我是計算機視覺的新手,并試圖實作我的第一個模型,但準確度停留在 0.04,而且我猜問題不是欠采樣。這是我的 Keras 模型:
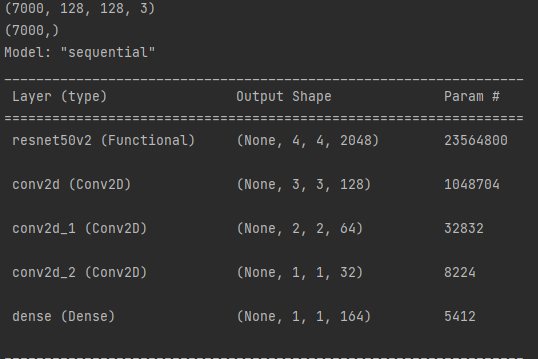
正如您在圖片中看到的那樣,我有 10 000 個輸入作為 p train 0 測驗我正在使用 Resnet50v2 和 CNN 和 relu 激活:
base_model = ResNet50V2(weights='imagenet',
include_top=False,
input_shape=(width, height, 3))
base_model.trainable = False
model = Sequential([
base_model,
Conv2D(128, (2, 2), activation="relu"),
Conv2D(64, (2, 2), activation="relu"),
Conv2D(32, (2, 2), activation="relu"),
Dense(164, activation="softmax")
])
我的準確度水平就像照片上的一樣
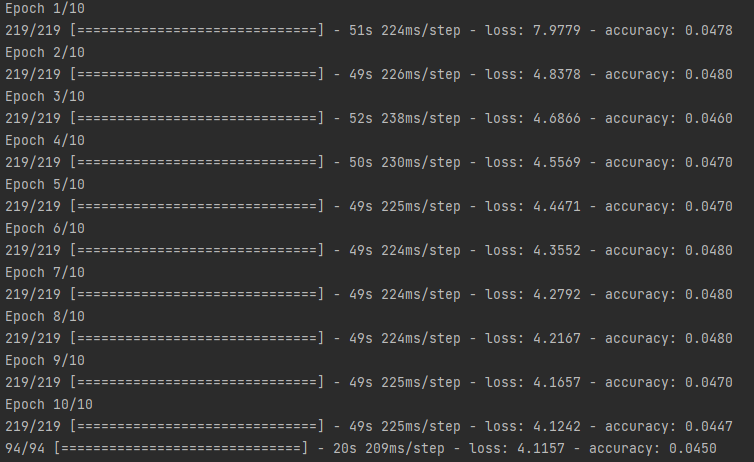
我不知道自己做錯了什么我嘗試更改圖層、輸入大小并將樣本大小增加 20 000 或更多,但我仍然無法提高我的準確性。
這種準確性對于 164 個不同的標簽是正常的,還是我對此主題缺乏了解,有什么方法可以建議您改進它還是應該減少標簽數量?
uj5u.com熱心網友回復:
看看你的損失值。在第 10 個 epoch,它顯示 4.1157,這是巨大的。理想情況下,您的損失值應該接近于零。所以這意味著你必須訓練它更多的時期,直到你的損失接近于零。
現在讓我們談談準確性。螢屏截圖中顯示的準確度:如果是訓練準確度,那么您的準確度應該通過訓練更多時期(減少損失值)來提高。如果它是測驗/驗證準確性,那么它應該增加或減少。 增加意味著模型現在學習得很好。 減少意味著您的模型已經過擬合。
uj5u.com熱心網友回復:
從 ResNet50 中提取特征后,您應用了 Conv2D 層并將特征的大小減少到只有 32 個,這不足以容納可用于從 164 個標簽中分類為 1 的特征。所以盡量不要那樣做。
根據@Alonso,您的資料集包含 10k 個樣本和 164 個標簽,這意味著每個標簽平均大約 61 個樣本,這不足以讓模型學習,因此模型預計會過擬合。您可以通過增加影像并在模型架構中使用 Dropout 層來避免過度擬合問題。
所以試試這個:
base_model = ResNet50V2(weights='imagenet',
include_top=False,
input_shape=(width, height, 3))
base_model.trainable = False
model = Sequential([
base_model,
GlobalAveragePooling2D(),
Dropout(0.2),
Dense(2048, activation='relu'),
Dropout(0.2),
Dense(164, activation="softmax")
])
如果這沒有產生好的結果,請嘗試使用超引數進行試驗,并可能設定base_model.trainable = True
使用的優化器和學習率在訓練模型中也起著重要作用,所以也嘗試一下。如果學習率太高,那么模型將無法達到很高的準確率,同樣,如果學習率太低,則需要大量的 epoch 才能達到良好的準確率。
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/429744.html