我一直在網上抓取一個包含許多化合物資訊的網站。問題是盡管所有頁面都有一些相同的資訊,但它并不一致。所以這意味著每次提取我都會有不同數量的列。我想在 Excel 檔案中組織所有內容,以便更輕松地過濾我想要的資訊,但我遇到了很多麻煩。
示例(盡管提取的不僅僅是 3 個資料幀):DF 1 - 從網頁抓取第一頁
| 化合物名稱 | 研究型別 | Cas 編號 | 歐共體名稱 | 評論 | 結論 |
|---|---|---|---|---|---|
| 阿司匹林 | 具體的 | 3439-73-9 | 阿司匹林 | 重復 | 得到正式認可的 |
DF 2 - 來自網路抓取
| 化合物名稱 | 研究型別 | Cas 編號 | 歐共體名稱 | 評論 | 結論 | 概括 |
|---|---|---|---|---|---|---|
| 表皮生長因子受體 | 具體的 | 738-9-8 | 表皮生長因子受體 | 重復 | 不批準 | 無定論 |
DF 3 - 來自網路抓取
| 化合物名稱 | 研究型別 | Cas 編號 | 評論 | 結論 |
|---|---|---|---|---|
| 苯甲醛 | 具體的 | 384-92-2 | 重復 | 不批準 |
我想要的是這樣的:
最終 DF(影像)
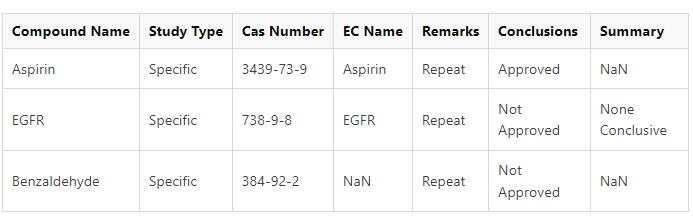
我用 pd.concat 嘗試了很多東西,但所有嘗試都沒有成功。
我得到的最接近的是與此類似的東西,重復列:
| 化合物名稱 | 研究型別 | Cas 編號 | 歐共體名稱 | 評論 | 結論 |
|---|---|---|---|---|---|
| 阿司匹林 | 具體的 | 3439-73-9 | 阿司匹林 | 重復 | 得到正式認可的 |
| 化合物名稱 | 研究型別 | Cas 編號 | 評論 | 結論 | |
| 苯甲醛 | 具體的 | 384-92-2 | 重復 | 不批準 | |
| 化合物名稱 | 研究型別 | Cas 編號 | 歐共體名稱 | 評論 | 結論 |
| 表皮生長因子受體 | 具體的 | 738-9-8 | 表皮生長因子受體 | 重復 | 不批準 |
這是我正在嘗試撰寫的一些當前代碼:
compound_info = []
descriptor_info = []
df_list = []
df = pd.DataFrame()
df_final = pd.DataFrame(columns=['Compound Name',
'Study Type',
'CAS Number',
'EC Name',
'Remarks',
'Conclusions'])
for i in range(1,num_btn_selecionar 1):
time.sleep(10)
driver.find_element_by_xpath('//*[@id="SectionHeader"]/div[3]/select/option[' str(i) ']').click()
page_source = driver.page_source
soup = BeautifulSoup(page_source, "html.parser")
info = soup.find_all("dl", {'class':'HorDL'})
lista_info = len(info)
all_info_compound = []
all_descrip_compound = []
for y in range(0, lista_info):
for z in info[y].find_all('dd'):
all_info_compound.append(z.text)
for w in info[y].find_all('dt'):
all_descrip_compound.append(w.text)
compound_info.append(all_info_compound)
descriptor_info.append(all_descrip_compound)
data_tuples = list(zip(all_descrip_compound[1:],all_info_compound[1:]))
temp_df = pd.DataFrame(data_tuples)
data_transposed = temp_df.T
#df_list.append(data_transposed)
pd.concat([df_final,data_transposed], ignore_index=True, axis=0)
我得到的錯誤是:
InvalidIndexError: Reindexing only valid with uniquely valued Index objects
我將非常感謝您的幫助!
uj5u.com熱心網友回復:
pd.concat應該做的作業。該錯誤的原因是 中的一個資料框concat很可能是data_transposed有兩列共享相同的名稱。要看到這一點,您可以將最后一行替換為
try:
df_final = pd.concat([df_final,data_transposed], ignore_index=True, axis=0)
except Exception as e:
print('Error:', e)
print('df_final:', df_final.columns)
print('data_transposed:', data_transposed.columns)
同樣在你的最后一行中,你永遠不會用新的連接的覆寫你df_final的,你需要df_final = 在前面,因為我已經添加到我上面的代碼中。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/429604.html