這里給大家分享我在網上總結出來的一些知識,希望對大家有所幫助
1. new運算子的實作原理
new運算子的執行程序:
(1)首先創建了一個新的空物件
(2)設定原型,將物件的原型設定為函式的 prototype 物件,
(3)讓函式的 this 指向這個物件,執行建構式的代碼(為這個新物件添加屬性)
(4)判斷函式的回傳值型別,如果是值型別,回傳創建的物件,如果是參考型別,就回傳這個參考型別的物件,
具體實作:
function objectFactory() {
let newObject = null;
let constructor = Array.prototype.shift.call(arguments);
let result = null;
// 判斷引數是否是一個函式
if (typeof constructor !== "function") {
console.error("type error");
return;
}
// 新建一個空物件,物件的原型為建構式的 prototype 物件
newObject = Object.create(constructor.prototype);
// 將 this 指向新建物件,并執行函式
result = constructor.apply(newObject, arguments);
// 判斷回傳物件
let flag = result && (typeof result === "object" || typeof result === "function");
// 判斷回傳結果
return flag ? result : newObject;
}
// 使用方法
objectFactory(建構式, 初始化引數);
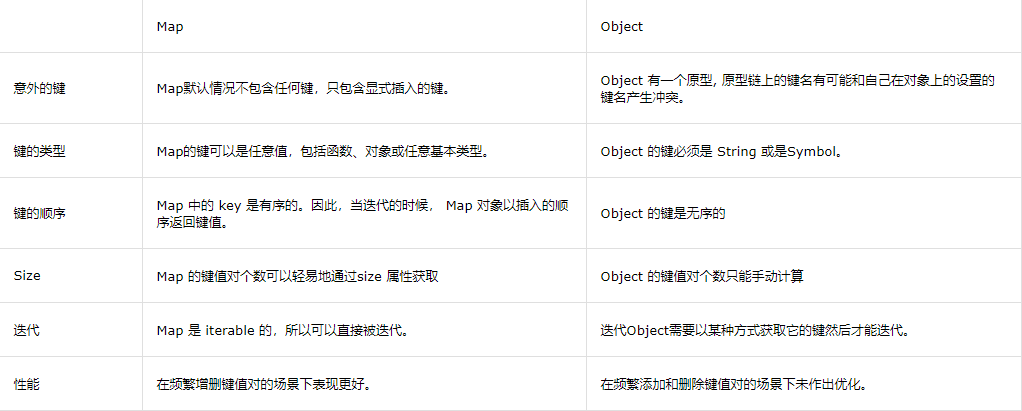
2. map和Object的區別
3.Map3. map和weakMap的區別
map本質上就是鍵值對的集合,但是普通的Object中的鍵值對中的鍵只能是字串,而ES6提供的Map資料結構類似于物件,但是它的鍵不限制范圍,可以是任意型別,是一種更加完善的Hash結構,如果Map的鍵是一個原始資料型別,只要兩個鍵嚴格相同,就視為是同一個鍵,
實際上Map是一個陣列,它的每一個資料也都是一個陣列,其形式如下:
const map = [
["name","張三"],
["age",18],
]
Map資料結構有以下操作方法:
- size:
map.size回傳Map結構的成員總數, - set(key,value):設定鍵名key對應的鍵值value,然后回傳整個Map結構,如果key已經有值,則鍵值會被更新,否則就新生成該鍵,(因為回傳的是當前Map物件,所以可以鏈式呼叫)
- get(key):該方法讀取key對應的鍵值,如果找不到key,回傳undefined,
- has(key):該方法回傳一個布林值,表示某個鍵是否在當前Map物件中,
- delete(key):該方法洗掉某個鍵,回傳true,如果洗掉失敗,回傳false,
- clear():map.clear()清除所有成員,沒有回傳值,
Map結構原生提供是三個遍歷器生成函式和一個遍歷方法
- keys():回傳鍵名的遍歷器,
- values():回傳鍵值的遍歷器,
- entries():回傳所有成員的遍歷器,
- forEach():遍歷Map的所有成員,
const map = new Map([
["foo",1],
["bar",2],
])
for(let key of map.keys()){
console.log(key); // foo bar
}
for(let value of map.values()){
console.log(value); // 1 2
}
for(let items of map.entries()){
console.log(items); // ["foo",1] ["bar",2]
}
map.forEach( (value,key,map) => {
console.log(key,value); // foo 1 bar 2
})
(2)WeakMap
WeakMap 物件也是一組鍵值對的集合,其中的鍵是弱參考的,其鍵必須是物件,原始資料型別不能作為key值,而值可以是任意的,
該物件也有以下幾種方法:
- set(key,value):設定鍵名key對應的鍵值value,然后回傳整個Map結構,如果key已經有值,則鍵值會被更新,否則就新生成該鍵,(因為回傳的是當前Map物件,所以可以鏈式呼叫)
- get(key):該方法讀取key對應的鍵值,如果找不到key,回傳undefined,
- has(key):該方法回傳一個布林值,表示某個鍵是否在當前Map物件中,
- delete(key):該方法洗掉某個鍵,回傳true,如果洗掉失敗,回傳false,
其clear()方法已經被棄用,所以可以通過創建一個空的WeakMap并替換原物件來實作清除,
WeakMap的設計目的在于,有時想在某個物件上面存放一些資料,但是這會形成對于這個物件的參考,一旦不再需要這兩個物件,就必須手動洗掉這個參考,否則垃圾回識訓制就不會釋放物件占用的記憶體,
而WeakMap的鍵名所參考的物件都是弱參考,即垃圾回識訓制不將該參考考慮在內,因此,只要所參考的物件的其他參考都被清除,垃圾回識訓制就會釋放該物件所占用的記憶體,也就是說,一旦不再需要,WeakMap 里面的鍵名物件和所對應的鍵值對會自動消失,不用手動洗掉參考,
總結:
- Map 資料結構,它類似于物件,也是鍵值對的集合,但是“鍵”的范圍不限于字串,各種型別的值(包括物件)都可以當作鍵,
- WeakMap 結構與 Map 結構類似,也是用于生成鍵值對的集合,但是 WeakMap 只接受物件作為鍵名( null 除外),不接受其他型別的值作為鍵名,而且 WeakMap 的鍵名所指向的物件,不計入垃圾回識訓制,
4. JavaScript有哪些內置物件
全域的物件( global objects )或稱標準內置物件,不要和 "全域物件(global object)" 混淆,這里說的全域的物件是說在
全域作用域里的物件,全域作用域中的其他物件可以由用戶的腳本創建或由宿主程式提供,
標準內置物件的分類:
(1)值屬性,這些全域屬性回傳一個簡單值,這些值沒有自己的屬性和方法,
例如 Infinity、NaN、undefined、null 字面量
(2)函式屬性,全域函式可以直接呼叫,不需要在呼叫時指定所屬物件,執行結束后會將結果直接回傳給呼叫者,
例如 eval()、parseFloat()、parseInt() 等
(3)基本物件,基本物件是定義或使用其他物件的基礎,基本物件包括一般物件、函式物件和錯誤物件,
例如 Object、Function、Boolean、Symbol、Error 等
(4)數字和日期物件,用來表示數字、日期和執行數學計算的物件,
例如 Number、Math、Date
(5)字串,用來表示和操作字串的物件,
例如 String、RegExp
(6)可索引的集合物件,這些物件表示按照索引值來排序的資料集合,包括陣列和型別陣列,以及類陣列結構的物件,例如 Array
(7)使用鍵的集合物件,這些集合物件在存盤資料時會使用到鍵,支持按照插入順序來迭代元素,
例如 Map、Set、WeakMap、WeakSet
(8)矢量集合,SIMD 矢量集合中的資料會被組織為一個資料序列,
例如 SIMD 等
(9)結構化資料,這些物件用來表示和操作結構化的緩沖區資料,或使用 JSON 編碼的資料,
例如 JSON 等
(10)控制抽象物件
例如 Promise、Generator 等
(11)反射
例如 Reflect、Proxy
(12)國際化,為了支持多語言處理而加入 ECMAScript 的物件,
例如 Intl、Intl.Collator 等
(13)WebAssembly
(14)其他
例如 arguments
總結:
js 中的內置物件主要指的是在程式執行前存在全域作用域里的由 js 定義的一些全域值屬性、函式和用來實體化其他物件的建構式物件,一般經常用到的如全域變數值 NaN、undefined,全域函式如 parseInt()、parseFloat() 用來實體化物件的建構式如 Date、Object 等,還有提供數學計算的單體內置物件如 Math 物件,
5. 常用的正則運算式有哪些?
// (1)匹配 16 進制顏色值
var regex = /#([0-9a-fA-F]{6}|[0-9a-fA-F]{3})/g;
// (2)匹配日期,如 yyyy-mm-dd 格式
var regex = /^[0-9]{4}-(0[1-9]|1[0-2])-(0[1-9]|[12][0-9]|3[01])$/;
// (3)匹配 qq 號
var regex = /^[1-9][0-9]{4,10}$/g;
// (4)手機號碼正則
var regex = /^1[34578]\d{9}$/g;
// (5)用戶名正則
var regex = /^[a-zA-Z\$][a-zA-Z0-9_\$]{4,16}$/;
6. 對JSON的理解
JSON 是一種基于文本的輕量級的資料交換格式,它可以被任何的編程語言讀取和作為資料格式來傳遞,
在專案開發中,使用 JSON 作為前后端資料交換的方式,在前端通過將一個符合 JSON 格式的資料結構序列化為
JSON 字串,然后將它傳遞到后端,后端通過 JSON 格式的字串決議后生成對應的資料結構,以此來實作前后端資料的一個傳遞,
因為 JSON 的語法是基于 js 的,因此很容易將 JSON 和 js 中的物件弄混,但是應該注意的是 JSON 和 js 中的物件不是一回事,JSON 中物件格式更加嚴格,比如說在 JSON 中屬性值不能為函式,不能出現 NaN 這樣的屬性值等,因此大多數的 js 物件是不符合 JSON 物件的格式的,
在 js 中提供了兩個函式來實作 js 資料結構和 JSON 格式的轉換處理,
- JSON.stringify 函式,通過傳入一個符合 JSON 格式的資料結構,將其轉換為一個 JSON 字串,如果傳入的資料結構不符合 JSON 格式,那么在序列化的時候會對這些值進行對應的特殊處理,使其符合規范,在前端向后端發送資料時,可以呼叫這個函式將資料物件轉化為 JSON 格式的字串,
- JSON.parse() 函式,這個函式用來將 JSON 格式的字串轉換為一個 js 資料結構,如果傳入的字串不是標準的 JSON 格式的字串的話,將會拋出錯誤,當從后端接收到 JSON 格式的字串時,可以通過這個方法來將其決議為一個 js 資料結構,以此來進行資料的訪問,
7. JavaScript腳本延遲加載的方式有哪些?
延遲加載就是等頁面加載完成之后再加載 JavaScript 檔案, js 延遲加載有助于提高頁面加載速度,
一般有以下幾種方式:
- defer 屬性:給 js 腳本添加 defer 屬性,這個屬性會讓腳本的加載與檔案的決議同步決議,然后在檔案決議完成后再執行這個腳本檔案,這樣的話就能使頁面的渲染不被阻塞,多個設定了 defer 屬性的腳本按規范來說最后是順序執行的,但是在一些瀏覽器中可能不是這樣,
- async 屬性:給 js 腳本添加 async 屬性,這個屬性會使腳本異步加載,不會阻塞頁面的決議程序,但是當腳本加載完成后立即執行 js 腳本,這個時候如果檔案沒有決議完成的話同樣會阻塞,多個 async 屬性的腳本的執行順序是不可預測的,一般不會按照代碼的順序依次執行,
- 動態創建 DOM 方式:動態創建 DOM 標簽的方式,可以對檔案的加載事件進行監聽,當檔案加載完成后再動態的創建 script 標簽來引入 js 腳本,
- 使用 setTimeout 延遲方法:設定一個定時器來延遲加載js腳本檔案
- 讓 JS 最后加載:將 js 腳本放在檔案的底部,來使 js 腳本盡可能的在最后來加載執行,
8. JavaScript 類陣列物件的定義?
一個擁有 length 屬性和若干索引屬性的物件就可以被稱為類陣列物件,類陣列物件和陣列類似,但是不能呼叫陣列的方法,常見的類陣列物件有 arguments 和 DOM 方法的回傳結果,還有一個函式也可以被看作是類陣列物件,因為它含有 length 屬性值,代表可接收的引數個數,
常見的類陣列轉換為陣列的方法有這樣幾種:
(1)通過 call 呼叫陣列的 slice 方法來實作轉換
Array.prototype.slice.call(arrayLike);
(2)通過 call 呼叫陣列的 splice 方法來實作轉換
Array.prototype.splice.call(arrayLike, 0);
(3)通過 apply 呼叫陣列的 concat 方法來實作轉換
Array.prototype.concat.apply([], arrayLike);
(4)通過 Array.from 方法來實作轉換
Array.from(arrayLike)
9. 陣列有哪些原生方法?
- 陣列和字串的轉換方法:toString()、toLocalString()、join() 其中 join() 方法可以指定轉換為字串時的分隔符,
- 陣列尾部操作的方法 pop() 和 push(),push 方法可以傳入多個引數,
- 陣列首部操作的方法 shift() 和 unshift() 重排序的方法 reverse() 和 sort(),sort() 方法可以傳入一個函式來進行比較,傳入前后兩個值,如果回傳值為正數,則交換兩個引數的位置,
- 陣列連接的方法 concat() ,回傳的是拼接好的陣列,不影響原陣列,
- 陣列截取辦法 slice(),用于截取陣列中的一部分回傳,不影響原陣列,
- 陣列插入方法 splice(),影響原陣列查找特定項的索引的方法,indexOf() 和 lastIndexOf() 迭代方法 every()、some()、filter()、map() 和 forEach() 方法
- 陣列歸并方法 reduce() 和 reduceRight() 方法
10. Unicode、UTF-8、UTF-16、UTF-32的區別?
(1)Unicode
在說Unicode之前需要先了解一下ASCII碼:ASCII 碼(American Standard Code for Information Interchange)稱為美國標準資訊交換碼,
- 它是基于拉丁字母的一套電腦編碼系統,
- 它定義了一個用于代表常見字符的字典,
- 它包含了"A-Z"(包含大小寫),資料"0-9" 以及一些常見的符號,
- 它是專門為英語而設計的,有128個編碼,對其他語言無能為力
ASCII碼可以表示的編碼有限,要想表示其他語言的編碼,還是要使用Unicode來表示,可以說Unicode是ASCII 的超集,
Unicode全稱 Unicode Translation Format,又叫做統一碼、萬國碼、單一碼,Unicode 是為了解決傳統的字符編碼方案的局限而產生的,它為每種語言中的每個字符設定了統一并且唯一的二進制編碼,以滿足跨語言、跨平臺進行文本轉換、處理的要求,
Unicode的實作方式(也就是編碼方式)有很多種,常見的是UTF-8、UTF-16、UTF-32和USC-2,
(2)UTF-8
UTF-8是使用最廣泛的Unicode編碼方式,它是一種可變長的編碼方式,可以是1—4個位元組不等,它可以完全兼容ASCII碼的128個字符,
注意: UTF-8 是一種編碼方式,Unicode是一個字符集合,
UTF-8的編碼規則:
- 對于單位元組的符號,位元組的第一位為0,后面的7位為這個字符的
Unicode編碼,因此對于英文字母,它的Unicode編碼和ACSII編碼一樣, - 對于n位元組的符號,第一個位元組的前n位都是1,第n+1位設為0,后面位元組的前兩位一律設為10,剩下的沒有提及的二進制位,全部為這個符號的
Unicode碼 ,
來看一下具體的Unicode編號范圍與對應的UTF-8二進制格式 :

找到該Unicode編碼的所在的編號范圍,進而找到與之對應的二進制格式那該如何通過具體的Unicode編碼,進行具體的UTF-8編碼呢?步驟如下:
- 將
Unicode編碼轉換為二進制數(去掉最高位的0) - 將二進制數從右往左一次填入二進制格式的
X中,如果有X未填,就設為0
來看一個實際的例子:
“馬” 字的Unicode編碼是:0x9A6C,整數編號是39532
(1)首選確定了該字符在第三個范圍內,它的格式是 1110xxxx 10xxxxxx 10xxxxxx
(2)39532對應的二進制數為1001 1010 0110 1100
(3)將二進制數填入X中,結果是:11101001 10101001 10101100
(3)UTF-16
1. 平面的概念
在了解UTF-16之前,先看一下平面的概念:
Unicode編碼中有很多很多的字符,它并不是一次性定義的,而是磁區進行定義的,每個區存放65536(216)個字符,這稱為一個平面,目前總共有17 個平面,
最前面的一個平面稱為基本平面,它的碼點從0 — 216-1,寫成16進制就是U+0000 — U+FFFF,那剩下的16個平面就是輔助平面,碼點范圍是 U+10000—U+10FFFF,
2. UTF-16 概念:
UTF-16也是Unicode編碼集的一種編碼形式,把Unicode字符集的抽象碼位映射為16位長的整數(即碼元)的序列,用于資料存盤或傳遞,Unicode字符的碼位需要1個或者2個16位長的碼元來表示,因此UTF-16也是用變長位元組表示的,
3. UTF-16 編碼規則:
- 編號在
U+0000—U+FFFF的字符(常用字符集),直接用兩個位元組表示, - 編號在
U+10000—U+10FFFF之間的字符,需要用四個位元組表示,
4. 編碼識別
那么問題來了,當遇到兩個位元組時,怎么知道是把它當做一個字符還是和后面的兩個位元組一起當做一個字符呢?
UTF-16 編碼肯定也考慮到了這個問題,在基本平面內,從 U+D800 — U+DFFF 是一個空段,也就是說這個區間的碼點不對應任何的字符,因此這些空段就可以用來映射輔助平面的字符,
輔助平面共有 220 個字符位,因此表示這些字符至少需要 20 個二進制位,UTF-16 將這 20 個二進制位分成兩半,前 10 位映射在 U+D800 — U+DBFF,稱為高位(H),后 10 位映射在 U+DC00 — U+DFFF,稱為低位(L),這就相當于,將一個輔助平面的字符拆成了兩個基本平面的字符來表示,
因此,當遇到兩個位元組時,發現它的碼點在 U+D800 —U+DBFF之間,就可以知道,它后面的兩個位元組的碼點應該在 U+DC00 — U+DFFF 之間,這四個位元組必須放在一起進行解讀,
5. 舉例說明
以 "??" 字為例,它的 Unicode 碼點為 0x21800,該碼點超出了基本平面的范圍,因此需要用四個位元組來表示,步驟如下:
- 首先計算超出部分的結果:
0x21800 - 0x10000 - 將上面的計算結果轉為20位的二進制數,不足20位就在前面補0,結果為:
0001000110 0000000000 - 將得到的兩個10位二進制數分別對應到兩個區間中
U+D800對應的二進制數為1101100000000000, 將0001000110填充在它的后10 個二進制位,得到1101100001000110,轉成 16 進制數為0xD846,同理,低位為0xDC00,所以這個字的UTF-16編碼為0xD846 0xDC00
(4) UTF-32
UTF-32 就是字符所對應編號的整數二進制形式,每個字符占四個位元組,這個是直接進行轉換的,該編碼方式占用的儲存空間較多,所以使用較少,
比如“馬” 字的Unicode編號是:U+9A6C,整數編號是39532,直接轉化為二進制:1001 1010 0110 1100,這就是它的UTF-32編碼,
(5)總結
Unicode、UTF-8、UTF-16、UTF-32有什么區別?
Unicode是編碼字符集(字符集),而UTF-8、UTF-16、UTF-32是字符集編碼(編碼規則);UTF-16使用變長碼元序列的編碼方式,相較于定長碼元序列的UTF-32演算法更復雜,甚至比同樣是變長碼元序列的UTF-8也更為復雜,因為其引入了獨特的代理對這樣的代理機制;UTF-8需要判斷每個位元組中的開頭標志資訊,所以如果某個位元組在傳送程序中出錯了,就會導致后面的位元組也會決議出錯;而UTF-16不會判斷開頭標志,即使錯也只會錯一個字符,所以容錯能力教強;- 如果字符內容全部英文或英文與其他文字混合,但英文占絕大部分,那么用
UTF-8就比UTF-16節省了很多空間;而如果字符內容全部是中文這樣類似的字符或者混合字符中中文占絕大多數,那么UTF-16就占優勢了,可以節省很多空間;
11. 常見的位運算子有哪些?其計算規則是什么?
現代計算機中資料都是以二進制的形式存盤的,即0、1兩種狀態,計算機對二進制資料進行的運算加減乘除等都是叫位運算,即將符號位共同參與運算的運算,
常見的位運算有以下幾種:
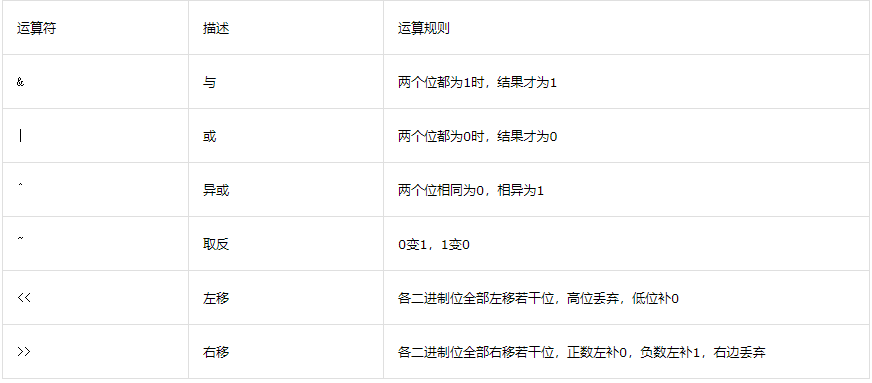
1. 按位與運算子(&)
定義: 參加運算的兩個資料按二進制位進行“與”運算,
運算規則:
0 & 0 = 0 0 & 1 = 0 1 & 0 = 0 1 & 1 = 1
總結:兩位同時為1,結果才為1,否則結果為0,
例如:3&5 即:
0000 0011 0000 0101 = 0000 0001
因此 3&5 的值為1,
注意:負數按補碼形式參加按位與運算,
用途:
(1)判斷奇偶
只要根據最未位是0還是1來決定,為0就是偶數,為1就是奇數,因此可以用if ((i & 1) == 0)代替if (i % 2 == 0)來判斷a是不是偶數,
(2)清零
如果想將一個單元清零,即使其全部二進制位為0,只要與一個各位都為零的數值相與,結果為零,
2. 按位或運算子(|)
定義: 參加運算的兩個物件按二進制位進行“或”運算,
運算規則:
0 | 0 = 0 0 | 1 = 1 1 | 0 = 1 1 | 1 = 1
總結:參加運算的兩個物件只要有一個為1,其值為1,
例如:3|5即:
0000 0011 0000 0101 = 0000 0111
因此,3|5的值為7,
注意:負數按補碼形式參加按位或運算,
3. 異或運算子(^)
定義: 參加運算的兩個資料按二進制位進行“異或”運算,
運算規則:
0 ^ 0 = 0 0 ^ 1 = 1 1 ^ 0 = 1 1 ^ 1 = 0
總結:參加運算的兩個物件,如果兩個相應位相同為0,相異為1,
例如:3|5即:
0000 0011 0000 0101 = 0000 0110
因此,3^5的值為6,
異或運算的性質:
- 交換律:
(a^b)^c == a^(b^c) - 結合律:
(a + b)^c == a^b + b^c - 對于任何數x,都有
x^x=0,x^0=x - 自反性:
a^b^b=a^0=a;
4. 取反運算子 (~)
定義: 參加運算的一個資料按二進制進行“取反”運算,
運算規則:
~ 1 = 0 ~ 0 = 1
總結:對一個二進制數按位取反,即將0變1,1變0,
例如:~6 即:
0000 0110 = 1111 1001
在計算機中,正數用原碼表示,負數使用補碼存盤,首先看最高位,最高位1表示負數,0表示正數,此計算機二進制碼為負數,最高位為符號位,
當發現按位取反為負數時,就直接取其補碼,變為十進制:
0000 0110 = 1111 1001 反碼:1000 0110 補碼:1000 0111
因此,~6的值為-7,
5. 左移運算子(<<)
定義: 將一個運算物件的各二進制位全部左移若干位,左邊的二進制位丟棄,右邊補0,
設 a=1010 1110,a = a<< 2 將a的二進制位左移2位、右補0,即得a=1011 1000,
若左移時舍棄的高位不包含1,則每左移一位,相當于該數乘以2,
6. 右移運算子(>>)
定義: 將一個數的各二進制位全部右移若干位,正數左補0,負數左補1,右邊丟棄,
例如:a=a>>2 將a的二進制位右移2位,左補0 或者 左補1得看被移數是正還是負,
運算元每右移一位,相當于該數除以2,
7. 原碼、補碼、反碼
上面提到了補碼、反碼等知識,這里就補充一下,
計算機中的有符號數有三種表示方法,即原碼、反碼和補碼,三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”,而數值位,三種表示方法各不相同,
(1)原碼
原碼就是一個數的二進制數,
例如:10的原碼為0000 1010
(2)反碼
- 正數的反碼與原碼相同,如:10 反碼為 0000 1010
- 負數的反碼為除符號位,按位取反,即0變1,1變0,
例如:-10
原碼:1000 1010 反碼:1111 0101
3)補碼
- 正數的補碼與原碼相同,如:10 補碼為 0000 1010
- 負數的補碼是原碼除符號位外的所有位取反即0變1,1變0,然后加1,也就是反碼加1,
例如:-10
原碼:1000 1010 反碼:1111 0101 補碼:1111 0110
12. 為什么函式的 arguments 引數是類陣列而不是陣列?如何遍歷類陣列?
arguments是一個物件,它的屬性是從 0 開始依次遞增的數字,還有callee和length等屬性,與陣列相似;但是它卻沒有陣列常見的方法屬性,如forEach, reduce等,所以叫它們類陣列,
要遍歷類陣列,有三個方法:
(1)將陣列的方法應用到類陣列上,這時候就可以使用call和apply方法,如:
function foo(){
Array.prototype.forEach.call(arguments, a => console.log(a))
}
(2)使用Array.from方法將類陣列轉化成陣列:?
function foo(){
const arrArgs = Array.from(arguments)
arrArgs.forEach(a => console.log(a))
}
(3)使用展開運算子將類陣列轉化成陣列
function foo(){
const arrArgs = [...arguments]
arrArgs.forEach(a => console.log(a))
}
13. 什么是 DOM 和 BOM?
- DOM 指的是檔案物件模型,它指的是把檔案當做一個物件,這個物件主要定義了處理網頁內容的方法和介面,
- BOM 指的是瀏覽器物件模型,它指的是把瀏覽器當做一個物件來對待,這個物件主要定義了與瀏覽器進行互動的法和介面,BOM的核心是 window,而 window 物件具有雙重角色,它既是通過 js 訪問瀏覽器視窗的一個介面,又是一個 Global(全域)物件,這意味著在網頁中定義的任何物件,變數和函式,都作為全域物件的一個屬性或者方法存在,window 物件含有 location 物件、navigator 物件、screen 物件等子物件,并且 DOM 的最根本的物件 document 物件也是 BOM 的 window 物件的子物件,
14. 對類陣列物件的理解,如何轉化為陣列
一個擁有 length 屬性和若干索引屬性的物件就可以被稱為類陣列物件,類陣列物件和陣列類似,但是不能呼叫陣列的方法,常見的類陣列物件有 arguments 和 DOM 方法的回傳結果,函式引數也可以被看作是類陣列物件,因為它含有 length屬性值,代表可接收的引數個數,
常見的類陣列轉換為陣列的方法有這樣幾種:
- 通過 call 呼叫陣列的 slice 方法來實作轉換
Array.prototype.slice.call(arrayLike);
- 通過 call 呼叫陣列的 splice 方法來實作轉換
Array.prototype.splice.call(arrayLike, 0);
- 通過 apply 呼叫陣列的 concat 方法來實作轉換
Array.prototype.concat.apply([], arrayLike);
- 通過 Array.from 方法來實作轉換
Array.from(arrayLike);
15. escape、encodeURI、encodeURIComponent 的區別
- encodeURI 是對整個 URI 進行轉義,將 URI 中的非法字符轉換為合法字符,所以對于一些在 URI 中有特殊意義的字符不會進行轉義,
- encodeURIComponent 是對 URI 的組成部分進行轉義,所以一些特殊字符也會得到轉義,
- escape 和 encodeURI 的作用相同,不過它們對于 unicode 編碼為 0xff 之外字符的時候會有區別,escape 是直接在字符的 unicode 編碼前加上 %u,而 encodeURI 首先會將字符轉換為 UTF-8 的格式,再在每個位元組前加上 %,
16. 對AJAX的理解,實作一個AJAX請求
AJAX是 Asynchronous JavaScript and XML 的縮寫,指的是通過 JavaScript 的 異步通信,從服務器獲取 XML 檔案從中提取資料,再更新當前網頁的對應部分,而不用重繪整個網頁,
創建AJAX請求的步驟:
- 創建一個 XMLHttpRequest 物件,
- 在這個物件上使用 open 方法創建一個 HTTP 請求,open 方法所需要的引數是請求的方法、請求的地址、是否異步和用戶的認證資訊,
- 在發起請求前,可以為這個物件添加一些資訊和監聽函式,比如說可以通過 setRequestHeader 方法來為請求添加頭資訊,還可以為這個物件添加一個狀態監聽函式,一個 XMLHttpRequest 物件一共有 5 個狀態,當它的狀態變化時會觸發onreadystatechange 事件,可以通過設定監聽函式,來處理請求成功后的結果,當物件的 readyState 變為 4 的時候,代表服務器回傳的資料接收完成,這個時候可以通過判斷請求的狀態,如果狀態是 2xx 或者 304 的話則代表回傳正常,這個時候就可以通過 response 中的資料來對頁面進行更新了,
- 當物件的屬性和監聽函式設定完成后,最后調用 sent 方法來向服務器發起請求,可以傳入引數作為發送的資料體,
const SERVER_URL = "/server";
let xhr = new XMLHttpRequest();
// 創建 Http 請求
xhr.open("GET", url, true);
// 設定狀態監聽函式
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 當請求成功時
if (this.status === 200) {
handle(this.response);
} else {
console.error(this.statusText);
}
};
// 設定請求失敗時的監聽函式
xhr.onerror = function() {
console.error(this.statusText);
};
// 設定請求頭資訊
xhr.responseType = "json";
xhr.setRequestHeader("Accept", "application/json");
// 發送 Http 請求
xhr.send(null);
使用Promise封裝AJAX:
// promise 封裝實作:
function getJSON(url) {
// 創建一個 promise 物件
let promise = new Promise(function(resolve, reject) {
let xhr = new XMLHttpRequest();
// 新建一個 http 請求
xhr.open("GET", url, true);
// 設定狀態的監聽函式
xhr.onreadystatechange = function() {
if (this.readyState !== 4) return;
// 當請求成功或失敗時,改變 promise 的狀態
if (this.status === 200) {
resolve(this.response);
} else {
reject(new Error(this.statusText));
}
};
// 設定錯誤監聽函式
xhr.onerror = function() {
reject(new Error(this.statusText));
};
// 設定回應的資料型別
xhr.responseType = "json";
// 設定請求頭資訊
xhr.setRequestHeader("Accept", "application/json");
// 發送 http 請求
xhr.send(null);
});
return promise;
}
17. JavaScript為什么要進行變數提升,它導致了什么問題?
變數提升的表現是,無論在函式中何處位置宣告的變數,好像都被提升到了函式的首部,可以在變數宣告前訪問到而不會報錯,
造成變數宣告提升的本質原因是 js 引擎在代碼執行前有一個決議的程序,創建了執行背景關系,初始化了一些代碼執行時需要用到的物件,當訪問一個變數時,會到當前執行背景關系中的作用域鏈中去查找,而作用域鏈的首端指向的是當前執行背景關系的變數物件,這個變數物件是執行背景關系的一個屬性,它包含了函式的形參、所有的函式和變數宣告,這個物件的是在代碼決議的時候創建的,
首先要知道,JS在拿到一個變數或者一個函式的時候,會有兩步操作,即決議和執行,
- 在決議階段,JS會檢查語法,并對函式進行預編譯,決議的時候會先創建一個全域執行背景關系環境,先把代碼中即將執行的變數、函式宣告都拿出來,變數先賦值為undefined,函式先宣告好可使用,在一個函式執行之前,也會創建一個函式執行背景關系環境,跟全域執行背景關系類似,不過函式執行背景關系會多出this、arguments和函式的引數,
- 全域背景關系:變數定義,函式宣告
- 函式背景關系:變數定義,函式宣告,this,arguments
- 在執行階段,就是按照代碼的順序依次執行,
那為什么會進行變數提升呢?主要有以下兩個原因:
- 提高性能
- 容錯性更好
(1)提高性能
在JS代碼執行之前,會進行語法檢查和預編譯,并且這一操作只進行一次,這么做就是為了提高性能,如果沒有這一步,那么每次執行代碼前都必須重新決議一遍該變數(函式),而這是沒有必要的,因為變數(函式)的代碼并不會改變,決議一遍就夠了,
在決議的程序中,還會為函式生成預編譯代碼,在預編譯時,會統計宣告了哪些變數、創建了哪些函式,并對函式的代碼進行壓縮,去除注釋、不必要的空白等,這樣做的好處就是每次執行函式時都可以直接為該函式分配堆疊空間(不需要再決議一遍去獲取代碼中宣告了哪些變數,創建了哪些函式),并且因為代碼壓縮的原因,代碼執行也更快了,
(2)容錯性更好
變數提升可以在一定程度上提高JS的容錯性,看下面的代碼:
a = 1; var a; console.log(a);
如果沒有變數提升,這兩行代碼就會報錯,但是因為有了變數提升,這段代碼就可以正常執行,
雖然,在可以開發程序中,可以完全避免這樣寫,但是有時代碼很復雜的時候,可能因為疏忽而先使用后定義了,這樣也不會影響正常使用,由于變數提升的存在,而會正常運行,
總結:
- 決議和預編譯程序中的宣告提升可以提高性能,讓函式可以在執行時預先為變數分配堆疊空間
- 宣告提升還可以提高JS代碼的容錯性,使一些不規范的代碼也可以正常執行
變數提升雖然有一些優點,但是他也會造成一定的問題,在ES6中提出了let、const來定義變數,它們就沒有變數提升的機制,下面看一下變數提升可能會導致的問題:
var tmp = new Date();
function fn(){
console.log(tmp);
if(false){
var tmp = 'hello world';
}
}
fn(); // undefined
在這個函式中,原本是要列印出外層的tmp變數,但是因為變數提升的問題,內層定義的tmp被提到函式內部的最頂部,相當于覆寫了外層的tmp,所以列印結果為undefined,
var tmp = 'hello world';
for (var i = 0; i < tmp.length; i++) {
console.log(tmp[i]);
}
console.log(i); // 11
由于遍歷時定義的i會變數提升成為一個全域變數,在函式結束之后不會被銷毀,所以列印出來11,
18. 什么是尾呼叫,使用尾呼叫有什么好處?
尾呼叫指的是函式的最后一步呼叫另一個函式,代碼執行是基于執行堆疊的,所以當在一個函式里呼叫另一個函式時,會保留當前的執行背景關系,然后再新建另外一個執行背景關系加入堆疊中,使用尾呼叫的話,因為已經是函式的最后一步,所以這時可以不必再保留當前的執行背景關系,從而節省了記憶體,這就是尾呼叫優化,但是 ES6 的尾呼叫優化只在嚴格模式下開啟,正常模式是無效的,
19. ES6模塊與CommonJS模塊有什么異同?
ES6 Module和CommonJS模塊的區別:
- CommonJS是對模塊的淺拷?,ES6 Module是對模塊的引?,即ES6 Module只存只讀,不能改變其值,也就是指標指向不能變,類似const;
- import的接?是read-only(只讀狀態),不能修改其變數值, 即不能修改其變數的指標指向,但可以改變變數內部指標指向,可以對commonJS對重新賦值(改變指標指向),但是對ES6 Module賦值會編譯報錯,
ES6 Module和CommonJS模塊的共同點:
- CommonJS和ES6 Module都可以對引?的物件進?賦值,即對物件內部屬性的值進?改變,
20. 常見的DOM操作有哪些
1)DOM 節點的獲取
DOM 節點的獲取的API及使用:
getElementById // 按照 id 查詢
getElementsByTagName // 按照標簽名查詢
getElementsByClassName // 按照類名查詢
querySelectorAll // 按照 css 選擇器查詢
// 按照 id 查詢
var imooc = document.getElementById('imooc') // 查詢到 id 為 imooc 的元素
// 按照標簽名查詢
var pList = document.getElementsByTagName('p') // 查詢到標簽為 p 的集合
console.log(divList.length)
console.log(divList[0])
// 按照類名查詢
var moocList = document.getElementsByClassName('mooc') // 查詢到類名為 mooc 的集合
// 按照 css 選擇器查詢
var pList = document.querySelectorAll('.mooc') // 查詢到類名為 mooc 的集合
2)DOM 節點的創建
創建一個新節點,并把它添加到指定節點的后面,已知的 HTML 結構如下:
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container">
<h1 id="title">我是標題</h1>
</div>
</body>
</html>
要求添加一個有內容的 span 節點到 id 為 title 的節點后面,做法就是:
// 首先獲取父節點
var container = document.getElementById('container')
// 創建新節點
var targetSpan = document.createElement('span')
// 設定 span 節點的內容
targetSpan.innerHTML = 'hello world'
// 把新創建的元素塞進父節點里去
container.appendChild(targetSpan)
3)DOM 節點的洗掉
洗掉指定的 DOM 節點,已知的 HTML 結構如下
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container">
<h1 id="title">我是標題</h1>
</div>
</body>
</html>
需要洗掉 id 為 title 的元素,做法是:
// 獲取目標元素的父元素
var container = document.getElementById('container')
// 獲取目標元素
var targetNode = document.getElementById('title')
// 洗掉目標元素
container.removeChild(targetNode)
或者通過子節點陣列來完成洗掉:
// 獲取目標元素的父元素
var container = document.getElementById('container')
// 獲取目標元素
var targetNode = container.childNodes[1]
// 洗掉目標元素
container.removeChild(targetNode)
4)修改 DOM 元素
修改 DOM 元素這個動作可以分很多維度,比如說移動 DOM 元素的位置,修改 DOM 元素的屬性等,
將指定的兩個 DOM 元素交換位置,已知的 HTML 結構如下:
<html>
<head>
<title>DEMO</title>
</head>
<body>
<div id="container">
<h1 id="title">我是標題</h1>
<p id="content">我是內容</p>
</div>
</body>
</html>
現在需要調換 title 和 content 的位置,可以考慮 insertBefore 或者 appendChild:
// 獲取父元素
var container = document.getElementById('container')
// 獲取兩個需要被交換的元素
var title = document.getElementById('title')
var content = document.getElementById('content')
// 交換兩個元素,把 content 置于 title 前面
container.insertBefore(content, title)
21. use strict是什么意思 ? 使用它區別是什么?
use strict 是一種 ECMAscript5 添加的(嚴格模式)運行模式,這種模式使得 Javascript 在更嚴格的條件下運行,設立嚴格模式的目的如下:
- 消除 Javascript 語法的不合理、不嚴謹之處,減少怪異行為;
- 消除代碼運行的不安全之處,保證代碼運行的安全;
- 提高編譯器效率,增加運行速度;
- 為未來新版本的 Javascript 做好鋪墊,
區別:
- 禁止使用 with 陳述句,
- 禁止 this 關鍵字指向全域物件,
- 物件不能有重名的屬性,
22. 如何判斷一個物件是否屬于某個類?
- 第一種方式,使用 instanceof 運算子來判斷建構式的 prototype 屬性是否出現在物件的原型鏈中的任何位置,
- 第二種方式,通過物件的 constructor 屬性來判斷,物件的 constructor 屬性指向該物件的建構式,但是這種方式不是很安全,因為 constructor 屬性可以被改寫,
- 第三種方式,如果需要判斷的是某個內置的參考型別的話,可以使用 Object.prototype.toString() 方法來列印物件的[[Class]] 屬性來進行判斷,
23. 強型別語言和弱型別語言的區別
- 強型別語言:強型別語言也稱為強型別定義語言,是一種總是強制型別定義的語言,要求變數的使用要嚴格符合定義,所有變數都必須先定義后使用,Java和C++等語言都是強制型別定義的,也就是說,一旦一個變數被指定了某個資料型別,如果不經過強制轉換,那么它就永遠是這個資料型別了,例如你有一個整數,如果不顯式地進行轉換,你不能將其視為一個字串,
- 弱型別語言:弱型別語言也稱為弱型別定義語言,與強型別定義相反,JavaScript語言就屬于弱型別語言,簡單理解就是一種變數型別可以被忽略的語言,比如JavaScript是弱型別定義的,在JavaScript中就可以將字串'12'和整數3進行連接得到字串'123',在相加的時候會進行強制型別轉換,
兩者對比:強型別語言在速度上可能略遜色于弱型別語言,但是強型別語言帶來的嚴謹性可以有效地幫助避免許多錯誤,
24. 解釋性語言和編譯型語言的區別
(1)解釋型語言
使用專門的解釋器對源程式逐行解釋成特定平臺的機器碼并立即執行,是代碼在執行時才被解釋器一行行動態翻譯和執行,而不是在執行之前就完成翻譯,解釋型語言不需要事先編譯,其直接將源代碼解釋成機器碼并立即執行,所以只要某一平臺提供了相應的解釋器即可運行該程式,其特點總結如下
- 解釋型語言每次運行都需要將源代碼解釋稱機器碼并執行,效率較低;
- 只要平臺提供相應的解釋器,就可以運行源代碼,所以可以方便源程式移植;
- JavaScript、Python等屬于解釋型語言,
(2)編譯型語言
使用專門的編譯器,針對特定的平臺,將高級語言源代碼一次性的編譯成可被該平臺硬體執行的機器碼,并包裝成該平臺所能識別的可執行性程式的格式,在編譯型語言寫的程式執行之前,需要一個專門的編譯程序,把源代碼編譯成機器語言的檔案,如exe格式的檔案,以后要再運行時,直接使用編譯結果即可,如直接運行exe檔案,因為只需編譯一次,以后運行時不需要編譯,所以編譯型語言執行效率高,其特點總結如下:
- 一次性的編譯成平臺相關的機器語言檔案,運行時脫離開發環境,運行效率高;
- 與特定平臺相關,一般無法移植到其他平臺;
- C、C++等屬于編譯型語言,
兩者主要區別在于:前者源程式編譯后即可在該平臺運行,后者是在運行期間才編譯,所以前者運行速度快,后者跨平臺性好,
25. for...in和for...of的區別
for…of 是ES6新增的遍歷方式,允許遍歷一個含有iterator介面的資料結構(陣列、物件等)并且回傳各項的值,和ES3中的for…in的區別如下
- for…of 遍歷獲取的是物件的鍵值,for…in 獲取的是物件的鍵名;
- for… in 會遍歷物件的整個原型鏈,性能非常差不推薦使用,而 for … of 只遍歷當前物件不會遍歷原型鏈;
- 對于陣列的遍歷,for…in 會回傳陣列中所有可列舉的屬性(包括原型鏈上可列舉的屬性),for…of 只回傳陣列的下標對應的屬性值;
總結:for...in 回圈主要是為了遍歷物件而生,不適用于遍歷陣列;for...of 回圈可以用來遍歷陣列、類陣列物件,字串、Set、Map 以及 Generator 物件,
26. 如何使用for...of遍歷物件
for…of是作為ES6新增的遍歷方式,允許遍歷一個含有iterator介面的資料結構(陣列、物件等)并且回傳各項的值,普通的物件用for..of遍歷是會報錯的,
如果需要遍歷的物件是類陣列物件,用Array.from轉成陣列即可,
var obj = {
0:'one',
1:'two',
length: 2
};
obj = Array.from(obj);
for(var k of obj){
console.log(k)
}
如果不是類陣列物件,就給物件添加一個[Symbol.iterator]屬性,并指向一個迭代器即可,
//方法一:
var obj = {
a:1,
b:2,
c:3
};
obj[Symbol.iterator] = function(){
var keys = Object.keys(this);
var count = 0;
return {
next(){
if(count<keys.length){
return {value: obj[keys[count++]],done:false};
}else{
return {value:undefined,done:true};
}
}
}
};
for(var k of obj){
console.log(k);
}
// 方法二
var obj = {
a:1,
b:2,
c:3
};
obj[Symbol.iterator] = function*(){
var keys = Object.keys(obj);
for(var k of keys){
yield [k,obj[k]]
}
};
for(var [k,v] of obj){
console.log(k,v);
}
27. ajax、axios、fetch的區別
(1)AJAX
Ajax 即“AsynchronousJavascriptAndXML”(異步 JavaScript 和 XML),是指一種創建互動式網頁應用的網頁開發技術,它是一種在無需重新加載整個網頁的情況下,能夠更新部分網頁的技術,通過在后臺與服務器進行少量資料交換,Ajax 可以使網頁實作異步更新,這意味著可以在不重新加載整個網頁的情況下,對網頁的某部分進行更新,傳統的網頁(不使用 Ajax)如果需要更新內容,必須多載整個網頁頁面,其缺點如下:
- 本身是針對MVC編程,不符合前端MVVM的浪潮
- 基于原生XHR開發,XHR本身的架構不清晰
- 不符合關注分離(Separation of Concerns)的原則
- 配置和呼叫方式非常混亂,而且基于事件的異步模型不友好,
(2)Fetch
fetch號稱是AJAX的替代品,是在ES6出現的,使用了ES6中的promise物件,Fetch是基于promise設計的,Fetch的代碼結構比起ajax簡單多,fetch不是ajax的進一步封裝,而是原生js,沒有使用XMLHttpRequest物件,
fetch的優點:
- 語法簡潔,更加語意化
- 基于標準 Promise 實作,支持 async/await
- 更加底層,提供的API豐富(request, response)
- 脫離了XHR,是ES規范里新的實作方式
fetch的缺點:
- fetch只對網路請求報錯,對400,500都當做成功的請求,服務器回傳 400,500 錯誤碼時并不會 reject,只有網路錯誤這些導致請求不能完成時,fetch 才會被 reject,
- fetch默認不會帶cookie,需要添加配置項: fetch(url, {credentials: 'include'})
- fetch不支持abort,不支持超時控制,使用setTimeout及Promise.reject的實作的超時控制并不能阻止請求程序繼續在后臺運行,造成了流量的浪費
- fetch沒有辦法原生監測請求的進度,而XHR可以
(3)Axios
Axios 是一種基于Promise封裝的HTTP客戶端,其特點如下:
- 瀏覽器端發起XMLHttpRequests請求
- node端發起http請求
- 支持Promise API
- 監聽請求和回傳
- 對請求和回傳進行轉化
- 取消請求
- 自動轉換json資料
- 客戶端支持抵御XSRF攻擊
28. 陣列的遍歷方法有哪些
|
方法 |
是否改變原陣列 |
特點 |
|
forEach() |
否 |
陣列方法,不改變原陣列,沒有回傳值 |
|
map() |
否 |
陣列方法,不改變原陣列,有回傳值,可鏈式呼叫 |
|
filter() |
否 |
陣列方法,過濾陣列,回傳包含符合條件的元素的陣列,可鏈式呼叫 |
|
for...of |
否 |
for...of遍歷具有Iterator迭代器的物件的屬性,回傳的是陣列的元素、物件的屬性值,不能遍歷普通的obj物件,將異步回圈變成同步回圈 |
|
every() 和 some() |
否 |
陣列方法,some()只要有一個是true,便回傳true;而every()只要有一個是false,便回傳false. |
|
find() 和 findIndex() |
否 |
陣列方法,find()回傳的是第一個符合條件的值;findIndex()回傳的是第一個回傳條件的值的索引值 |
|
reduce() 和 reduceRight() |
否 |
陣列方法,reduce()對陣列正序操作;reduceRight()對陣列逆序操作 |
29. forEach和map方法有什么區別
這方法都是用來遍歷陣列的,兩者區別如下:
- forEach()方法會針對每一個元素執行提供的函式,對資料的操作會改變原陣列,該方法沒有回傳值;
- map()方法不會改變原陣列的值,回傳一個新陣列,新陣列中的值為原陣列呼叫函式處理之后的值;
30. addEventListener()方法的引數和使用
EventTarget.addEventListener() 方法將指定的監聽器注冊到 EventTarget 上,當該物件觸發指定的事件時,指定的回呼函式就會被執行, 事件目標可以是一個檔案上的元素 Element,Document和Window或者任何其他支持事件的物件,
addEventListener()的作業原理是將實作EventListener的函式或物件添加到呼叫它的EventTarget上的指定事件型別的事件偵聽器串列中,
它的使用語法如下:
target.addEventListener(type, listener, options); target.addEventListener(type, listener, useCapture); target.addEventListener(type, listener, useCapture, wantsUntrusted);
其中引數如下:
(1)type
表示監聽事件型別的字串,
(2)listener
當所監聽的事件型別觸發時,會接收到一個事件通知(實作了 Event 介面的物件)物件,listener 必須是一個實作了 EventListener 介面的物件,或者是一個函式,
(3)options 可選
一個指定有關 listener 屬性的可選引數物件,可用的選項如下:
- capture: Boolean,表示 listener 會在該型別的事件捕獲階段傳播到該 EventTarget 時觸發,
- once: Boolean,表示 listener 在添加之后最多只呼叫一次,如果是 true, listener 會在其被呼叫之后自動移除,
- passive: Boolean,設定為true時,表示 listener 永遠不會呼叫 preventDefault(),如果 listener 仍然呼叫了這個函式,客戶端將會忽略它并拋出一個控制臺警告,
- signal:AbortSignal,該 AbortSignal 的 abort() 方法被呼叫時,監聽器會被移除,
(4)useCapture可選
Boolean,在DOM樹中,注冊了listener的元素, 是否要先于它下面的EventTarget,呼叫該listener, 當useCapture(設為true) 時,沿著DOM樹向上冒泡的事件,不會觸發listener,當一個元素嵌套了另一個元素,并且兩個元素都對同一事件注冊了一個處理函式時,所發生的事件冒泡和事件捕獲是兩種不同的事件傳播方式,事件傳播模式決定了元素以哪個順序接收事件,如果沒有指定, useCapture 默認為 false ,
(5)wantsUntrusted
如果為 true , 則事件處理程式會接收網頁自定義的事件,此引數只適用于 Gecko(chrome的默認值為true,其他常規網頁的默認值為false),主要用于附加組件的代碼和瀏覽器本身,
如果對您有所幫助,歡迎您點個關注,我會定時更新技術檔案,大家一起討論學習,一起進步,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/461875.html
標籤:JavaScript
上一篇:使用iframe/object/embed引入svg 使用getSVGDocument()為null(可能是兩個問題)