我有一個非常巨大的資料框的示例資料框,如下所示。
import pandas as pd
import numpy as np
NaN = np.nan
data = {'Start_x':['Tom', NaN, NaN, NaN,NaN],
'Start_y':[NaN, 'Nick', NaN, NaN, NaN],
'Start_z':[NaN, NaN, 'Alison', NaN, NaN],
'Start_a':[NaN, NaN, NaN, 'Mark',NaN],
'Start_b':[NaN, NaN, NaN, NaN, 'Oliver'],
'Sex': ['Male','Male','Female','Male','Male']}
df = pd.DataFrame(data)
df
我希望最終結果看起來像下面給出的影像。4 列必須合并為一個新列,但“Sex”列應保持原樣。
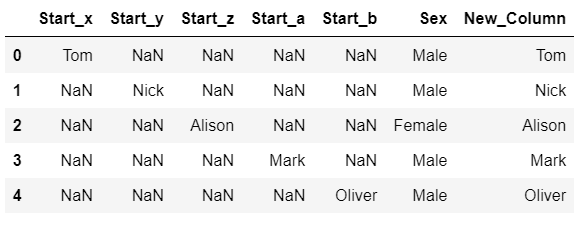
任何幫助是極大的贊賞。謝謝!
uj5u.com熱心網友回復:
一個選項可能是Start按行回填列,然后取第一列:
df['New_Column'] = df.filter(like='Start').bfill(axis=1).iloc[:, 0]
df
Start_x Start_y Start_z Start_a Start_b Sex New_Column
0 Tom NaN NaN NaN NaN Male Tom
1 NaN Nick NaN NaN NaN Male Nick
2 NaN NaN Alison NaN NaN Female Alison
3 NaN NaN NaN Mark NaN Male Mark
4 NaN NaN NaN NaN Oliver Male Oliver
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/432186.html
標籤:python-3.x 熊猫 数据框 数据科学 数据分析