我有按年份和副產品劃分的銷售資料,可以這樣說:
Year <- c(2010,2010,2010,2010,2010,2011,2011,2011,2011,2011,2012,2012,2012,2012,2012)
Model <- c("a","b","c","d","e","a","b","c","d","e","a","b","c","d","e")
Sale <- c("30","45","23","33","24","11","56","19","45","56","33","32","89","33","12")
df <- data.frame(Year, Model, Sale)
首先,我需要計算“份額”列,它代表每年每種產品的份額。
在我這樣計算累積份額之后:
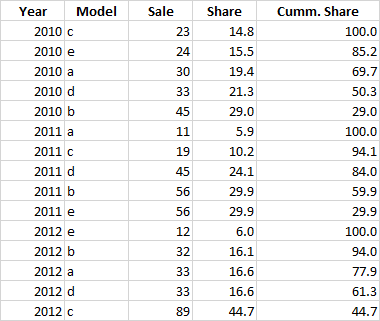
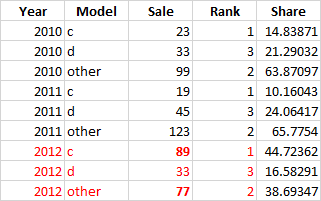
第三步需要識別出去年(本例中為2012年)累計銷售額達到70%的產品,并在整個資料框中只保留這些產品 添加一個排名列(基于去年)并匯總所有其余產品為“其他”類別。所以最終的資料框應該是這樣的:
uj5u.com熱心網友回復:
這是一項相當復雜的資料整理任務,但可以使用以下方法實作dplyr:
library(dplyr)
df %>%
mutate(Sale = as.numeric(Sale)) %>%
group_by(Year) %>%
mutate(Share = 100 * Sale/ sum(Sale),
Year_order = order(order(-Share))) %>%
arrange(Year, Year_order, by_group = TRUE) %>%
mutate(Cumm.Share = cumsum(Share)) %>%
ungroup() %>%
mutate(below_70 = Model %in% Model[Year == max(Year) & Cumm.Share < 70]) %>%
mutate(Model = ifelse(below_70, Model, 'Other')) %>%
group_by(Year, Model) %>%
summarize(Sale = sum(Sale), Share = sum(Share), .groups = 'keep') %>%
group_by(Year) %>%
mutate(pseudoShare = ifelse(Model == 'Other', 0, Share)) %>%
arrange(Year, -pseudoShare, by_group = TRUE) %>%
ungroup() %>%
mutate(Rank = match(Model, Model[Year == max(Year)])) %>%
select(-pseudoShare)
#> # A tibble: 9 x 5
#> Year Model Sale Share Rank
#> <dbl> <chr> <dbl> <dbl> <int>
#> 1 2010 a 30 19.4 2
#> 2 2010 c 23 14.8 1
#> 3 2010 Other 102 65.8 3
#> 4 2011 c 19 10.2 1
#> 5 2011 a 11 5.88 2
#> 6 2011 Other 157 84.0 3
#> 7 2012 c 89 44.7 1
#> 8 2012 a 33 16.6 2
#> 9 2012 Other 77 38.7 3
請注意,在輸出中,此代碼保留了組a和c,而不是c和d,就像您預期的輸出一樣。這是因為a和d在最后一年(16.6)具有相同的值,因此可以選擇其中任何一個。
由reprex 包于 2022-04-21 創建(v2.0.1)
uj5u.com熱心網友回復:
Year <- c(2010,2010,2010,2010,2010,2011,2011,2011,2011,2011,2012,2012,2012,2012,2012)
Model <- c("a","b","c","d","e","a","b","c","d","e","a","b","c","d","e")
Sale <- c("30","45","23","33","24","11","56","19","45","56","33","32","89","33","12")
df <- data.frame(Year, Model, Sale, stringsAsFactors=F)
years <- unique(df$Year)
shares <- c()
cumshares <- c()
for (year in years){
extract <- df[df$Year == year, ]
sale <- as.numeric(extract$Sale)
share <- 100*sale/sum(sale)
shares <- append(shares, share)
cumshare <- rev(cumsum(rev(share)))
cumshares <- append(cumshares, cumshare)
}
df$Share <- shares
df$Cumm.Share <- cumshares
df
給
> df
Year Model Sale Share Cumm.Share
1 2010 a 30 19.354839 100.000000
2 2010 b 45 29.032258 80.645161
3 2010 c 23 14.838710 51.612903
4 2010 d 33 21.290323 36.774194
5 2010 e 24 15.483871 15.483871
6 2011 a 11 5.882353 100.000000
7 2011 b 56 29.946524 94.117647
8 2011 c 19 10.160428 64.171123
9 2011 d 45 24.064171 54.010695
10 2011 e 56 29.946524 29.946524
11 2012 a 33 16.582915 100.000000
12 2012 b 32 16.080402 83.417085
13 2012 c 89 44.723618 67.336683
14 2012 d 33 16.582915 22.613065
15 2012 e 12 6.030151 6.030151
我不明白您所說的第 3 步是什么意思,您如何決定保留哪些產品?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/461334.html