Vue3 diff演算法圖解分析
大家好,我是劍大瑞,本篇文章主要分析Vue3 diff演算法,通過本文你可以知道:
diff的主要程序,核心邏輯diff是如何進行節點復用、移動、卸載- 并有一個示例題,可以結合本文進行練習分析
如果你還不是特別了解Vnode、渲染器的patch流程,建議先閱讀下面兩篇文章:
- Vnode
- 渲染器分析
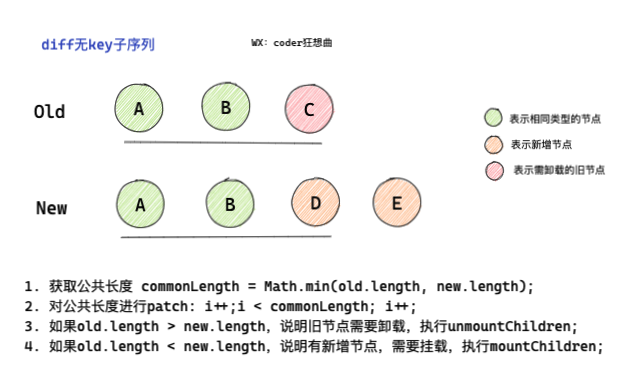
1.0 diff 無key子節點
在處理被標記為UNKEYED_FRAGMENT時,
-
首先會通過新舊子序列獲取最小共同長度
commonLength, -
對公共部分回圈遍歷
patch, -
patch結束,再處理剩余的新舊節點, -
如果
oldLength > newLength,說明需要對舊節點進行unmount -
否則,說明有新增節點,需要進行
mount;
這里貼下省略后的代碼,
const patchUnkeyedChildren = (c1, c2,...res) => {
c1 = c1 || EMPTY_ARR
c2 = c2 || EMPTY_ARR
// 獲取新舊子節點的長度
const oldLength = c1.length
const newLength = c2.length
// 1. 取得公共長度,最小長度
const commonLength = Math.min(oldLength, newLength)
let i
// 2. patch公共部分
for (i = 0; i < commonLength; i++) {
patch(...)
}
// 3. 卸載舊節點
if (oldLength > newLength) {
// remove old
unmountChildren(...)
} else {
// mount new
// 4. 否則掛載新的子節點
mountChildren(...)
}
}
從上面的代碼可以看出,在處理無key子節點的時候,邏輯還是非常簡單粗暴的,準確的說處理無key子節點的效率并不高,
因為不管是直接對公共部分patch,還是直接對新增節點進行mountChildren(其實是遍歷子節點,進行patch操作),其實都是在遞回進行patch,這就會影響到性能,
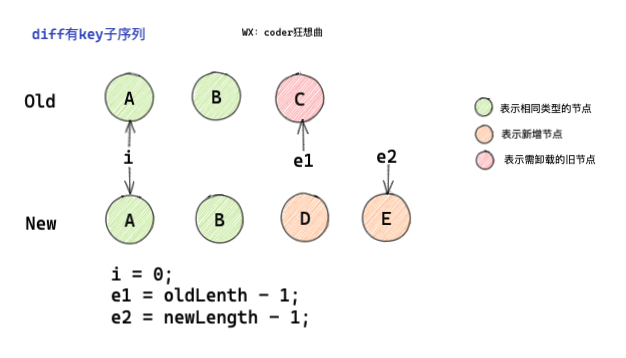
2.0 diff 有key子節點序列
在diff有key子序列的時候,會進行細分處理,主要會經過以下一種情況的判斷:
- 起始位置節點型別相同,
- 結束位置節點型別相同,
- 相同部分處理完,有新增節點,
- 相同部分處理完,有舊節點需要卸載,
- 首尾相同,但中間部分存在可復用亂序節點,
在開始階段,會先生面三個指正,分別是:
i = 0,指向新舊序列的開始位置e1 = oldLength - 1,指向舊序列的結束位置e2 = newLength - 1,指向新序列的結束位置
let i = 0
const l2 = c2.length
let e1 = c1.length - 1 // prev ending index
let e2 = l2 - 1 // next ending index
下面開始分情況進行diff處理,
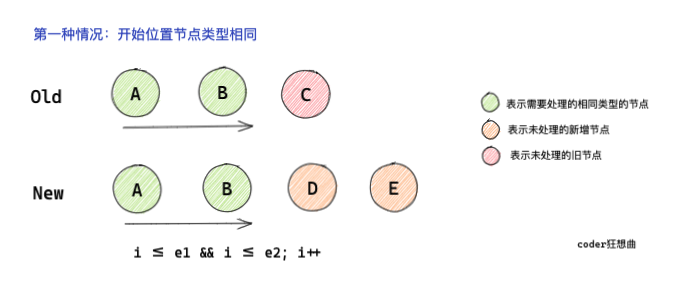
2.1 起始位置節點型別相同
-
對于起始位置型別相同的節點,從左向右進行
diff遍歷, -
如果新舊節點型別相同,則進行
patch處理 -
節點型別不同,則
break,跳出遍歷diff
// i <= 2 && i <= 3
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = c2[i]
if (isSameVNodeType(n1, n2)) {
// 如果是相同的節點型別,則進行遞回patch
patch(...)
} else {
// 否則退出
break
}
i++
}
上面上略了部分代碼,但不影響主要邏輯,
從代碼可以知道,遍歷時,利用前面在函式全域背景關系中宣告的三個指標,進行遍歷判斷,
保證能充分遍歷到開始位置相同的位置,i <= e1 && i <= e2,
一旦遇到型別不同的節點,就會跳出diff遍歷,
2.2 結束位置節點型別相同
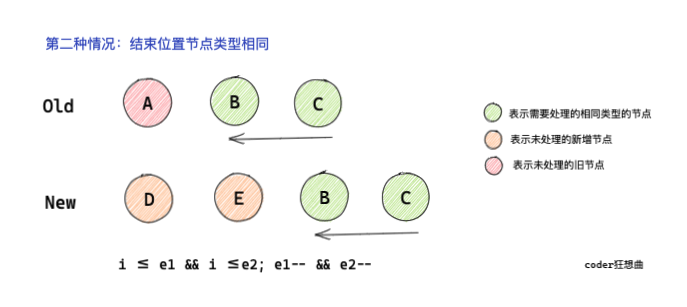
開始位置相同diff 結束,會緊接著從序列尾部開始遍歷 diff,
此時需要對尾指標e1、e2進行遞減,
// i <= 2 && i <= 3
// 結束后: e1 = 0 e2 = 1
while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = c2[e2]
if (isSameVNodeType(n1, n2)) {
// 相同的節點型別
patch(...)
} else {
// 否則退出
break
}
e1--
e2--
}
從代碼可以看出,diff邏輯與第一種基本一樣,相同型別進行patch處理,
不同型別break,跳出回圈遍歷,
并且對尾指標進行遞減操作,
2.3 相同部分遍歷結束,新序列中有新增節點,進行掛載
經過上面兩種情況的處理,已經patch完首尾相同部分的節點,接下來是對新序列中的新增節點進行patch處理,
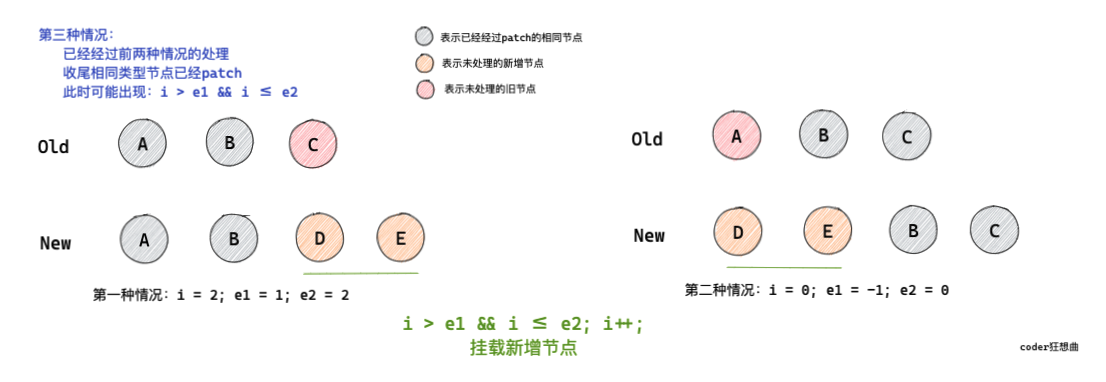
在經過上面兩種請款處理之后,如果有新增節點,可能會出現 i > e1 && i <= e2的情況,
這種情況下意味著新的子節點序列中有新增節點,
這時會對新增節點進行patch,
// 3. common sequence + mount
// (a b)
// (a b) c
// i = 2, e1 = 1, e2 = 2
// (a b)
// c (a b)
// i = 0, e1 = -1, e2 = 0
if (i > e1) {
if (i <= e2) {
const nextPos = e2 + 1
// nextPos < l2,說明有已經patch過尾部節點,
// 否則會獲取父節點作為錨點
const anchor = nextPos < l2 ? c2[nextPos].el : parentAnchor
while (i <= e2) {
patch(null, c2[i], anchor, ...others)
i++
}
}
}
從上面的代碼可以知道,patch的時候沒有傳第一個引數,最侄訓走mount的邏輯,
可以看這篇主要分析patch的程序
在patch的程序中,會遞增i指標,
并通過nextPos來獲取錨點,
如果nextPos < l2,則以已經patch的節點作為錨點,否則以父節點作為錨點,
2.4 相同部分遍歷結束,新序列中少節點,進行卸載
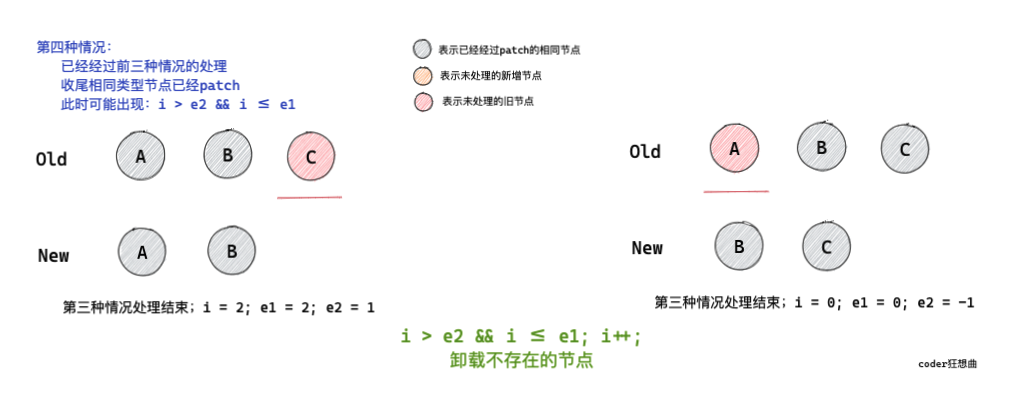
如果處理完收尾相同的節點,出現i > e2 && i <= e1的情況,則意味著有舊節點需要進行卸載操作,
// 4. common sequence + unmount
// (a b) c
// (a b)
// i = 2, e1 = 2, e2 = 1
// a (b c)
// (b c)
// i = 0, e1 = 0, e2 = -1
// 公共序列 卸載舊的
else if (i > e2) {
while (i <= e1) {
unmount(c1[i], parentComponent, parentSuspense, true)
i++
}
}
通過代碼可以知道,這種情況下,會遞增i指標,對舊節點進行卸載,
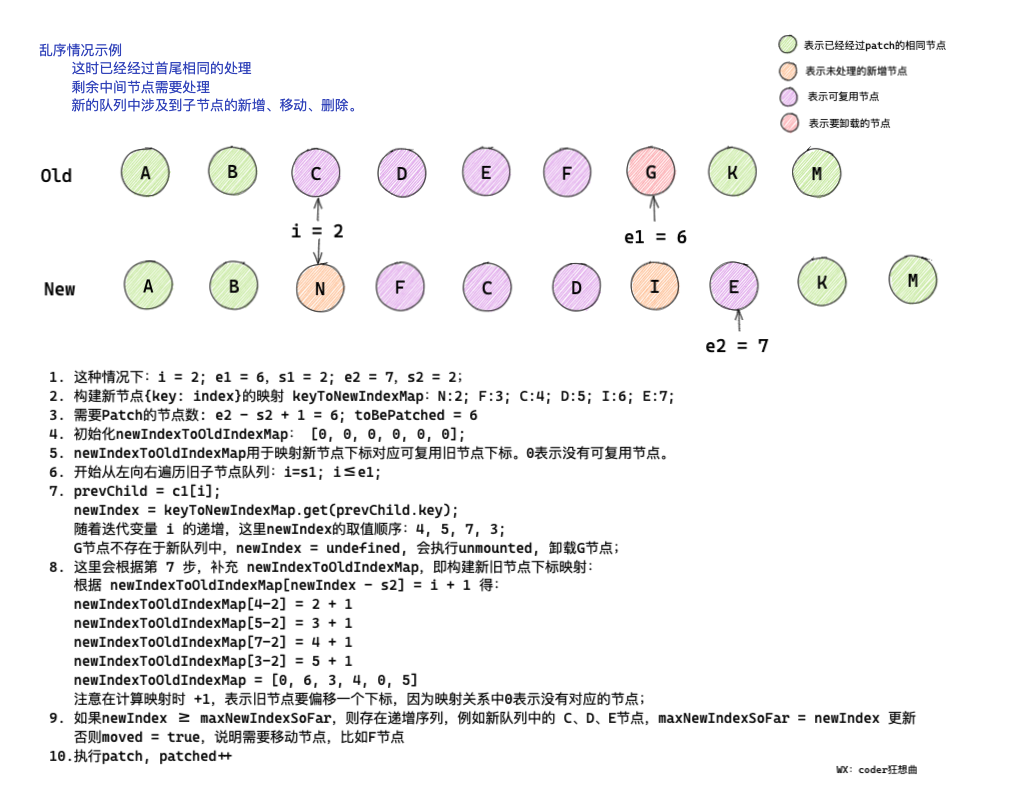
2.5 亂序情況
這種情況下較為復雜,但diff的核心邏輯在于通過新舊節點的位置變化構建一個最大遞增子序列,最大子序列能保證通過最小的移動或者patch實作節點的復用,
下面一起來看下如何實作的,
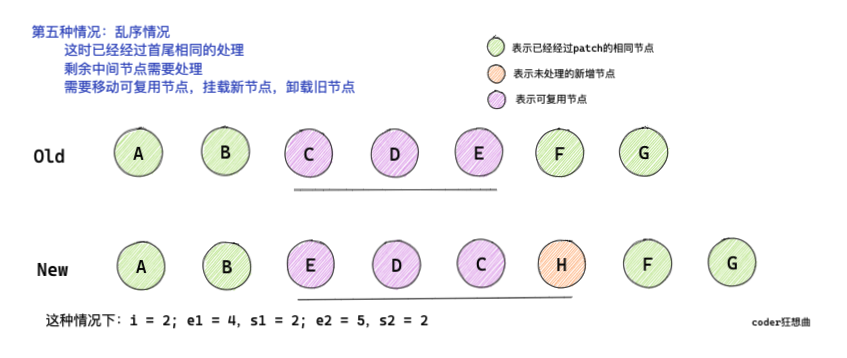
2.5.1 為新子節點構建key:index映射
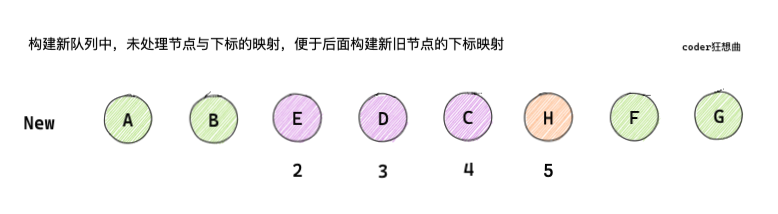
// 5. 亂序的情況
// [i ... e1 + 1]: a b [c d e] f g
// [i ... e2 + 1]: a b [e d c h] f g
// i = 2, e1 = 4, e2 = 5
const s1 = i // s1 = 2
const s2 = i // s2 = 2
// 5.1 build key:index map for newChildren
// 首先為新的子節點構建在新的子序列中 key:index 的映射
// 通過map 創建的新的子節點
const keyToNewIndexMap = new Map()
// 遍歷新的節點,為新節點設定key
// i = 2; i <= 5
for (i = s2; i <= e2; i++) {
// 獲取的是新序列中的子節點
const nextChild = c2[i];
if (nextChild.key != null) {
// nextChild.key 已存在
// a b [e d c h] f g
// e:2 d:3 c:4 h:5
keyToNewIndexMap.set(nextChild.key, i)
}
}
結合上面的圖和代碼可以知道:
-
在經過首尾相同的
patch處理之后,i = 2,e1 = 4,e2 = 5 -
經過遍歷之后
keyToNewIndexMap中,新節點的key:index的關系為E : 2、D : 3 、C : 4、H : 5 -
keyToNewIndexMap的作用主要是后面通過遍歷舊子序列,確定可復用節點在新的子序列中的位置
2.5.2 從左向右遍歷舊子序列,patch匹配的相同型別的節點,移除不存在的節點
經過前面的處理,已經創建了keyToNewIndexMap,
在開始從左向右遍歷之前,需要知道幾個變數的含義:
// 5.2 loop through old children left to be patched and try to patch
// matching nodes & remove nodes that are no longer present
// 從舊的子節點的左側開始回圈遍歷進行patch,
// 并且patch匹配的節點 并移除不存在的節點
// 已經patch的節點個數
let patched = 0
// 需要patch的節點數量
// 以上圖為例:e2 = 5; s2 = 2; 知道需要patch的節點個數
// toBePatched = 4
const toBePatched = e2 - s2 + 1
// 用于判斷節點是否需要移動
// 當新舊佇列中出現可復用節點交叉時,moved = true
let moved = false
// used to track whether any node has moved
// 用于記錄節點是否已經移動
let maxNewIndexSoFar = 0
// works as Map<newIndex, oldIndex>
// 作新舊節點的下標映射
// Note that oldIndex is offset by +1
// 注意 舊節點的 index 要向右偏移一個下標
// and oldIndex = 0 is a special value indicating the new node has
// no corresponding old node.
// 并且舊節點Index = 0 是一個特殊的值,用于表示新的節點中沒有對應的舊節點
// used for determining longest stable subsequence
// newIndexToOldIndexMap 用于確定最長遞增子序列
// 新下標與舊下標的map
const newIndexToOldIndexMap = new Array(toBePatched)
// 將所有的值初始化為0
// [0, 0, 0, 0]
for (i = 0; i < toBePatched; i++) newIndexToOldIndexMap[i] = 0
- 變數
patched用于記錄已經patch的節點 - 變數
toBePatched用于記錄需要進行patch的節點個數 - 變數
moved用于記錄是否有可復用節點發生交叉 maxNewIndexSoFar用于記錄當舊的子序列中存在沒有設定key的子節點,但是該子節點出現于新的子序列中,且可復用,最大下標,- 變數
newIndexToOldIndexMap用于映射新的子序列中的節點下標 對應于 舊的子序列中的節點的下標 - 并且會將
newIndexToOldIndexMap初始化為一個全0陣列,[0, 0, 0, 0]
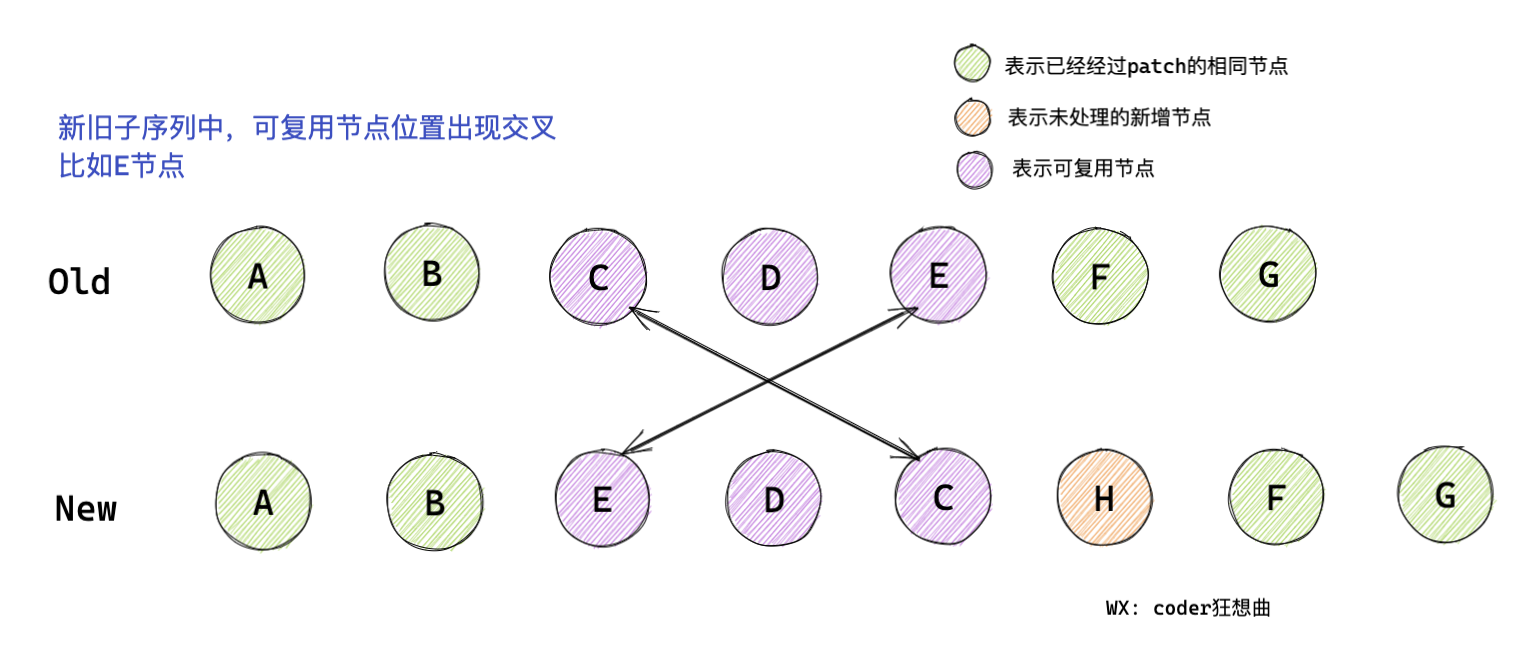
知道了這些變數的含義之后 我們就可以開始從左向右遍歷子序列了,
遍歷的時候,需要首先遍歷舊子序列,起點是s1,終點是e1,
遍歷的程序中會對patched進行累加,
卸載舊節點
如果patched >= toBePatched,說明新子序列中的子節點少于舊子序列中的節點數量,
需要對舊子節點進行卸載,
// 遍歷未處理舊序列中子節點
for (i = s1; i <= e1; i++) {
// 獲取舊節點
// 會逐個獲取 c d e
const prevChild = c1[i]
// 如果已經patch 的數量 >= 需要進行patch的節點個數
// patched剛開始為 0
// patched >= 4
if (patched >= toBePatched) {
// all new children have been patched so this can only be a removal
// 這說明所有的新節點已經被patch 因此可以移除舊的
unmount(prevChild, parentComponent, parentSuspense, true)
continue
}
}
如果prevChild.key是存在的,會通過前面我們構建的keyToNewIndexMap,獲取prevChild在新子序列中的下標newIndex,
獲取newIndex
// 新節點下標
let newIndex
if (prevChild.key != null) {
// 舊的節點肯定有key,
// 根據舊節點key 獲取相同型別的新的子節點 在 新的佇列中對應節點位置
// 這個時候 因為c d e 是原來的節點 并且有key
// h 是新增節點 舊節點中沒有 獲取不到 對應的index 會走else
// 所以newIndex在開始時會有如下情況
/**
* node newIndex
* c 4
* d 3
* e 2
* */
// 這里是可以獲取到newIndex的
newIndex = keyToNewIndexMap.get(prevChild.key)
}
以圖為例,可以知道,在遍歷程序中,節點c、d、e為可復用節點,分別對應新子序列中的2、3、4的位置,
故newIndex可以取到的值為4、3、2,
如果舊節點沒有key怎么辦?
// key-less node, try to locate a key-less node of the same type
// 如果舊的節點沒有key
// 則會查找沒有key的 且為相同型別的新節點在 新節點佇列中 的位置
// j = 2: j <= 5
for (j = s2; j <= e2; j++) {
if (
newIndexToOldIndexMap[j - s2] === 0 &&
// 判斷是否是新舊節點是否相同
isSameVNodeType(prevChild, c2[j])
) {
// 獲取到相同型別節點的下標
newIndex = j
break
}
}
如果節點沒有key,則同樣會取新子序列中,遍歷查找沒有key且兩個新舊型別相同子節點,并以此節點的下標,作為newIndex,
newIndexToOldIndexMap[j - s2] === 0 說明節點沒有該節點沒有key,
如果還沒有獲取到newIndex,說明在新子序列中沒有存在的與 prevChild 相同的子節點,需要對prevChild進行卸載,
if (newIndex === undefined) {
// 沒有對應的新節點 卸載舊的
unmount(prevChild, parentComponent, parentSuspense, true)
}
否則,開始根據newIndex,構建keyToNewIndexMap,明確新舊節點對應的下標位置,
時刻牢記
newIndex是根據舊節點獲取的其在新的子序列中的下標,
// 這里處理獲取到newIndex的情況
// 開始整理新節點下標 Index 對于 相同型別舊節點在 舊佇列中的映射
// 新節點下標從 s2=2 開始,對應的舊節點下標需要偏移一個下標
// 0 表示當前節點沒有對應的舊節點
// 偏移 1個位置 i從 s1 = 2 開始,s2 = 2
// 4 - 2 獲取下標 2,新的 c 節點對應舊 c 節點的位置下標 3
// 3 - 2 獲取下標 1,新的 d 節點對應舊 d 節點的位置下標 4
// 2 - 2 獲取下標 0,新的 e 節點對應舊 e 節點的位置下標 5
// [0, 0, 0, 0] => [5, 4, 3, 0]
// [2,3,4,5] = [5, 4, 3, 0]
newIndexToOldIndexMap[newIndex - s2] = i + 1
// newIndex 會取 4 3 2
/**
* newIndex maxNewIndexSoFar moved
* 4 0 false
* 3 4 true
* 2
*
* */
if (newIndex >= maxNewIndexSoFar) {
maxNewIndexSoFar = newIndex
} else {
moved = true
}
在構建newIndexToOldIndexMap的同時,會通過判斷newIndex、maxNewIndexSoFa的關系,確定節點是否發生移動,
newIndexToOldIndexMap最后遍歷結束應該為[5, 4, 3, 0],0說明有舊序列中沒有與心序列中對應的節點,并且該節點可能是新增節點,
如果新舊節點在序列中相對位置保持始終不變,則maxNewIndexSoFar會隨著newIndex的遞增而遞增,
意味著節點沒有發生交叉,也就不需要移動可復用節點,
否則可復用節點發生了移動,需要對可復用節點進行move,
遍歷的最后,會對新舊節點進行patch,并對patched進行累加,記錄已經處理過幾個節點,
// 進行遞回patch
/**
* old new
* c c
* d d
* e e
*/
patch(
prevChild,
c2[newIndex],
container,
null,
parentComponent,
parentSuspense,
isSVG,
slotScopeIds,
optimized
)
// 已經patch的
patched++
經過上面的處理,已經完成對舊節點進行了卸載,對相對位置保持沒有變化的子節點進行了patch復用,
接下來就是需要移動可復用節點,掛載新子序列中新增節點,
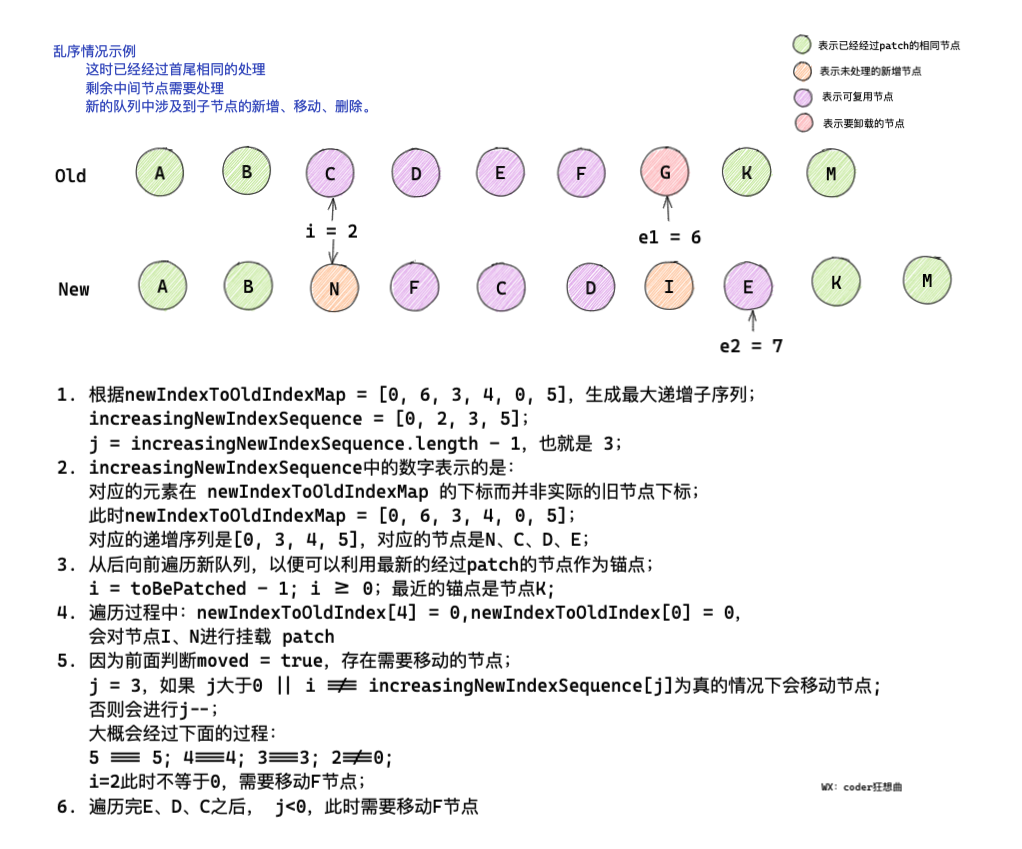
2.5.3 移動可復用節點,掛載新增節點
這里涉及到一塊比較核心的代碼,也是Vue3 diff效率提升的關鍵所在,
前面通過newIndexToOldIndexMap,記錄了新舊子節點變化前后的下標映射,
這里會通過getSequence方法獲取一個最大遞增子序列,用于記錄相對位置沒有發生變化的子節點的下標,
根據此遞增子序列,可以實作在移動可復用節點的時候,只移動相對位置前后發生變化的子節點,
做到最小改動,
那什么是最大遞增子序列?
- 子序列是由陣列派生而來的序列,洗掉(或不洗掉)陣列中的元素而不改變其余元素的順序,
- 而遞增子序列,是陣列派生的子序列,各元素之間保持逐個遞增的關系,
- 例如:
- 陣列
[3, 6, 2, 7]是陣列[0, 3, 1, 6, 2, 2, 7]的最長嚴格遞增子序列, - 陣列
[2, 3, 7, 101]是陣列[10 , 9, 2, 5, 3, 7, 101, 18]的最大遞增子序列, - 陣列
[0, 1, 2, 3]是陣列[0, 1, 0, 3, 2, 3]的最大遞增子序列,
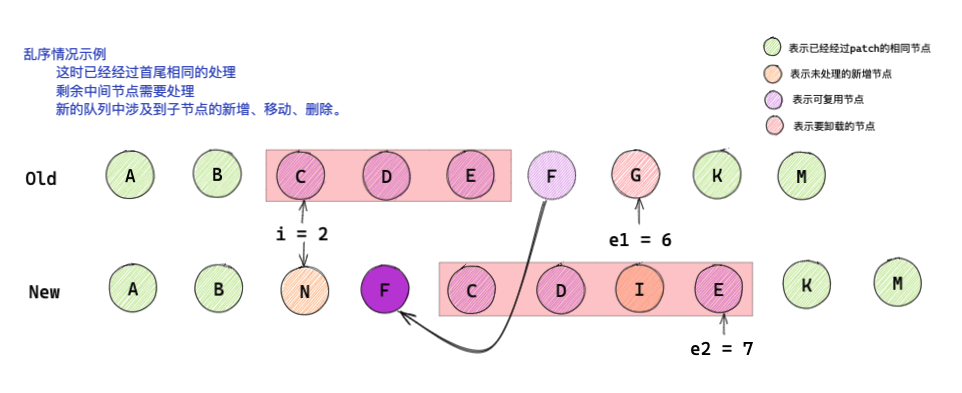
已上圖為例,在未處理的亂序節點中,存在新增節點N、I、需要卸載的節點G,及可復用節點C、D、E、F,
節點CDE在新舊子序列中相對位置沒有變換,如果想要通過最小變動實作節點復用,我們可以將找出F節點變化前后的下標位置,在新的子序列C節點之前插入F節點即可,
最大遞增子序列的作用就是通過新舊節點變化前后的映射,創建一個遞增陣列,這樣就可以知道哪些節點在變化前后相對位置沒有發生變化,哪些節點需要進行移動,
Vue3中的遞增子序列的不同在于,它保存的是可復用節點在 newIndexToOldIndexMap的下標,而并不是newIndexToOldIndexMap中的元素,
接下來我們看下代碼部分:
// 5.3 move and mount
// generate longest stable subsequence only when nodes have moved
// 移動節點 掛載節點
// 僅當節點被移動后 生成最長遞增子序列
// 經過上面操作后,newIndexToOldIndexMap = [5, 4, 3, 0]
// 得到 increasingNewIndexSequence = [2]
const increasingNewIndexSequence = moved
? getSequence(newIndexToOldIndexMap)
: EMPTY_ARR
// j = 0
j = increasingNewIndexSequence.length - 1
// looping backwards so that we can use last patched node as anchor
// 從后向前遍歷 以便于可以用最新的被patch的節點作為錨點
// i = 3
for (i = toBePatched - 1; i >= 0; i--) {
// 5 4 3 2
const nextIndex = s2 + i
// 節點 h c d e
const nextChild = c2[nextIndex]
// 獲取錨點
const anchor =
nextIndex + 1 < l2 ? c2[nextIndex + 1].el : parentAnchor
// [5, 4, 3, 0] 節點h會被patch,其實是mount
// c d e 會被移動
if (newIndexToOldIndexMap[i] === 0) {
// mount new
// 掛載新的
patch(
null,
nextChild,
container,
anchor,
...
)
} else if (moved) {
// move if:
// There is no stable subsequence (e.g. a reverse)
// OR current node is not among the stable sequence
// 如果沒有最長遞增子序列或者 當前節點不在遞增子序列中間
// 則移動節點
//
if (j < 0 || i !== increasingNewIndexSequence[j]) {
move(nextChild, container, anchor, MoveType.REORDER)
} else {
j--
}
}
}
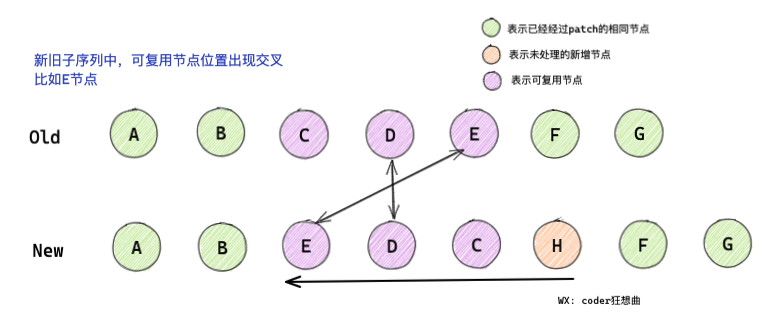
從上面的代碼可以知道:
- 通過
newIndexToOldIndexMap獲取的最大遞增子序列是[2] j = 0- 遍歷的時候從右向左遍歷,這樣可以獲取到錨點,如果有已經經過
patch的兄弟節點,則以兄弟節點作為錨點,否則以父節點作為錨點 newIndexToOldIndexMap[i] === 0,說明是新增節點,需要對節點進行mount,這時只需給patch的第一個引數傳null即可,可以知道首先會對h節點進行patch,- 否則會判斷
moved是否為true,通過前面的分析,我們知道節點C & 節點E在前后變化中發生了位置移動, - 故這里會移動節點,我們知道
j此時為0,i此時為2,i !== increasingNewIndexSequence[j]為true,并不會移動C節點,而是執行j--, - 后面因為
j < 0,會對D、E節點進行移動,
至此我們就完成了Vue3 diff演算法的學習分析,
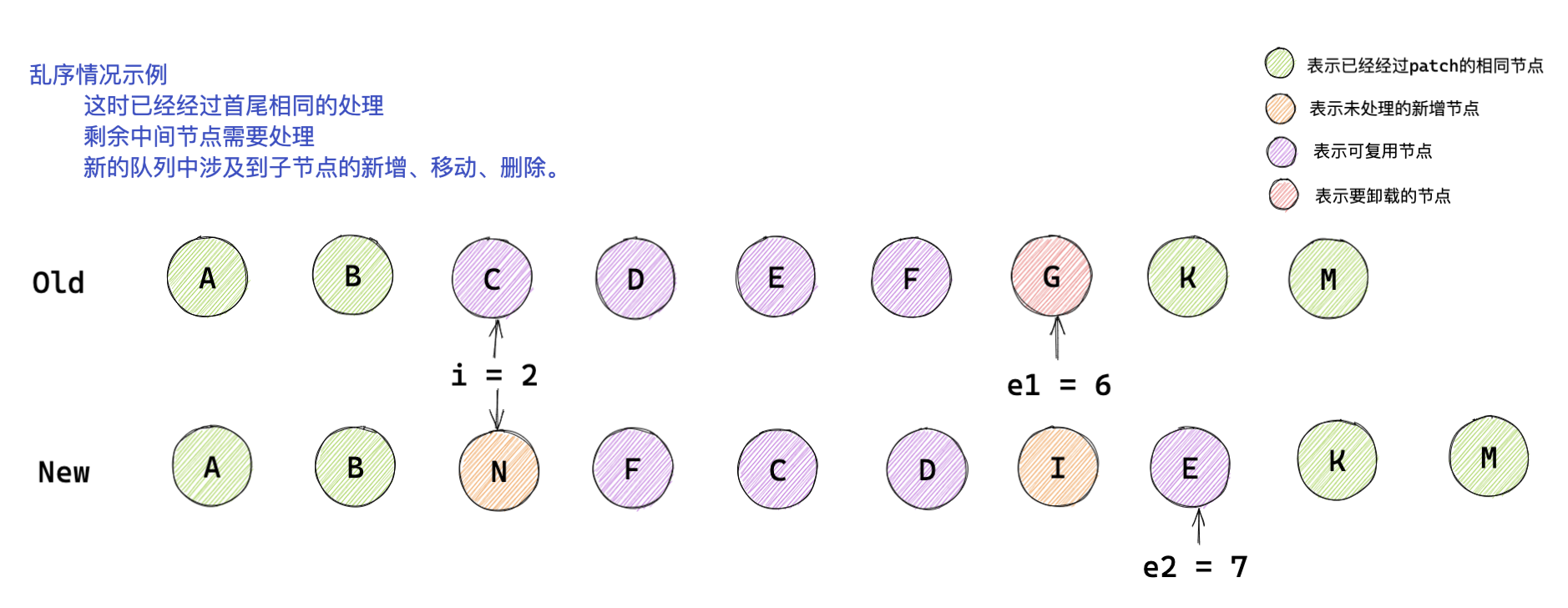
這里為大家提供了一個示例,可以結合本文的分析程序進行練習:
可以只看第一張圖進行分析,分析結束后可以與第二三張圖片進行對比,
圖一:
!
圖二 & 三:
總結
通過上面的學習分析,可以知道,Vue3 的diff演算法,會首先進行收尾相同節點的patch處理,結束后,會掛載新增節點,卸載舊節點,
如果子序列的情況較為復雜,比如出現亂序的情況,則會首先找出可復用的節點,并通過可復用節點的位置映射構建一個最大遞增子序列,通過最大遞增子序列來對節點進行mount & move,以提高diff效率,實作節點復用的最大可能性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/455529.html
標籤:其他
上一篇:Node.js基礎入門第六天
下一篇:Node.js基礎入門第六天