我的資料集包含存盤為數字的分類值。您可以在下面看到我的資料的樣子。
data = {'id':['1','2','3','4','5'],
'nc':['01', '1.0', '2.0', '13.0',"B"]}
df = pd.DataFrame(data, columns = ['id','nc'])
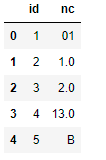
現在我想將此表與具有分類資料(例如 01、02、03 等)的表連接起來,但我不能,因為值不一樣。
那么任何人都可以幫助我如何修改此列,或者換句話說,用 “。”分隔值。并為 10 以下的數字添加零,如下表所示:
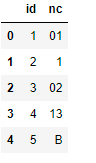
我嘗試使用這行代碼但不作業
df["nc1"]= df['nc'].str.split(".", expand = True)
uj5u.com熱心網友回復:
我們可以嘗試Series.str.len和Series.str.rstrp
df['nc'] = df['nc'].str.rstrip('.0')
df.loc[df['nc'].str.len().le(1) & df['nc'].str.isnumeric(), 'nc'] = '0' df['nc']
print(df)
id nc
0 1 01
1 2 01
2 3 02
3 4 13
4 5 B
uj5u.com熱心網友回復:
邏輯并不完全清楚,通過使用正則運算式將2.0數字更改02為非常容易:
df['nc'] = df['nc'].str.replace(r'^(\d )(\.0 )$', lambda m: m.group(1).zfill(2))
輸出(為了清楚起見,這里作為一個新列nc2):
id nc nc2
0 1 01 01
1 2 1.0 01
2 3 2.0 02
3 4 13.0 13
4 5 B B
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/429583.html
上一篇:基于列折疊DataFrame
下一篇:使用完全不同的組對條形圖進行分組