我正在嘗試將 Google n-gram 詞頻資料上傳到資料框中。
資料集可以在這里找到: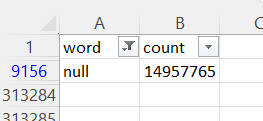
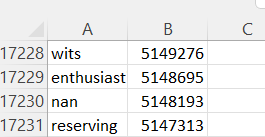
這就是我上傳資料的方式
my_freq_df = pd.read_csv('ngram_freq_dict.csv', dtype = {"word": str, "count": np.int32} )
my_freq_df['word'] = my_freq_df['word'].astype("string")
不幸的是,當我嘗試檢查這些單詞是否作為字串加載時,我發現它們不是
count = 0
for index, row in my_freq_df.iterrows():
count = 1
try:
len(row['word'])
except:
print(row['word'])
print(count)
print("****____*****")
我們可以看到 try 的輸出影像,除了我們可以看到我無法計算單詞“nan”和“null”的長度。這兩個詞都被讀作 NA。
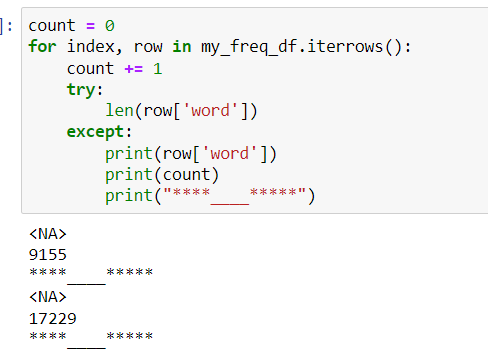
我該如何解決?
uj5u.com熱心網友回復:
Pandas 默認將一組特定值視為“NA”,但您可以明確告訴它忽略這些默認值keep_default_na=False。“null”和“nan”都恰好在該串列中!
my_freq_df = pd.read_csv(
'ngram_freq_dict.csv',
dtype = {"word": str, "count": np.int32},
keep_default_na=False
)
截至今天,它默認視為 NA 的完整字串集是:
[
"", "#N/A", "#N/A N/A", "#NA", "-1.#IND", "-1.#QNAN", "-NaN",
"-nan", "1.#IND", "1.#QNAN", "<NA>", "N/A", "NA", "NULL",
"NaN", "n/a", "nan", "null"
]
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/429600.html
上一篇:保存和加載串列值?