DATA <- data.frame("V1" = c("SCORE : 9.931 5.092",
"SCORE : 6.00007 15.1248",
"SCORE : 1.0002 12.987532",
"SCORE : 3.1 3.98532"))
WANT <- data.frame("VAR1" = c(9.931, 6.00007, 1.0002, 3.1),
'VAR2' = c(5.092, 15.1248, 12.987532, 3.98532))
我所擁有的是輸入的學生考試成績資料,如“DATA”中所示,但我希望將其拆分,以便我擁有的內容類似于“WANT”框架中顯示的內容,其中第一個數字在“VAR1”中,而第二個數字在“VAR2”中,忽略空格
我的嘗試:
DATA[, c("VAR1", "VAR2") := trimws(V1, whitespace = ".*:\\s ")]
生產:
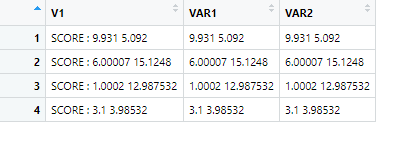
uj5u.com熱心網友回復:
我們可以洗掉前綴子字串并使用with作為默認空間trimws讀取列以回傳兩列read.tablesepdata.framebase R
read.table(text = trimws(DATA$V1, whitespace = ".*:\\s "),
header = FALSE, col.names = c("VAR1", "VAR2"))
VAR1 VAR2
1 9.93100 5.09200
2 6.00007 15.12480
3 1.00020 12.98753
4 3.10000 3.98532
或者可以使用extractfromtidyr
library(tidyr)
extract(DATA, V1, into = c("VAR1", "VAR2"),
".*:\\s ([0-9.] )\\s ([0-9.] )", convert = TRUE)
VAR1 VAR2
1 9.93100 5.09200
2 6.00007 15.12480
3 1.00020 12.98753
4 3.10000 3.98532
如果我們愿意data.table,使用相同的方法可以fread在洗掉前綴子字串后讀取
library(data.table)
fread(text = setDT(DATA)[, trimws(V1, whitespace = ".*:\\s ")],
col.names = c("VAR1", "VAR2"))
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
或使用中的select選項fread
fread(text = DATA$V1, select = c(3, 4), col.names = c("VAR1", "VAR2"))
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
或讀為四列和子集
fread(text = DATA$V1)[, .(VAR1 = V3, VAR2 = V4)]
VAR1 VAR2
<num> <num>
1: 9.93100 5.09200
2: 6.00007 15.12480
3: 1.00020 12.98753
4: 3.10000 3.98532
或者可以使用tstrsplit
setDT(DATA)[, c("VAR1", "VAR2") := tstrsplit(trimws(V1,
whitespace = ".*:\\s "), " ")]
DATA <- type.convert(DATA, as.is = TRUE)
DATA
V1 VAR1 VAR2
<char> <num> <num>
1: SCORE : 9.931 5.092 9.93100 5.09200
2: SCORE : 6.00007 15.1248 6.00007 15.12480
3: SCORE : 1.0002 12.987532 1.00020 12.98753
4: SCORE : 3.1 3.98532 3.10000 3.98532
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/434511.html
上一篇:使用String引數創建結構