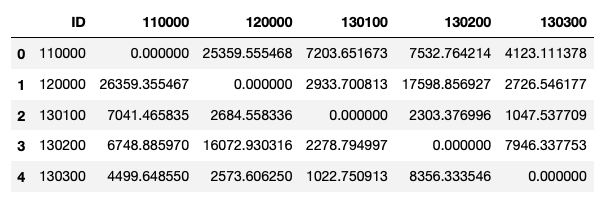
我有一個熊貓資料框,如下所示:
import pandas as pd
dist_temp = {'ID': {0: '110000', 1: '120000', 2: '130100', 3: '130200', 4: '130300'},
'110000': {0: 0.0,
1: 26359.35546663972,
2: 7041.465835419961,
3: 6748.88597016984,
4: 4499.648549689056},
'120000': {0: 25359.55546817345,
1: 0.0,
2: 2684.5583355637195,
3: 16072.930316000879,
4: 2573.60624992548},
'130100': {0: 7203.651673447513,
1: 2933.7008133762006,
2: 0.0,
3: 2278.794996954,
4: 1022.7509126175601},
'130200': {0: 7532.764214042125,
1: 17598.85692679548,
2: 2303.3769962313604,
3: 0.0,
4: 8356.33354580892},
'130300': {0: 4123.111378129952,
1: 2726.5461773558404,
2: 1047.53770945992,
3: 7946.337752637479,
4: 0.0}}
df = pd.DataFrame(dist_temp)
有沒有辦法加快以下例程:
df_1 = pd.DataFrame(columns = ['IDo', 'IdD', 'flux'])
for i in range(0,len(df.columns)-1):
j =0
for x in df.itertuples():
df_1 = df_1.append({'IDo': df.columns[i 1], 'IdD': x[j 1],'flux': x[i 2]}, ignore_index = True)
j = j 1
df_1['flux'] = df_1['flux'].fillna(0)
print (df_1)
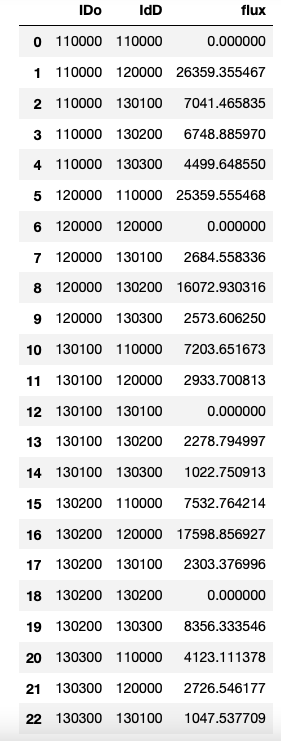
Desired output is as shown above, where the title of the second column in this case (110000) comes in the output Dataframe as IDo in the rows (0-4) and the the first five rows (0-4) in the input Dataframe with value of 110000, 12000, 130100, 130200, 130300 comes in the output Dataframe as IdD (which is the second column in the output dataframe). And the third column in output Dataframe (flux) contributes to value corresponding to the intersecting points in the input Dataframe such as 0.000000 is the value on intersection when 110000 (title of column 1 input dataframe) and 110000 (number on second row), 26359.355467 is the value when 110000 (title of column 1 dataframe) and 120000 (number on second row) and so on.
For small Dataframe this method is not a problem. But for a 500 rows x 500 columns Dataframe it is taking enormous time.
Sorry for this naive question, I am new to Pandas.
Thankyou
uj5u.com熱心網友回復:
Pandas 有很多很好的選擇來重塑資料框。
在這種情況下,DataFrame.melt很方便:
df.melt(id_vars="ID", value_name="Flux", var_name="IDo")
對于前 10 行,我得到:
ID IDo Flux
0 110000 110000 0.000000
1 120000 110000 26359.355467
2 130100 110000 7041.465835
3 130200 110000 6748.885970
4 130300 110000 4499.648550
5 110000 120000 25359.555468
6 120000 120000 0.000000
7 130100 120000 2684.558336
8 130200 120000 16072.930316
9 130300 120000 2573.606250
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/445067.html
標籤:python pandas dataframe for-loop
下一篇:使用for回圈標題案例一個句子