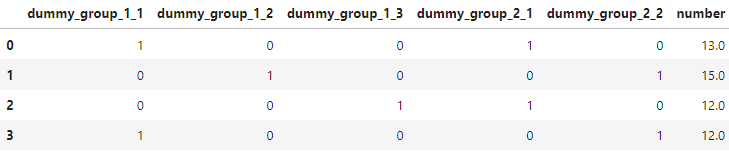
我有這些簡化的資料:
data = {'dummy_group_1_1':[1, 0, 0, 1],
'dummy_group_1_2':[0, 1, 0, 0],
'dummy_group_1_3':[0, 0, 1, 0],
'dummy_group_2_1':[1, 0, 1, 0],
'dummy_group_2_2':[0, 1, 0, 1],
'number':[13.0, 15.0, 12.0, 12.0]}
haves = pd.DataFrame(data)
haves
首先,我想水平折疊每個“虛擬變陣列” dummy_group_1 和 dummy_group_2 的列,其中條目為 1。結果將是:
dummy_group_1、dummy_group_2、數字
1, 1, 13
2, 2, 15
3, 1, 12
1, 2, 12
有很多這樣的列,我想有人可以使用這些方面的東西:haves.columns.str.startswith('dummy_group_1')?我不知道該怎么做才能做到這一點對不起......
有了這些中間結果,我想獲得 dummy_group_1 和 dummy_group_2 組合作為組合的“數字”最大值(平局情況取任何)。結果將是:
dummy_group_1,dummy_group_2,最大值
1, 1, 13
2, 2, 15
3, 1, 12
這可能嗎?
PS:
這是我進入第 1 步的悲慘長期受傷方式:
data = {'dummy_group_1_1':[1, 0, 0, 1],
'dummy_group_1_2':[0, 1, 0, 0],
'dummy_group_1_3':[0, 0, 1, 0],
'dummy_group_2_1':[1, 0, 1, 0],
'dummy_group_2_2':[0, 1, 0, 1],
'number':[13.0, 15.0, 12.0, 12.0]}
haves = pd.DataFrame(data)
haves['surrogate_key'] = haves.reset_index().index
haves
group_1 = haves.loc[:, haves.columns.str.startswith('dummy_group_1') | haves.columns.str.startswith('surrogate_key')]
group_1 = pd.melt(group_1, id_vars=['surrogate_key']).query("value > 0")
group_1.drop('value', axis=1, inplace=True)
group_1['variable'] = group_1['variable'].str.replace('dummy_group_1_', '')
group_1.columns = group_1.columns.str.replace('variable', 'dummy_group_1')
group_2 = haves.loc[:, haves.columns.str.startswith('dummy_group_2') | haves.columns.str.startswith('surrogate_key')]
group_2 = pd.melt(group_2, id_vars=['surrogate_key']).query("value > 0")
group_2.drop('value', axis=1, inplace=True)
group_2['variable'] = group_2['variable'].str.replace('dummy_group_2_', '')
group_2.columns = group_2.columns.str.replace('variable', 'dummy_group_2')
numbers = haves[['surrogate_key', 'number']]
step1_data = pd.merge(numbers, group_1, how='inner', left_on=['surrogate_key'], right_on = ['surrogate_key'])
step1_data = pd.merge(step1_data, group_2, how='inner', left_on=['surrogate_key'], right_on = ['surrogate_key'])
step1_data
鑒于richardec的部分答案,我可以得到最終結果:
step1_data.loc[step1_data.groupby('dummy_group_1')['number'].idxmax()]
這使:

uj5u.com熱心網友回復:
嘗試這樣的事情:
cols = ['number']
tmp = haves[haves.columns.difference(cols)]
tmp = pd.concat([tmp.apply(lambda col: col.map({1: int(col.name.split('_')[3])})).groupby(tmp.columns.str.split('_').str[2], axis=1).bfill().dropna(axis=1).astype(int), haves[cols]], axis=1)
tmp = tmp.loc[tmp.groupby('dummy_group_1_1')['number'].idxmax()]
輸出:
>>> tmp
dummy_group_1_1 dummy_group_2_1 number
0 1 1 13.0
1 2 2 15.0
2 3 1 12.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/429588.html
上一篇:Python中的JSON決議問題
下一篇:Pandas多級列資料框