我有兩個如下資料框,
import numpy as np
import pandas as pd
df1 = pd.DataFrame({1: np.zeros(5), 2: np.zeros(5)}, index=['a','b','c','d','e'])
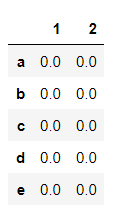
和
df2 = pd.DataFrame({'category': [1,1,2,2], 'value':[85,46, 39, 22]}, index=[0, 1, 3, 4])
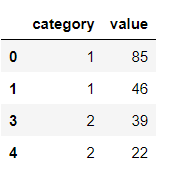
需要在第value一個資料幀中分配第二個資料幀,以便保持索引和列的關系。第二個資料框索引iloc基于并具有category實際上包含第一個資料框的列名的列。value要分配的值。
以下是我的預期輸出解決方案,
for _category in df2['category'].unique():
df1.loc[df1.iloc[df2[df2['category'] == _category].index.tolist()].index, _category] = df2[df2['category'] == _category]['value'].values
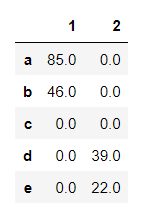
如果沒有 for 回圈,是否有一種 Pythonic 方式?
uj5u.com熱心網友回復:
一種選擇是pivot和update:
df3 = df1.reset_index()
df3.update(df2.pivot(columns='category', values='value'))
df3 = df3.set_index('index').rename_axis(None)
或者,重新索引 df2(分兩步,數字和標簽),并combine_first使用 df1:
df3 = (df2
.pivot(columns='category', values='value')
.reindex(range(max(df2.index) 1))
.set_axis(df1.index)
.combine_first(df1)
)
輸出:
1 2
a 85.0 0.0
b 46.0 0.0
c 0.0 0.0
d 0.0 39.0
e 0.0 22.0
uj5u.com熱心網友回復:
df1這是用 NaN替換 0 的一種方法;使用以下命令pivot填充df2和填充 NaN :df1df2
out = (df1.replace(0, pd.NA).reset_index()
.fillna(df2.pivot(columns='category', values='value'))
.set_index('index').rename_axis(None).fillna(0))
輸出:
1 2
a 85.0 0.0
b 46.0 0.0
c 0.0 0.0
d 0.0 39.0
e 0.0 22.0
轉載請註明出處,本文鏈接:https://www.uj5u.com/qiye/467771.html