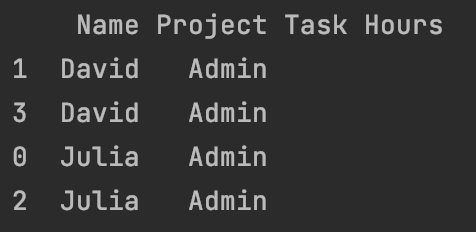
這是我在腳本中的內容。
import pandas as pd
# Demo DF only
df1 = {
'Name': ['Julia', 'David'],
'Project': ['',''],
'Task': ['',''],
'Hours': ['','']
}
df1 = pd.DataFrame(df1, columns=['Name', 'Project', 'Task','Hours'])
df1 = df1.assign(Project="Admin")
df_repeated = pd.concat([df1]*2, ignore_index=True)
df_repeated = df_repeated.sort_values(by=['Name'], ascending=True)
print(df_repeated)
uj5u.com熱心網友回復:
pd.concat([df1, df1.assign(Project="Admin")],
ignore_index=True).sort_values(["Name", "Project"])
# Name Project Task Hours
# 1 David
# 3 David Admin
# 0 Julia
# 2 Julia Admin
uj5u.com熱心網友回復:
您可以使用 numpy 的函式“ where ”在每隔一行添加“Admin”:
df1 = pd.DataFrame(df1)
df_repeated = pd.concat([df1]*2, ignore_index=True)
df_repeated = df_repeated.sort_values(by=['Name'], ascending=True, ignore_index=True)
df_repeated['Project'] = np.where(df_repeated.index % 2, 'Admin', '')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/427575.html
上一篇:比較變數之間的百分比變化
下一篇:計算大型資料框中的不同字符