因此,我正在遍歷包含數字的 Excel 列,并嘗試使用 .apply(pd.to_numeric).round() 對所有數字進行四舍五入
這一直對我有用,但最近,一些 Excel 檔案包含數字與分數混合的列(例如 27 3/8、50 17/32)。當我的腳本運行時,我得到“無法在位置 0 決議字串“50 17/32””
假設這是我的系列:
0 250.25
1 32.75
2 64
3 50 17/32
4 16 3/8
Name: Qty, dtype: object
期望的結果:
0 250
1 33
2 64
3 51
4 16
Name: Qty, dtype: object
我正在嘗試根據空白拆分列,并以某種方式嘗試將 2 列添加在一起,但我遇到了各種各樣的問題。下面的代碼有點作業,但我原來的“數量”列回傳的是一堆 NaN,而不是沒有分隔符的行的原始數字
df['Qty'] = df['Qty'].fillna(value=np.nan)
df[['Qty','Fraction']] = df['Qty'].str.split(' ', expand=True)
這是我原來的 ['Qty'] 列:

這是在其上運行拆分代碼后的相同行:
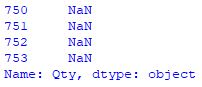
有趣的是,它確實使用整數分數混合正確拆分了行,但是由于我不明白的原因將某些行轉換為 NaN 讓我失望。我嘗試過的另一件事是使用 lambda 函式,但據我所知,當它只是一個像 3/8 這樣的傳統分數時,它們的效果最好,前面沒有整數。研究了幾個小時,我快要放棄了,所以如果有人知道如何解決這個問題,我很想知道
謝謝
uj5u.com熱心網友回復:
這是使用的一種方法fractions.Fraction:
from fractions import Fraction
df2 = df['Qty'].str.extract(r'(\d (?:\.\d )?)?\s*(\d /\d )?')
out = (pd.to_numeric(df2[0], errors='coerce')
df2[1].fillna(0).apply(lambda x: float(Fraction(x)))
)
df['float'] = out
df['int'] = out.round().astype(int)
輸出:
Qty float int
0 250.25 250.25000 250
1 32.75 32.75000 33
2 64 64.00000 64
3 50 17/32 50.53125 51
4 16 3/8 16.37500 16
使用算術的替代方法:
df2 = df['Qty'].str.extract(r'(\d (?:\.\d )?)?\s*(?:(\d )/(\d ))?').astype(float)
df['int'] = (df2[0] df2[1].fillna(0)/df2[2].fillna(1)).round().astype(int)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/461240.html
上一篇:基于部分行的最小-最大歸一化