下面是我的資料表,來自我的代碼輸出:
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 8 | 12 | 1.34 |
| 1 | 7 | 0.25 |
我要重復資料洗掉,只剩下
| columnA|ColumnB|ColumnC|
| ------ | ----- | ------|
| 12 | 8 | 1.34 |
| 1 | 7 | 0.25 |
通常當我嘗試洗掉重復項時,我使用的是.drop_duplicates(subset=). 但這一次,我想放棄同一對,例如:我想放棄 (columnA,columnB)==(columnB,columnA)。我做了一些研究,我發現有人set((a,b) if a<=b else (b,a) for a,b in pairs)用來洗掉相同的串列對。但我不知道如何在我的 pandas 資料框中使用此方法。請幫助,并提前感謝您!
uj5u.com熱心網友回復:
您可以將aand組合b成一個元組并drop_duplicates根據組合列進行呼叫:
t = df[["a", "b"]].apply(lambda row: tuple(set(row)), axis=1)
df.assign(t=t).drop_duplicates("t").drop(columns="t")
uj5u.com熱心網友回復:
將相關列轉換為frozenset:
out = df[~df[['columnA', 'ColumnB']].apply(frozenset, axis=1).duplicated()]
print(out)
# Output
columnA ColumnB ColumnC
0 12 8 1.34
2 1 7 0.25
細節:
>>> set([8, 12])
{8, 12}
>>> set([12, 8])
{8, 12}
uj5u.com熱心網友回復:
可能的解決方案如下:
# pip install pandas
import pandas as pd
# create test dataframe
df = pd.DataFrame({"colA": [12,8,1],"colB": [8,12,1],"colC": [1.34,1.34,0.25]})
df
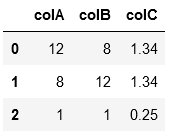
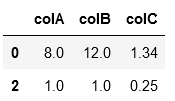
df.loc[df.colA > df.colB, df.columns] = df.loc[df.colA > df.colB, df.columns[[1,0,2]]].values
df.drop_duplicates()
退貨
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/456059.html